CareGPT
1.0.0
중국어 |
비디오 튜토리얼 설치 및 배포 온라인 경험

⚡특징:
conda create - n llm python = 3.11
conda activate llm
python - m pip install - r requirements . txt # 转为HF格式
python - m transformers . models . llama . convert_llama_weights_to_hf
- - input_dir path_to_llama_weights - - model_size 7 B - - output_dir path_to_llama_model 사용자 지정 데이터세트를 사용하는 경우 다음 형식으로 dataset_info.json 파일에 데이터세트 정의를 제공해야 합니다.
"数据集名称" : {
"hf_hub_url" : " HuggingFace上的项目地址(若指定,则忽略下列三个参数) " ,
"script_url" : "包含数据加载脚本的本地文件夹名称(若指定,则忽略下列两个参数) " ,
"file_name" : "该目录下数据集文件的名称(若上述参数未指定,则此项必需) " ,
"file_sha1" : "数据集文件的SHA-1哈希值(可选) " ,
"columns" : {
"prompt" : "数据集代表提示词的表头名称(默认:instruction) " ,
"query" : "数据集代表请求的表头名称(默认:input) " ,
"response" : "数据集代表回答的表头名称(默认:output) " ,
"history" : "数据集代表历史对话的表头名称(默认:None) "
}
} prompt 및 response 열은 비어 있지 않은 문자열이어야 합니다. query 열의 내용은 모델 입력으로 prompt 열과 연결됩니다. history 열은 목록이어야 하며, 여기서 각 요소는 각각 사용자 요청과 모델 응답을 나타내는 문자열 튜플입니다.
.txt 형식, 한 줄에 하나의 비지도 데이터.
Machine learning (ML) is a field devoted to understanding and building methods that let machines "learn" – that is, methods that leverage data to improve computer performance on some set of tasks.
Machine learning algorithms build a model based on sample data, known as training data, in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, agriculture, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks.[
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : [
[ "你好,你能帮我解答一个问题吗? " , "当然,请问有什么问题? " ],
[ "我想了解人工智能的未来发展方向,你有什么想法吗? " , "人工智能在未来的发展方向可能包括更强大的机器学习算法,更先进的自然语言处理技术,以及更加智能的机器人。 " ]
]
}
][
{
"instruction" : "听起来很不错。人工智能可能在哪些方面面临挑战呢? " ,
"input" : " " ,
"output" : "人工智能面临的挑战包括数据隐私、安全和道德方面的问题,以及影响就业机会的自动化等问题。 " ,
"history" : []
}
][
{
"instruction" : "生成三个与“道歉”意思相同的动词" ,
"input" : " " ,
"output" : [
"承认,表示遗憾,弥补。 " ,
"道歉"
]
}
] 그래픽 카드가 NVLINK에 연결되어 있는지 확인하세요. NVLINK 연결을 통해서만 병렬 가속 훈련에 accelerate 효과적으로 사용할 수 있습니다.
nvidia-smi topo -m
accelerate config # configure the environment
accelerate launch src / train_bash . py # arguments (same as above) # LLaMA-2
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset mm
- - finetuning_type lora
- - quantization_bit 4
- - overwrite_cache
- - output_dir output
- - per_device_train_batch_size 8
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template llama2
- - lora_target q_proj , v_proj
# LLaMA
accelerate launch src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_train
- - dataset mm , hm
- - finetuning_type lora
- - overwrite_cache
- - output_dir output - 1
- - per_device_train_batch_size 4
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 2000
- - learning_rate 5e-5
- - num_train_epochs 2.0
- - plot_loss
- - fp16
- - template default
- - lora_target q_proj , v_proj # LLaMA-2, DPO
accelerate launch src / train_bash . py
- - stage dpo
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_train
- - dataset rlhf
- - template llama2
- - finetuning_type lora
- - quantization_bit 4
- - lora_target q_proj , v_proj
- - resume_lora_training False
- - checkpoint_dir . / output - 2
- - output_dir output - dpo
- - per_device_train_batch_size 2
- - gradient_accumulation_steps 4
- - lr_scheduler_type cosine
- - logging_steps 10
- - save_steps 1000
- - learning_rate 1e-5
- - num_train_epochs 1.0
- - plot_loss
- - fp16 # LLaMA-2
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / web_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / web_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2테스트 API:
curl - X 'POST'
'http://127.0.0.1:8888/v1/chat/completions'
- H 'accept: application/json'
- H 'Content-Type: application/json'
- d ' {
"model" : "string",
"messages": [
{
"role" : "user",
"content": "你好"
}
],
" temperature ": 0 ,
"top_p" : 0 ,
"max_new_tokens" : 0 ,
"stream" : false
}' # LLaMA-2
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / cli_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default
# DPO
python src / cli_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output - dpo
- - finetuning_type lora
- - template llama2 # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_predict
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_predict
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir predict_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate # LLaMA-2
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - do_eval
- - dataset mm
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate
# LLaMA
CUDA_VISIBLE_DEVICES = 0 python src / train_bash . py
- - stage sft
- - model_name_or_path . / Llama - 7 b - hf
- - do_eval
- - dataset mm
- - template default
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir eval_output
- - per_device_eval_batch_size 8
- - max_samples 100
- - predict_with_generate 4/8비트 평가의 경우 --per_device_eval_batch_size=1 및 --max_target_length 128 사용하는 것이 좋습니다.
