PatrickStar
v0.4.6

CHANGE_LOG.md를 참조하세요.
PTM(사전 훈련된 모델)은 NLP 연구와 산업 적용 모두에서 핫스팟이 되고 있습니다. 그러나 PTM 교육에는 엄청난 하드웨어 리소스가 필요하므로 AI 커뮤니티의 소수의 사람들만 액세스할 수 있습니다. 이제 PatrickStar는 모든 사람이 PTM 교육을 이용할 수 있도록 할 것입니다!
메모리 부족 오류(OOM)는 PTM을 교육하는 모든 엔지니어의 악몽입니다. 이러한 오류를 방지하기 위해 모델 매개변수를 저장하기 위해 더 많은 GPU를 도입해야 하는 경우가 많습니다. PatrickStar는 이러한 문제에 대한 더 나은 솔루션을 제공합니다. 이종 훈련 (DeepSpeed Zero Stage 3에서도 사용됨)을 통해 PatrickStar는 CPU와 GPU 메모리를 모두 완전히 사용할 수 있으므로 더 적은 수의 GPU를 사용하여 더 큰 모델을 훈련할 수 있습니다.
패트릭의 생각은 이렇습니다. 비모델 데이터(주로 활성화)는 훈련 중에 다양하지만 현재의 이기종 훈련 솔루션은 모델 데이터를 CPU와 GPU에 정적으로 분할하고 있습니다. GPU를 더 잘 사용하기 위해 PatrickStar는 청크 기반 메모리 관리 모듈을 사용하여 동적 메모리 스케줄링을 제안합니다. PatrickStar의 메모리 관리는 GPU를 절약하기 위해 모델의 현재 컴퓨팅 부분을 제외한 모든 것을 CPU로 오프로드하는 것을 지원합니다. 또한, 청크 기반 메모리 관리는 여러 GPU로 확장할 때 집단 통신에 효율적입니다. PatrickStar의 아이디어에 대해서는 논문과 이 문서를 참조하세요.
실험에서 Patrickstar v0.4.3은 네트워크 토폴로지가 다음과 같은 WeChat 데이터 센터 노드에서 8xTesla V100 GPU 및 240GB GPU 메모리를 사용하여 18B (18B) 매개변수 모델을 훈련할 수 있습니다. PatrickStar는 DeepSpeed보다 두 배 이상 큽니다. 그리고 PatrickStar의 성능은 같은 크기의 모델에서도 더 좋습니다. pstar는 PatrickStar v0.4.3입니다. 깊은 부분은 기본적으로 활성화 최적화가 열리는 공식 예제 DeepSpeed 예제 zero3 단계를 사용하여 DeepSpeed v0.4.3의 성능을 나타냅니다.

또한 A100 SuperPod의 단일 노드에서 PatrickStar v0.4.3을 평가했습니다. DeepSpeed v0.5.7보다 6배 이상 큰 1TB CPU 메모리를 갖춘 8xA100에서 68B 모델을 훈련할 수 있습니다. 모델 규모 외에도 PatrickStar는 DeepSpeed보다 훨씬 더 효율적입니다. 벤치마크 스크립트는 여기에 있습니다.

WeChat AI 데이터 센터 및 NVIDIA SuperPod에 대한 자세한 벤치마크 결과는 이 Google 문서에 게시되어 있습니다.
PatrickStar를 SuperPod의 여러 머신(노드)으로 확장하세요. 32 GPU에서 GPT3-175B 훈련에 성공했습니다. 우리가 아는 한, 이렇게 작은 GPU 클러스터에서 GPT3를 실행하는 것은 최초의 작업입니다. Microsoft는 GPT3과 관련하여 10,000개의 V100을 사용했습니다. 이제 32 A100 GPU에서 미세 조정하거나 사전 훈련할 수도 있습니다. 놀랍습니다!

