EasyEdit
1.0.0

대규모 언어 모델을 위한 사용하기 쉬운 지식 편집 프레임워크.
설치 • 빠른 시작 • 문서 • 문서 • 데모 • 벤치마크 • 기여자 • 슬라이드 • 비디오 • AK 특집
2024-10-23, EasyEdit는 조정 편집의 제한된 디코딩 방법을 통합하여 LLM 및 MLLM의 환각을 완화하며 DoLa 및 DeCo에서 사용할 수 있는 자세한 정보를 제공합니다.
2024-09-26, ?? 우리 논문 "WISE: 대규모 언어 모델의 평생 모델 편집을 위한 지식 메모리 재검토"가 NeurIPS 2024 에 승인되었습니다.
2024-09-20, ?? 우리 논문: "대규모 언어 모델의 지식 메커니즘: 조사 및 관점" 및 "대규모 언어 모델에 대한 개념적 지식 편집" 이 EMNLP 2024 결과 에 의해 승인되었습니다.
2024-07-29, EasyEdit에는 ROME을 일괄 설정으로 일반화하는 새로운 모델 편집 알고리즘 EMMET가 추가되었습니다. 이를 통해 기본적으로 ROME 손실 기능을 사용하여 일괄 편집을 수행할 수 있습니다.
2024년 7월 23일, 우리는 대규모 언어 모델에서 지식을 획득, 활용 및 진화하는 방법을 검토하는 "대규모 언어 모델의 지식 메커니즘: 조사 및 관점"이라는 새 논문을 발표합니다. 이 설문조사는 LLM의 지식을 정확하고 효율적으로 조작(편집)하기 위한 기본 메커니즘을 제공할 수 있습니다.
2024-06-04, ?? EasyEdit 논문이 ACL 2024 시스템 데모 트랙에 승인되었습니다.
2024-06-03, 우리는 "WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models" 라는 제목의 논문을 발표했으며, 새로운 편집 작업인 지속적인 지식 편집 과 이에 상응하는 WISE라는 평생 편집 방법을 소개했습니다.
2024년 4월 24일, EasyEdit은 Llama3-8B에 대한 ROME 방법 지원을 발표했습니다. 사용자는 변환기 패키지를 버전 4.40.0으로 업데이트하는 것이 좋습니다.
2024년 3월 29일, EasyEdit에서는 GRACE에 대한 롤백 지원을 도입했습니다. 자세한 소개는 EasyEdit 설명서를 참조하세요. 향후 업데이트에는 점차적으로 다른 방법에 대한 롤백 지원이 포함될 예정입니다.
2024-03-22, "Detoxifying Large Language Models via Knowledge Editing" 이라는 제목의 새로운 논문이 SafeEdit이라는 새로운 데이터세트와 DINM이라는 새로운 해독 방법 과 함께 발표되었습니다.
2024-03-12, "대형 언어 모델에 대한 개념 지식 편집" 이라는 제목의 또 다른 논문이 발표되어 ConceptEdit이라는 새로운 데이터 세트를 소개했습니다.
2024-03-01, EasyEdit은 FT-M 이라는 새로운 방법에 대한 지원을 추가했습니다. 이 방법에는 대상 답변에 대한 교차 엔트로피 손실을 사용하고 원본 텍스트를 마스킹하는 특정 MLP 레이어를 교육하는 작업이 포함됩니다. ROME의 FT-L 구현보다 성능이 뛰어납니다. 173호의 저자에게 조언을 해주셔서 감사드립니다.
2024년 2월 27일, EasyEdit에서는 "InstructEdit: 대규모 언어 모델을 위한 명령어 기반 지식 편집" 논문에 제공된 기술 세부 정보와 함께 InstructEdit이라는 새로운 방법에 대한 지원을 추가했습니다.
