xcodec
1.0.0
오디오 언어 모델을 위한 통합 의미 체계 및 음향 코덱.
제목 : 코덱이 중요하다: 오디오 언어 모델에 대한 코덱의 의미론적 단점 탐구
저자 : Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo*, Wei Xue*
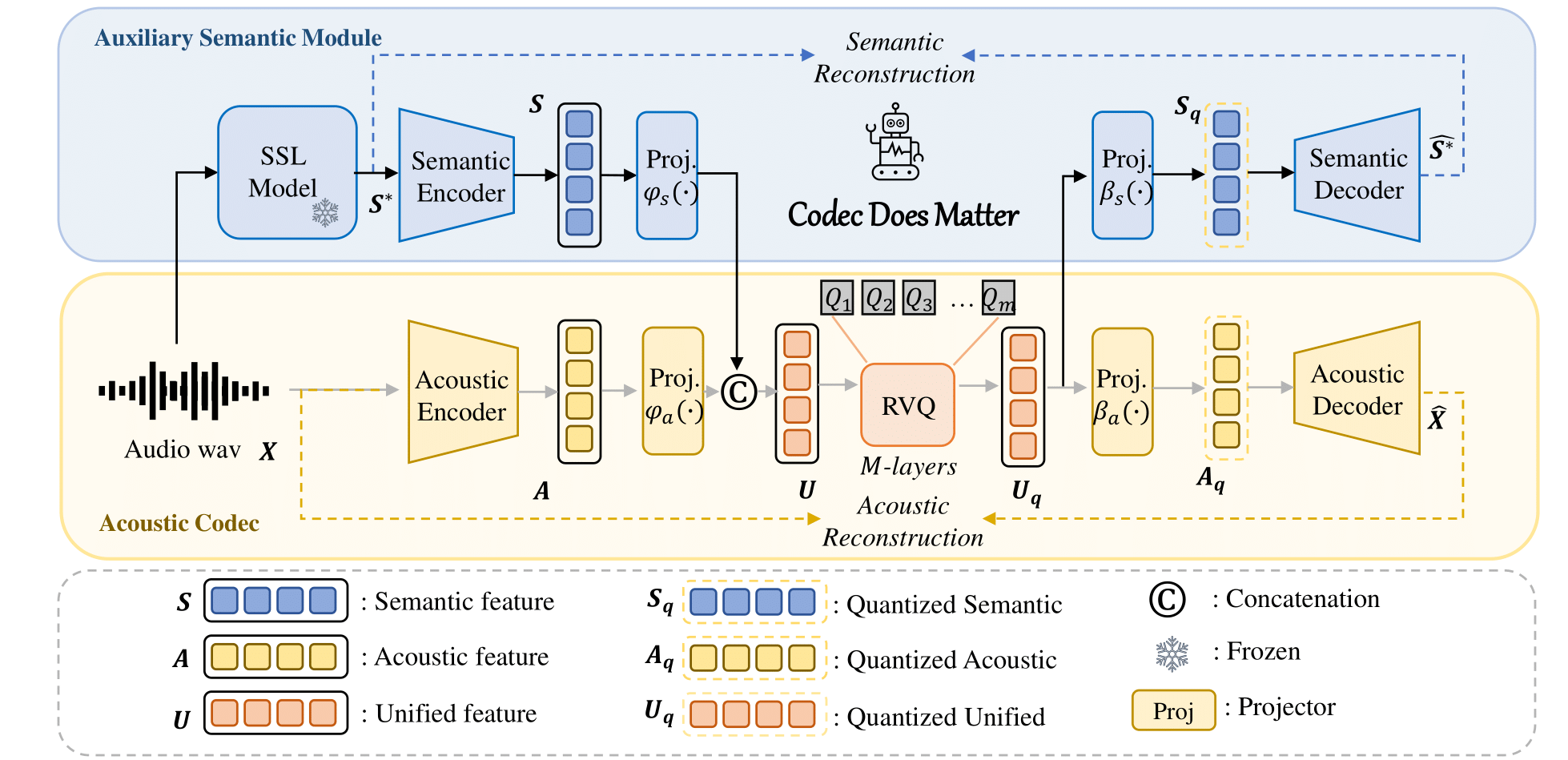
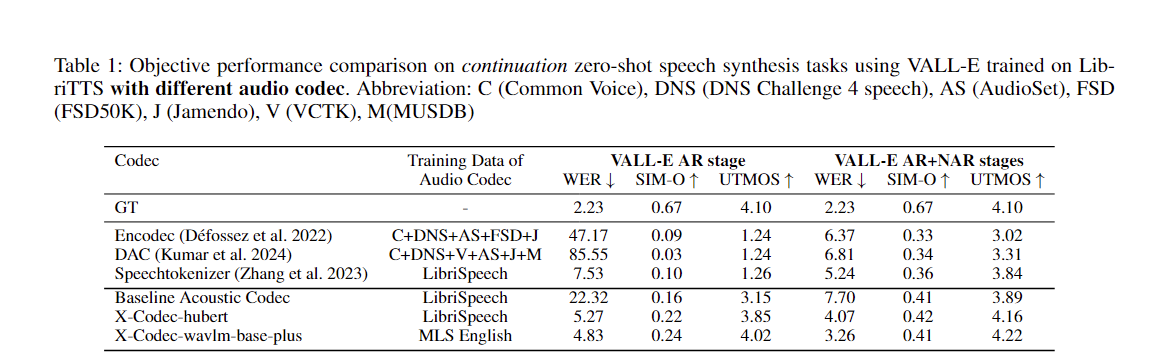
기존 음향 코덱을 향상시키기 위해 우리의 접근 방식을 쉽게 적용할 수 있습니다.
