DiGIT
1.0.0
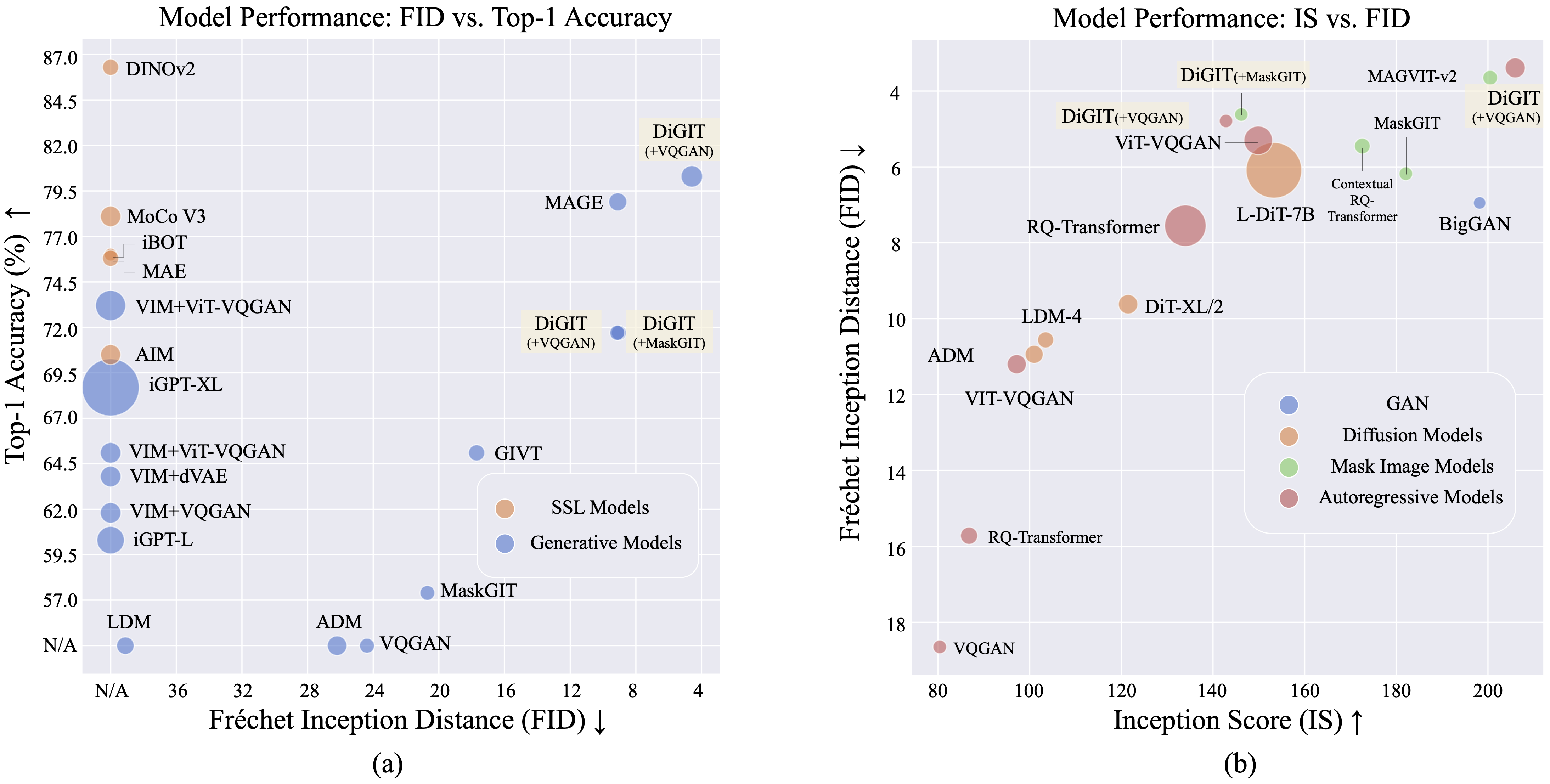
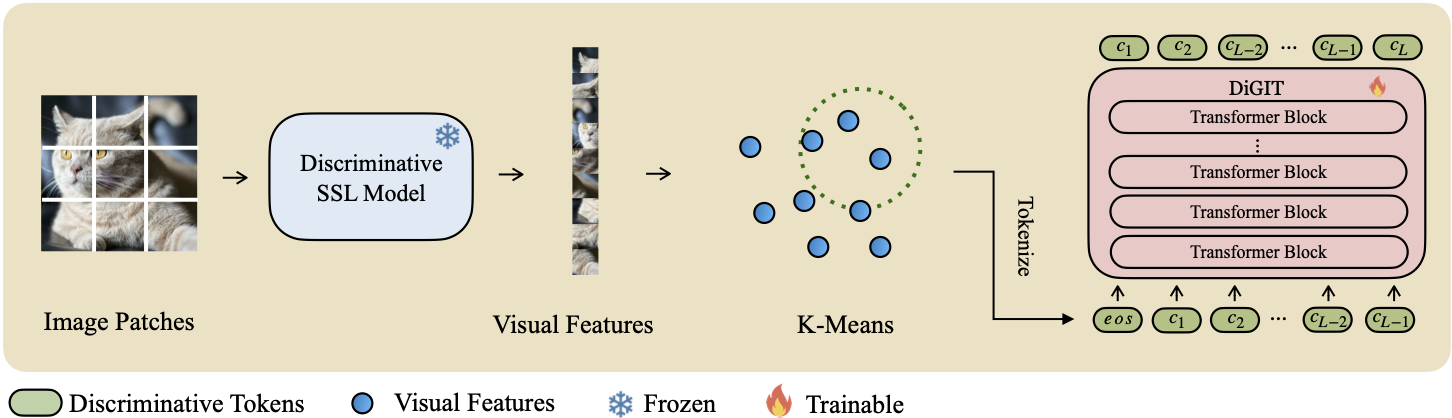
우리는 자기 지도 학습(SSL) 모델에서 파생된 추상 잠재 공간에서 다음 토큰 예측을 수행하는 자동 회귀 생성 모델인 DiGIT를 제시합니다. DINOv2 모델의 숨겨진 상태에 K-Means 클러스터링을 사용하여 새로운 이산 토크나이저를 효과적으로 생성합니다. 이 방법은 ImageNet 데이터 세트의 이미지 생성 성능을 크게 향상시켜 클래스 무조건 작업의 경우 FID 점수 4.59 , 클래스 조건 작업의 경우 3.39를 달성합니다. 또한 이 모델은 이미지 이해를 향상시켜 80.3의 선형 프로브 정확도를 달성합니다.
| 행동 양식 | # 토큰 | 특징 | # 매개변수 | 상위 1개 Acc. |
|---|---|---|---|---|
| iGPT-L | 32 | 1536년 | 1362M | 60.3 |
| iGPT-XL | 64 | 3072 | 6801M | 68.7 |
| VIM+VQGAN | 32 | 1024 | 650M | 61.8 |
| VIM+dVAE | 32 | 1024 | 650M | 63.8 |
| VIM+ViT-VQGAN | 32 | 1024 | 650M | 65.1 |
| VIM+ViT-VQGAN | 32 | 2048년 | 1697M | 73.2 |
| 목표 | 16 | 1536년 | 0.6B | 70.5 |
| DiGIT (우리) | 16 | 1024 | 219M | 71.7 |
| DiGIT (우리) | 16 | 1536년 | 732M | 80.3 |
| 유형 | 행동 양식 | # 매개변수 | # 에포크 | 버팀대 | 이다 |
|---|---|---|---|---|---|
| 간 | 빅GAN | 70M | - | 38.6 | 24.70 |
| 차이점 | LDM | 395M | - | 39.1 | 22.83 |
| 차이점 | ADM | 554M | - | 26.2 | 39.70 |
| 밈 | 마술사 | 2억 | 1600 | 11.1 | 81.17 |
| 밈 | 마술사 | 463M | 1600 | 9.10 | 105.1 |
| 밈 | 마스크GIT | 227M | 300 | 20.7 | 42.08 |
| 밈 | DiGIT(+마스크GIT) | 219M | 200 | 9.04 | 75.04 |