Accelerate 사용하여 여러 GPU가 있는 모델 편집에 대한 지원이 추가되었습니다.대규모 언어 모델을 위한 지식 편집에 대한 종합 연구 [논문][벤치마크][코드]
IJCAI 2024 튜토리얼 구글 드라이브
COLING 2024 튜토리얼 구글 드라이브
AAAI 2024 튜토리얼 Google 드라이브
AACL 2023 튜토리얼 [구글 드라이브] [바이두 팬]
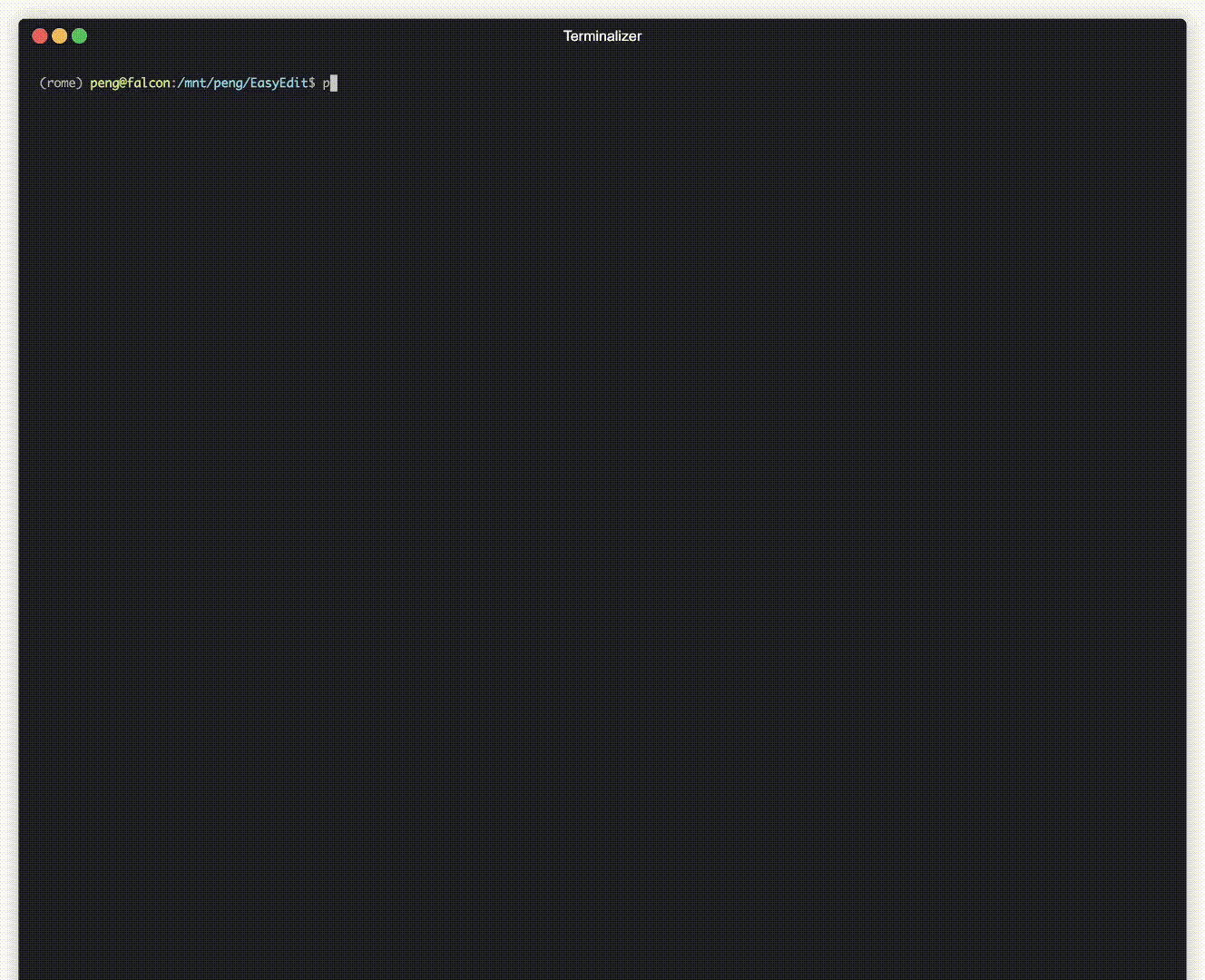