# LLaMA-2
python src / export_model . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - template llama2
- - finetuning_type lora
- - checkpoint_dir output - 1
- - output_dir output_export
# LLaMA
python src / export_model . py
- - model_name_or_path . / Llama - 7 b - hf
- - template default
- - finetuning_type lora
- - checkpoint_dir output
- - output_dir output_export % cd Gradio
python app . py 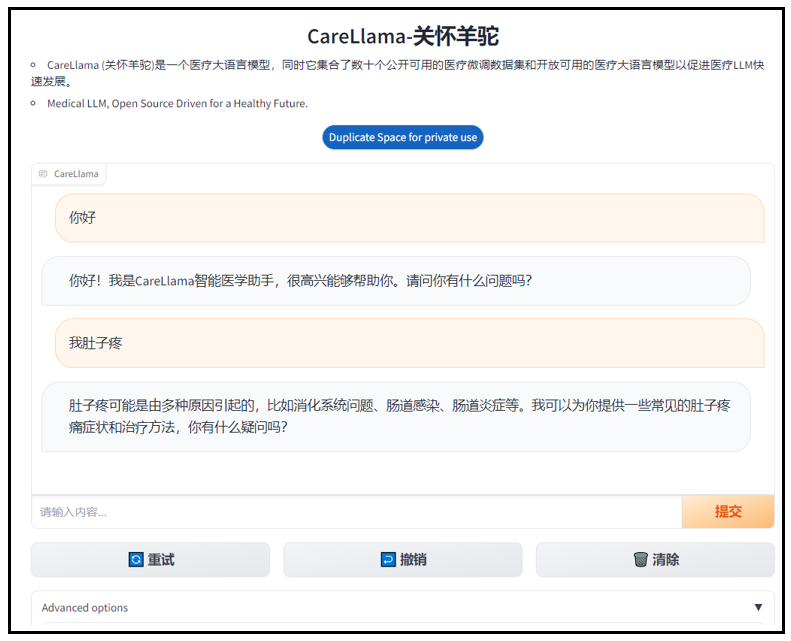
# LLaMA-2
python src / api_demo . py
- - model_name_or_path . / Llama - 2 - 7 b - chat - hf
- - checkpoint_dir output
- - finetuning_type lora
- - template llama2
# LLaMA
python src / api_demo . py
- - model_name_or_path . / Llama - 7 b - hf
- - checkpoint_dir output - 1
- - finetuning_type lora
- - template default设置열고接口地址http://127.0.0.1:8000/ (즉, API 인터페이스 주소)으로 수정한 다음 사용할 수 있습니다. 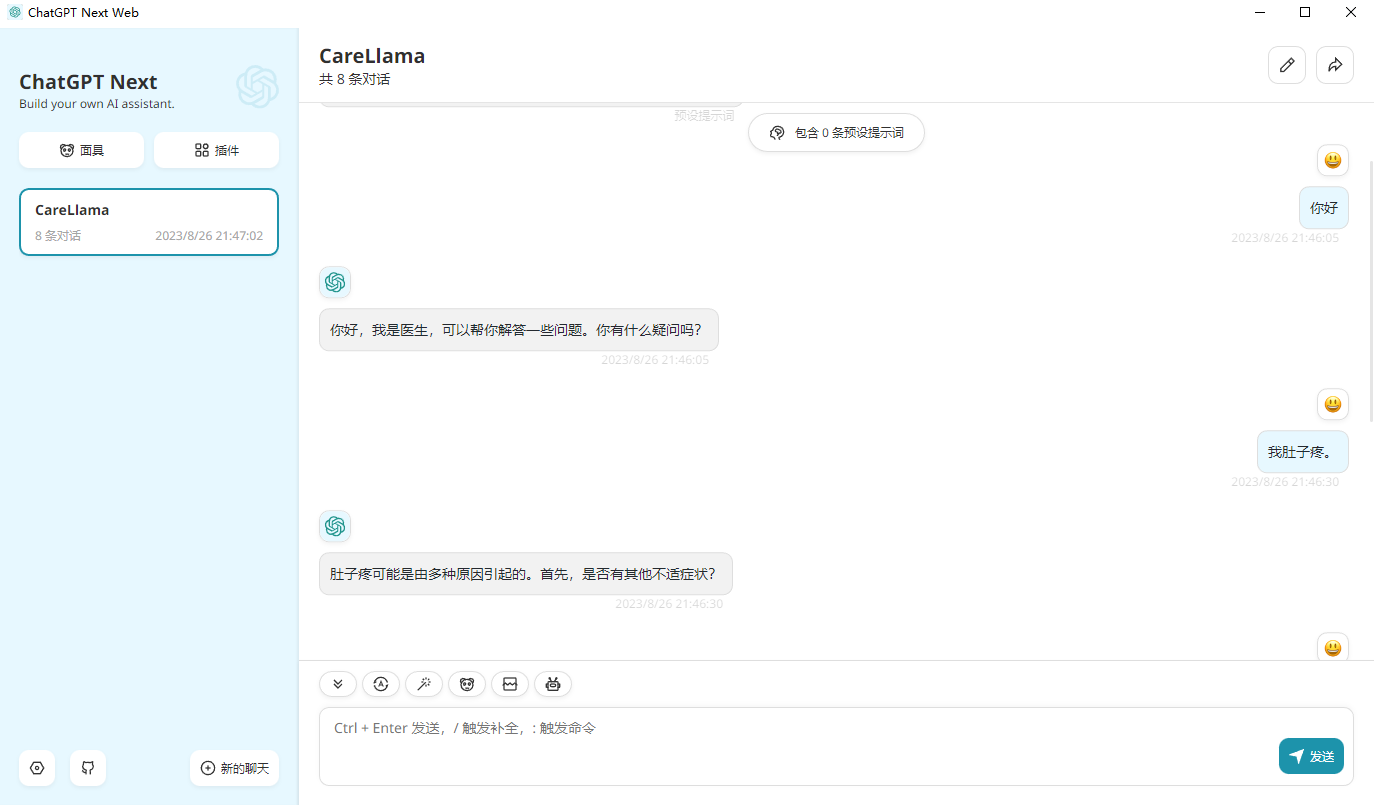