| 아칸소 | VQGAN | 214M | 200 | 24.38 | 30.93 |
| 아칸소 | DiGIT(+VQGAN) | 219M | 400 | 9.13 | 73.85 |
| 아칸소 | DiGIT(+VQGAN) | 732M | 200 | 4.59 | 141.29 |
| 유형 | 행동 양식 | # 매개변수 | # 에포크 | 버팀대 | 이다 |
|---|---|---|---|---|---|
| 간 | 빅GAN | 160M | - | 6.95 | 198.2 |
| 차이점 | ADM | 554M | - | 10.94 | 101.0 |
| 차이점 | LDM-4 | 400M | - | 10.56 | 103.5 |
| 차이점 | DiT-XL/2 | 675M | - | 9.62 | 121.50 |
| 차이점 | L-DiT-7B | 7B | - | 6.09 | 153.32 |
| 밈 | CQR-트랜스 | 371M | 300 | 5.45 | 172.6 |
| MIM+AR | VAR | 310M | 200 | 4.64 | - |
| MIM+AR | VAR | 310M | 200 | 3.60* | 257.5* |
| MIM+AR | VAR | 600M | 250 | 2.95* | 306.1* |
| 밈 | MAGVIT-v2 | 307M | 1080 | 3.65 | 200.5 |
| 아칸소 | VQVAE-2 | 13.5B | - | 11.31 | 45 |
| 아칸소 | RQ-트랜스 | 480M | - | 15.72 | 86.8 |
| 아칸소 | RQ-트랜스 | 3.8B | - | 7.55 | 134.0 |
| 아칸소 | ViTVQGAN | 650M | 360 | 11.20 | 97.2 |
| 아칸소 | ViTVQGAN | 1.7B | 360 | 5.3 | 149.9 |
| 밈 | 마스크GIT | 227M | 300 | 6.18 | 182.1 |
| 밈 | DiGIT(+마스크GIT) | 219M | 200 | 4.62 | 146.19 |
| 아칸소 | VQGAN | 227M | 300 | 18.65 | 80.4 |
| 아칸소 | DiGIT(+VQGAN) | 219M | 400 | 4.79 | 142.87 |
| 아칸소 | DiGIT(+VQGAN) | 732M | 200 | 3.39 | 205.96 |
*: VAR은 분류 없는 지침으로 훈련되지만 다른 모든 모델은 그렇지 않습니다.