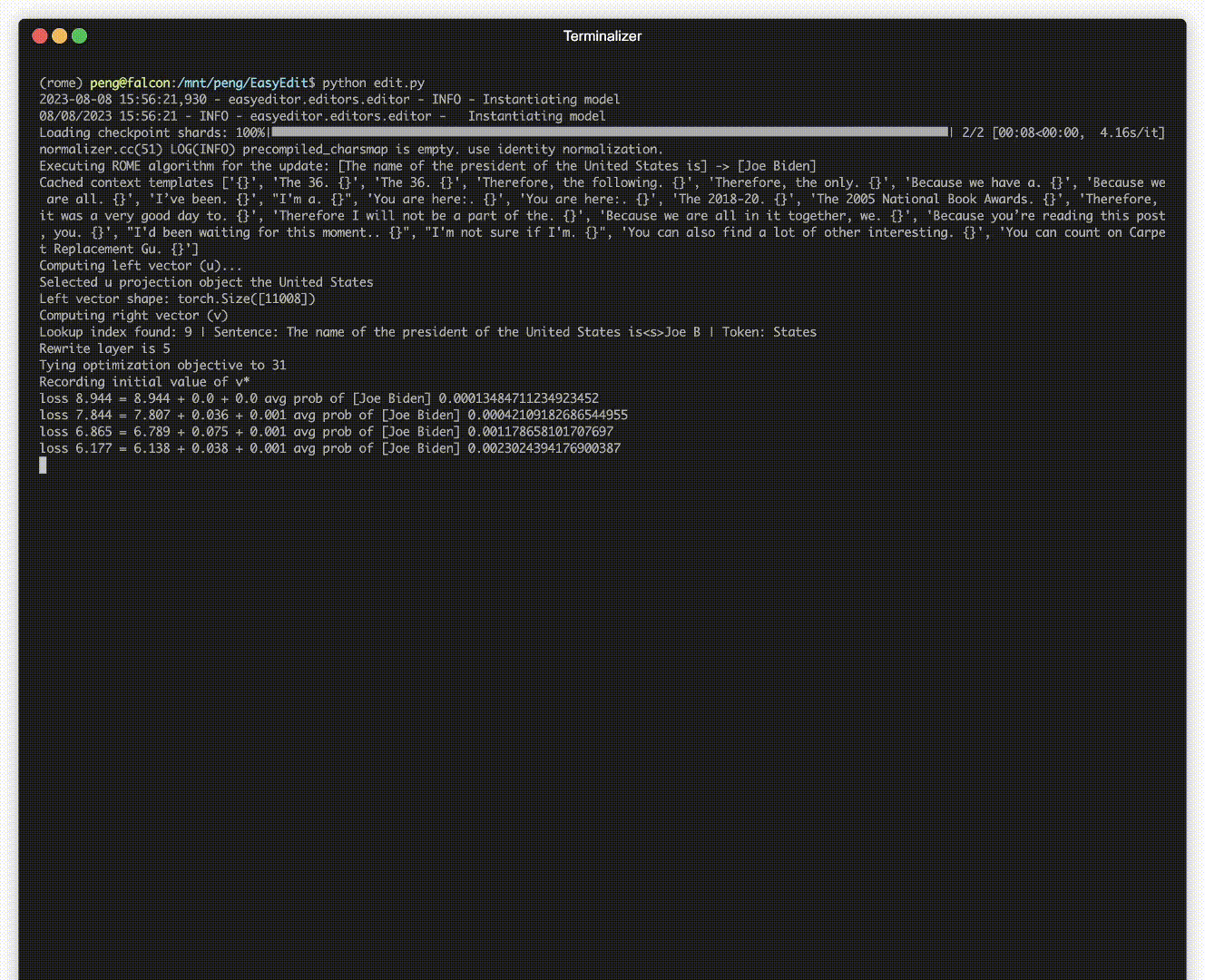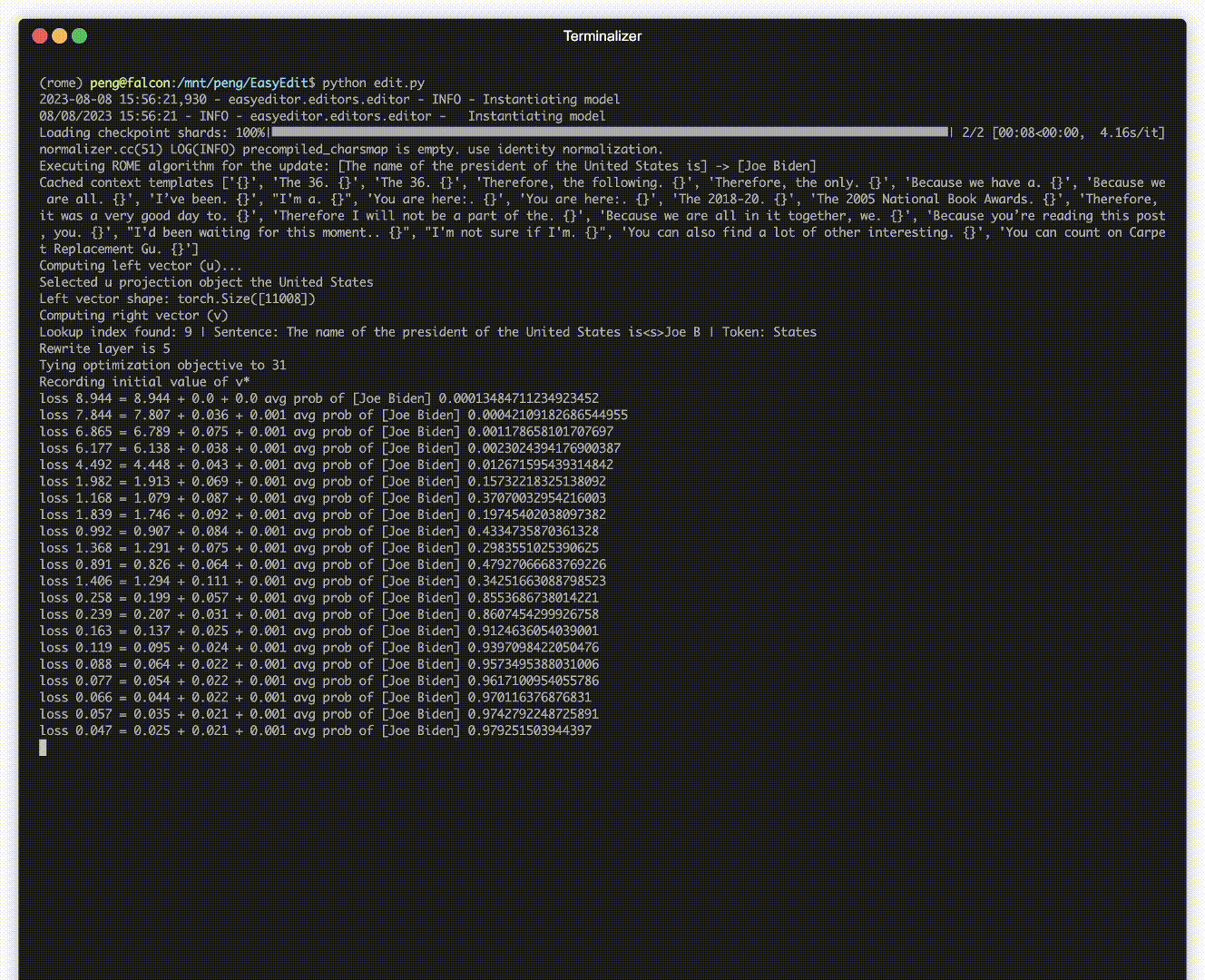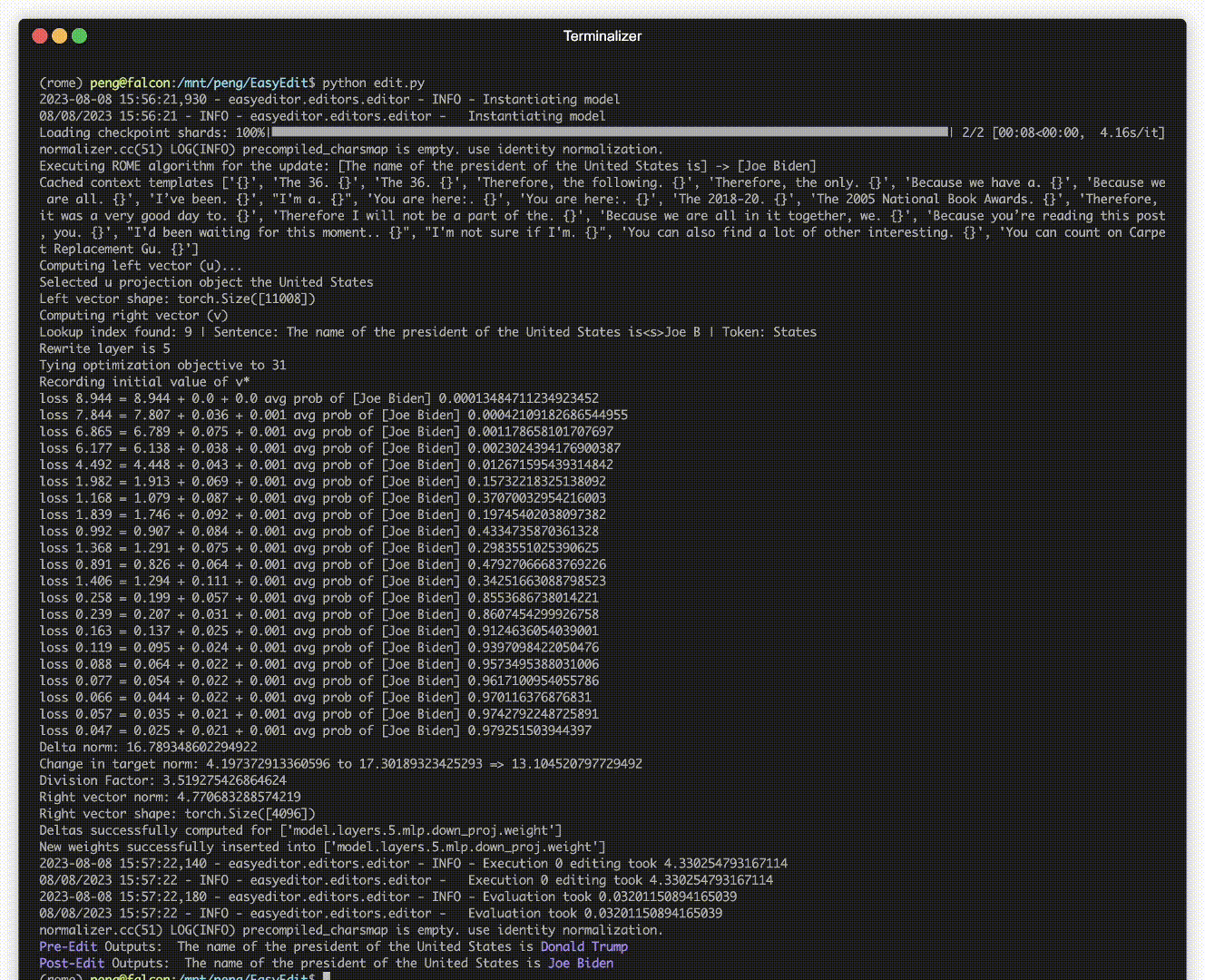
편집 시연이 있습니다. GIF 파일은 Terminalizer에 의해 생성됩니다.
편리한 Jupyter Notebook을 제공합니다! 이를 통해 미국 대통령에 대한 LLM의 지식을 편집하고 Biden에서 Trump로 전환하고 심지어 Biden으로 다시 전환할 수도 있습니다. 