예를 들어
class Codec ():
def __init__ ( self ):
# Acoustic codec components
self . encoder = Encoder (...) # Acoustic encoder
self . decoder = Decoder (...) # Acoustic decoder
self . quantizer = RVQ (...) # Residual Vector Quantizer (RVQ)
# Adding the semantic module
self . semantic_model = AutoModel . from_pretrained (...) # e.g., Hubert, WavLM
# Adding Projector
self . fc_prior = nn . Linear (...)
self . fc_post1 = nn . Linear (...)
self . fc_post2 = nn . Linear (...)
def forward ( self , x , bw ):
# Encode the input acoustically and semantically
e_acoustic = self . encoder ( x )
e_semantic = self . semantic_model ( x )
# Combine acoustic and semantic features
combined_features = torch . cat ([ e_acoustic , e_semantic ])
# Apply prior transformation
transformed_features = self . fc_prior ( combined_features )
# Quantize the unified semantic and acoustic features
quantized , codes , bandwidth , commit_loss = self . quantizer ( transformed_features , bw )
# Post-process the quantized features
quantized_semantic = self . fc_post1 ( quantized )
quantized_acoustic = self . fc_post2 ( quantized )
# Decode the quantized acoustic features
output = self . decoder ( quantized_acoustic )
def semantic_loss ( self , semantic , quantized_semantic ):
return F . mse_loss ( semantic , quantized_semantic ) 자세한 내용은 우리의 코드를 참조하세요.
? Huggingface 모델 허브에 대한 링크입니다.
| 모델명 | 포옹하는 얼굴 | 구성 | 의미론적 모델 | 도메인 | 훈련 데이터 |
|---|---|---|---|---|---|
| xcodec_hubert_librispeech | ? | ? | ? Hubert 기반 | 연설 | 도서관 연설 |
| xcodec_wavlm_mls (논문에는 언급되지 않음) | ? | ? | ? Wavlm-base-plus | 연설 | MLS 영어 |
| xcodec_wavlm_more_data (논문에는 언급되지 않음) | ? | ? | ? Wavlm-base-plus | 연설 | MLS 영어 + 내부자료 |
| xcodec_hubert_general_audio | ? | ? | ?Hubert-base-general-audio | 일반 오디오 | 20만 시간의 내부 데이터 |
| xcodec_hubert_general_audio_more_data (논문에는 언급되지 않음) | ? | ? | ?Hubert-base-general-audio | 일반 오디오 | 더욱 균형잡힌 데이터 |
추론을 실행하려면 먼저 포옹 얼굴에서 모델과 구성을 다운로드하세요.
python inference.pyconfig에서 training_file과 Validation_file을 준비하세요. 파일에는 오디오 파일의 경로가 나열되어야 합니다.
/path/to/your/xxx.wav
/path/to/your/yyy.wav
...그 다음에:
torchrun --nnodes=1 --nproc-per-node=8 main_launch_vqdp.py우리의 코드 베이스는 주로 Uniaudio와 DAC에서 차용되었기 때문에 Uniaudio와 DAC의 저자들에게 특별한 감사를 전하고 싶습니다.
이 저장소가 도움이 되었다면 다음 형식으로 인용해 보세요.
@article { ye2024codecdoesmatterexploring ,
title = { Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model } ,
author = { Zhen Ye and Peiwen Sun and Jiahe Lei and Hongzhan Lin and Xu Tan and Zheqi Dai and Qiuqiang Kong and Jianyi Chen and Jiahao Pan and Qifeng Liu and Yike Guo and Wei Xue } ,
journal = { arXiv preprint arXiv:2408.17175 } ,
year = { 2024 } ,
}