K-Means npy 파일 및 모델 체크포인트는 다음에서 다운로드할 수 있습니다.
| 모델 | 링크 |
|---|---|
| HF 무게? | 포옹하는 얼굴 |
기본 모델의 경우 DINOv2-base를 사용하고 대형 모델의 경우 DINOv2-large를 사용합니다. 우리가 사용하는 VQGAN은 MAGE와 동일합니다.
DiGIT
└── data/
├── ILSVRC2012
├── dinov2_base_short_224_l3
├── km_8k.npy
├── dinov2_large_short_224_l3
├── km_16k.npy
└── outputs/
├── base_8k_stage1
├── ...
└── models/
├── vqgan_jax_strongaug.ckpt
├── dinov2_vitb14_reg4_pretrain.pth
├── dinov2_vitl14_reg4_pretrain.pth
git clone https://github.com/DAMO-NLP-SG/DiGIT.git
cd DiGITpip install fairseq 통해 fairseq 설치하세요. ImageNet 데이터세트를 다운로드하여 데이터세트 디렉토리 $PATH_TO_YOUR_WORKSPACE/dataset/ILSVRC2012 에 배치합니다.
SSL 기능을 추출하여 .npy 파일로 저장합니다. K-Means 알고리즘을 faiss와 함께 사용하여 중심을 계산합니다. Huggingface에서 사전 훈련된 중심을 활용할 수도 있습니다.
bash preprocess/run.sh1단계
차별적 토크나이저를 사용하여 GPT 모델을 학습합니다. scripts/train_stage1_ar.sh 에서 훈련 스크립트를 찾을 수 있으며 하이퍼 매개변수는 config/stage1/dino_base.yaml 에 있습니다. 클래스 조건부 생성 구성은 scripts/train_stage1_classcond.sh 참조하세요.
2단계
식별 토큰에 따라 픽셀 디코더(AR 모델 또는 NAR 모델)를 훈련합니다. scripts/train_stage2_ar.sh 에서 자동회귀 훈련 스크립트를 찾을 수 있고 scripts/train_stage2_nar.sh 에서 NAR 훈련 스크립트를 찾을 수 있습니다.
체크포인트를 저장하기 위해 outputs/EXP_NAME/checkpoints 라는 폴더가 생성됩니다. TensorBoard 로그 파일은 outputs/EXP_NAME/tb 에 저장됩니다. 로그는 outputs/EXP_NAME/train.log 에 기록됩니다.
tensorboard --logdir=outputs/EXP_NAME/tb 사용하여 학습 프로세스를 모니터링할 수 있습니다.
scripts/infer_stage1_ar.sh 사용하여 첫 번째 식별 토큰을 샘플링합니다. 기본 모델 크기의 경우 topk=200으로 설정하고, 큰 모델 크기의 경우 topk=400을 사용하는 것이 좋습니다.
그런 다음 scripts/infer_stage2_ar.sh 실행하여 이전에 샘플링된 식별 토큰을 기반으로 VQ 토큰을 샘플링합니다.
생성된 토큰과 합성 이미지는 outputs/EXP_NAME/results 라는 디렉터리에 저장됩니다.
FID 평가를 위한 ImageNet 검증 세트 준비:
python prepare_imgnet_val.py --data_path $PATH_TO_YOUR_WORKSPACE /dataset/ILSVRC2012 --output_dir imagenet-val pip install torch-fidelity 실행하여 평가 도구를 설치합니다.
FID를 평가하려면 다음 명령을 실행하십시오.
python fairseq_user/eval_fid.py --results-path $IMG_SAVE_DIR --subset $GEN_SUBSETbash scripts/train_stage1_linearprobe.sh이 프로젝트는 MIT 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 LICENSE 파일을 참조하세요.
우리 프로젝트가 유용하다고 생각하시면 저장소에 별표를 표시하고 다음과 같이 우리 작업을 인용해 주시기 바랍니다.
@misc { zhu2024stabilize ,
title = { Stabilize the Latent Space for Image Autoregressive Modeling: A Unified Perspective } ,
author = { Yongxin Zhu and Bocheng Li and Hang Zhang and Xin Li and Linli Xu and Lidong Bing } ,
year = { 2024 } ,
eprint = { 2410.12490 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