여기에는 WISE, AlphaEdit, AdaLoRA 및 프롬프트 기반 편집과 같은 방법이 포함됩니다.
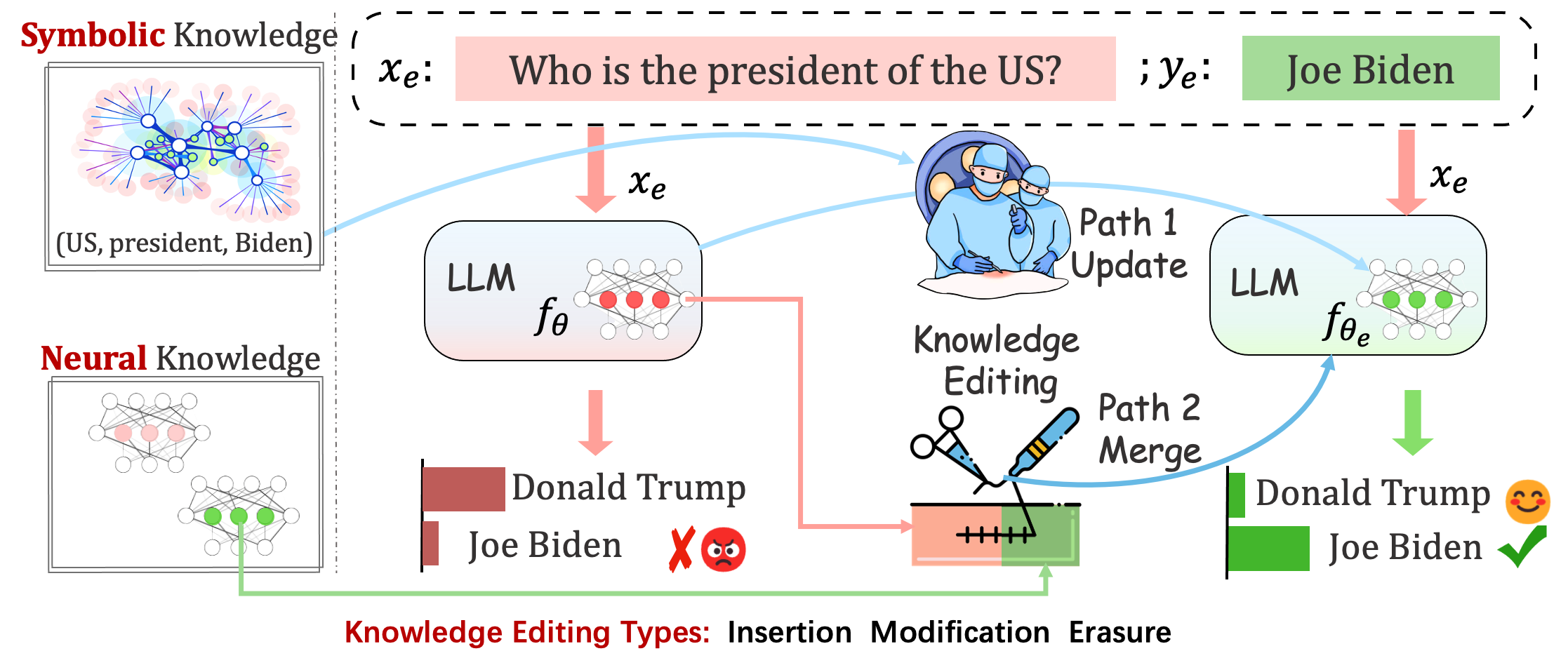
배포된 모델에서는 여전히 예측할 수 없는 오류가 발생할 수 있습니다. 예를 들어, LLM은 환각을 일으키고 편견을 지속시키며 사실을 부패시키는 것으로 악명 높으므로 사전 훈련된 모델의 특정 동작을 조정할 수 있어야 합니다.
지식 편집은 기본 모델의 조정을 목표로 합니다.