PubMed Central 및 PubMed Abstracts 포함한 다양한 의학 텍스트가 포함된 PILE 코퍼스를 사용하여 학습되었습니다. 이러한 귀중한 텍스트는 BLOOMZ 모델의 의학 지식 시스템을 크게 풍부하게 하였으므로 많은 오픈 소스 프로젝트에서 BLOOMZ를 의료 미세 조정의 기본 모델로 우선시할 것입니다.质量> 数量진실입니다. Qingyuan&& Caspian에 넘겨짐 | 미니GPT-4! , 매우 큰 규모의 SFT 데이터는 다운스트림 작업 LLM을 약화시키거나 ICL, CoT 및 기타 기능을 잃게 됩니다.大规模预训练+小规模监督微调=超强的LLM模型.英文10B以下选择Mistral-7B中文10B以下选择Yi-6B 10B以上选择Qwen-14B和Yi-34B ; 중요한
누구나 ISSUE에 새로운 경험을 추가할 수 있습니다!
11~13 방법론은 130억 개의 대규모 언어 모델에서 나옵니다. 가중치 하나만 변경하면 언어 능력이 완전히 상실됩니다! 푸단대학교 자연어처리연구소의 최신 연구입니다.
14대형 언어 모델의 능력이 감독된 미세 조정 데이터 구성에 의해 어떻게 영향을 받는지에 대한 방법론
17~25 방법론은 LLM Optimization: Layer-wise Optimal Rank Adaptation (LORA) 중국어 버전 해석에서 따옴
| 단계 | 가중치 소개 | 주소 다운로드 | 특징 | 기본 모델 | 미세 조정 방법 | 데이터 세트 |
|---|---|---|---|---|---|---|
| ?감독 및 미세 조정 | 다중 회전 대화 데이터는 LLaMA2-7b-Chat을 기반으로 학습됩니다. | CareLlama2-7b-채팅-sft-멀티、?CareLlama2-7b-멀티 | 뛰어난 다단계 대화 능력 | LLaMA2-7b-채팅 | QLoRA | mm |
| 미세 조정 감독 | 풍부하고 효율적인 의사-환자 대화 데이터는 LLaMA2-7b-Chat을 기반으로 훈련됩니다. | CareLlama2-7b-채팅-sft-med | 우수한 환자 질병 진단 능력 | LLaMA2-7b-채팅 | QLoRA | 흠 |
| 감독하다 |