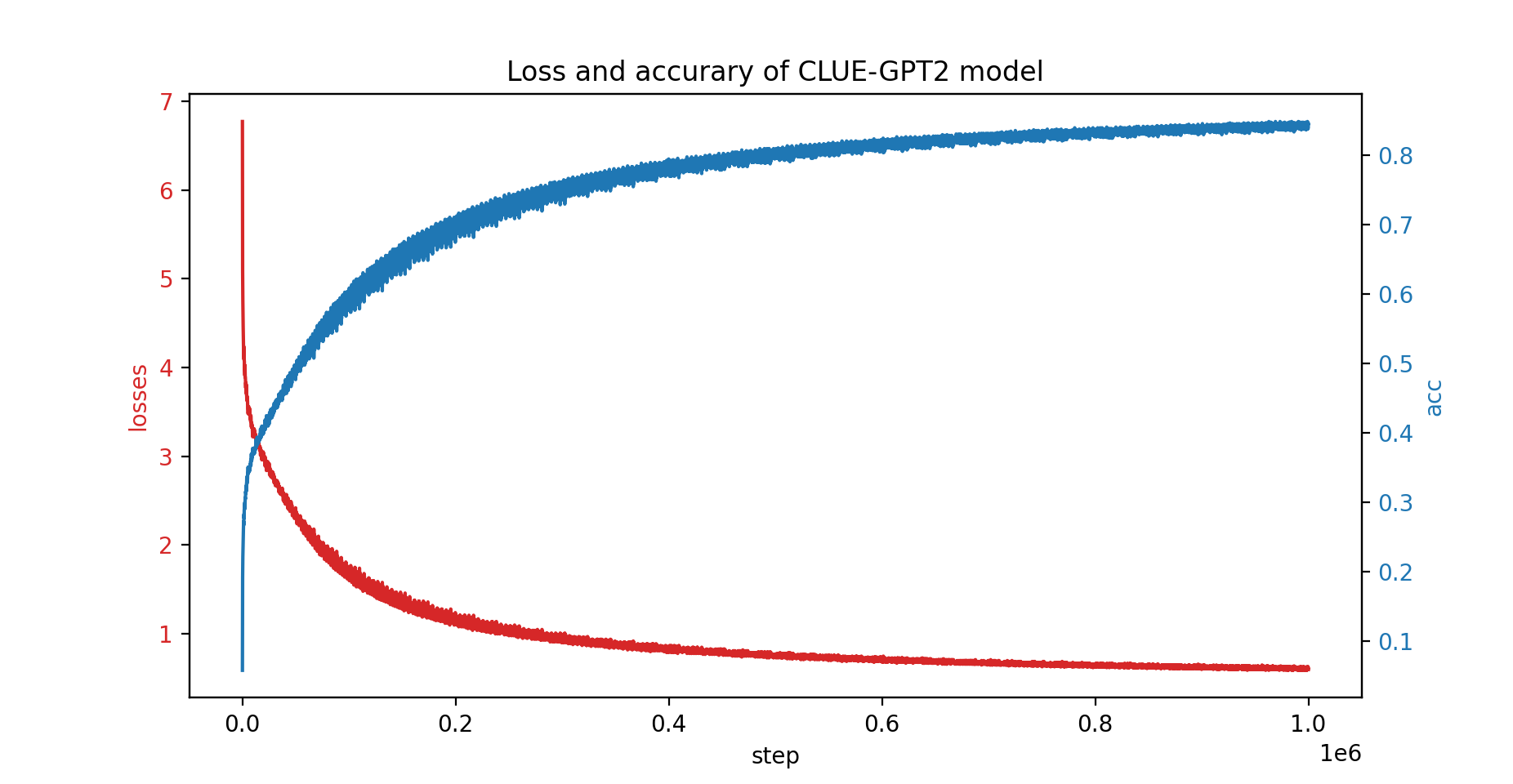
또한 PatrickStar를 사용하여 CLUE-GPT2 모델을 교육했으며 손실 및 정확도 곡선은 아래와 같습니다.
pip install .PatrickStar에는 버전 7 이상의 gcc가 필요합니다. NVIDIA NGC 이미지를 사용할 수도 있습니다. 다음 이미지가 테스트되었습니다.
docker pull nvcr.io/nvidia/pytorch:21.06-py3PatrickStar는 PyTorch를 기반으로 하므로 PyTorch 프로젝트를 쉽게 마이그레이션할 수 있습니다. 다음은 PatrickStar의 예입니다.
from patrickstar . runtime import initialize_engine
config = {
"optimizer" : {
"type" : "Adam" ,
"params" : {
"lr" : 0.001 ,
"betas" : ( 0.9 , 0.999 ),
"eps" : 1e-6 ,
"weight_decay" : 0 ,
"use_hybrid_adam" : True ,
},
},
"fp16" : { # loss scaler params
"enabled" : True ,
"loss_scale" : 0 ,
"initial_scale_power" : 2 ** 3 ,
"loss_scale_window" : 1000 ,
"hysteresis" : 2 ,
"min_loss_scale" : 1 ,
},
"default_chunk_size" : 64 * 1024 * 1024 ,
"release_after_init" : True ,
"use_cpu_embedding" : False ,
"client" : {
"mem_tracer" : {
"use_async_mem_monitor" : args . with_async_mem_monitor ,
}
},
}
def model_func ():
# MyModel is a derived class for torch.nn.Module
return MyModel (...)
model , optimizer = initialize_engine ( model_func = model_func , local_rank = 0 , config = config )
...
for data in dataloader :
optimizer . zero_grad ()
loss = model ( data )
model . backward ( loss )
optimizer . step () 우리는 주로 옵티마이저, 손실 스케일러 및 일부 PatrickStar 관련 구성의 매개변수를 포함하는 DeepSpeed 구성 JSON과 동일한 config 형식을 사용합니다.
위 예시에 대한 자세한 설명은 여기 가이드를 확인해주세요.
더 많은 예시를 보려면 여기를 확인하세요.
빠른 시작 벤치마크 스크립트는 여기에 있습니다. 무작위로 생성된 데이터로 실행됩니다. 따라서 실제 데이터를 준비할 필요가 없습니다. 또한 patrickstar의 모든 최적화 기술을 시연했습니다. 벤치마크를 실행하는 더 많은 최적화 요령은 최적화 옵션을 참조하세요.
BSD 3항 라이센스
@article{fang2021patrickstar,
title={PatrickStar: Parallel Training of Pre-trained Models via a Chunk-based Memory Management},
author={Fang, Jiarui and Yu, Yang and Zhu, Zilin and Li, Shenggui and You, Yang and Zhou, Jie},
journal={arXiv preprint arXiv:2108.05818},
year={2021}
}
@article{fang2022parallel,
title={Parallel Training of Pre-Trained Models via Chunk-Based Dynamic Memory Management},
author={Fang, Jiarui and Zhu, Zilin and Li, Shenggui and Su, Hui and Yu, Yang and Zhou, Jie and You, Yang},
journal={IEEE Transactions on Parallel and Distributed Systems},
volume={34},
number={1},
pages={304--315},
year={2022},
publisher={IEEE}
}
{jiaruifang, zilinzhu, josephyu}@tencent.com
WeChat AI 팀, Tencent NLP Oteam이 제공합니다.