단일 편집 후 모델의 성능을 평가합니다. 모델은 단일 편집 후 원래 가중치를 다시 로드합니다(예: LoRA는 어댑터 가중치를 삭제합니다). sequential_edit=False 로 설정해야 합니다.
이를 위해서는 순차적인 편집이 필요하며 모든 지식 업데이트가 적용된 후 평가가 수행됩니다.
매개변수를 조정합니다. sequential_edit=True : README(자세한 내용)를 설정하면 됩니다.
관련되지 않은 샘플의 모델 동작에 영향을 주지 않고 편집된 모델을 만드는 것이 궁극적인 목표입니다.
이미지 캡션 및 시각적 질문 응답을 위한 편집 작업 . 읽어보기
제안된 작업은 개인의 의견이 성격 특성의 측면을 반영할 수 있다는 점을 고려하여 특정 주제에 대한 의견을 편집하여 LLM의 성격을 편집하려는 예비 시도를 취합니다. 우리는 데이터 세트를 구성하고 LLM의 성격 표현을 평가하기 위한 기초로 확립된 BIG FIVE 이론을 활용합니다. 읽어보기
평가
로지트 기반
세대 기반
Acc 및 TPEI를 평가하는 동안 여기에서 훈련된 분류기를 다운로드할 수 있습니다.
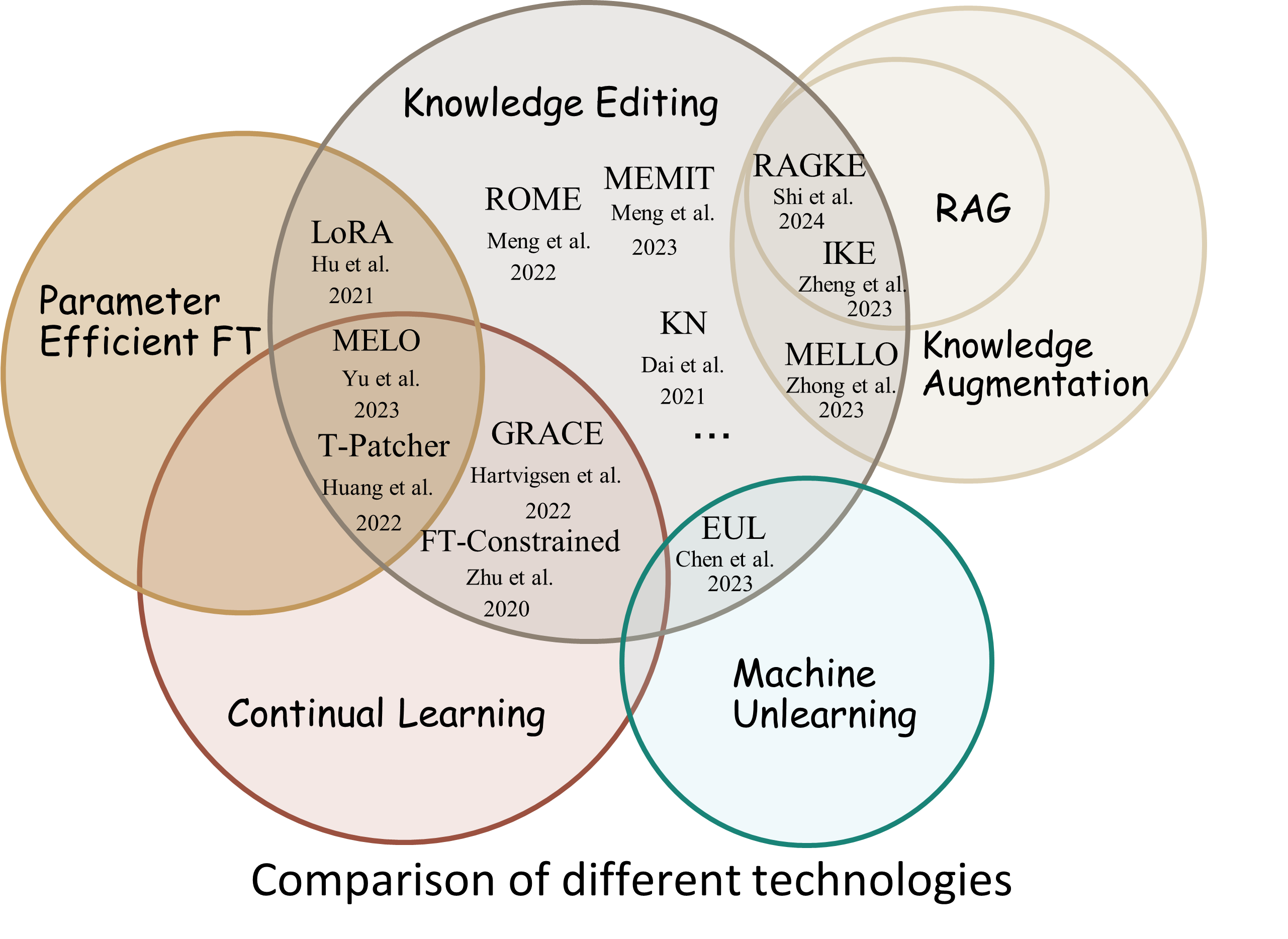
지식 편집 프로세스는 일반적으로 편집 범위 라고 하는 편집 예시와 밀접하게 관련된 광범위한 입력 집합에 대한 예측에 영향을 미칩니다.
성공적인 편집은 관련 없는 입력을 유지하면서 편집 범위 내에서 모델의 동작을 조정해야 합니다.
Reliability : 주어진 편집 설명자를 사용한 편집 성공률Generalization : 편집 범위 내에서 편집 성공률Locality : 관련 없는 입력을 편집한 후 모델의 출력이 변경되는지 여부Portability : 추론/적용을 위한 편집 성공률(원 홉, 동의어, 논리적 일반화)Efficiency : 시간 및 메모리 소비 EasyEdit은 GPT-J , Llama , GPT-NEO , GPT2 , T5 ( 1B 에서 65B 까지 지원 모델)와 같은 LLM(대형 언어 모델)을 편집하기 위한 Python 패키지입니다. 이 패키지의 목적은 LLM의 동작을 효율적으로 변경하는 것입니다. 다른 입력 전반에 걸쳐 성능에 부정적인 영향을 주지 않고 특정 도메인을 제어합니다. 사용하기 쉽고 확장하기 쉽도록 설계되었습니다.
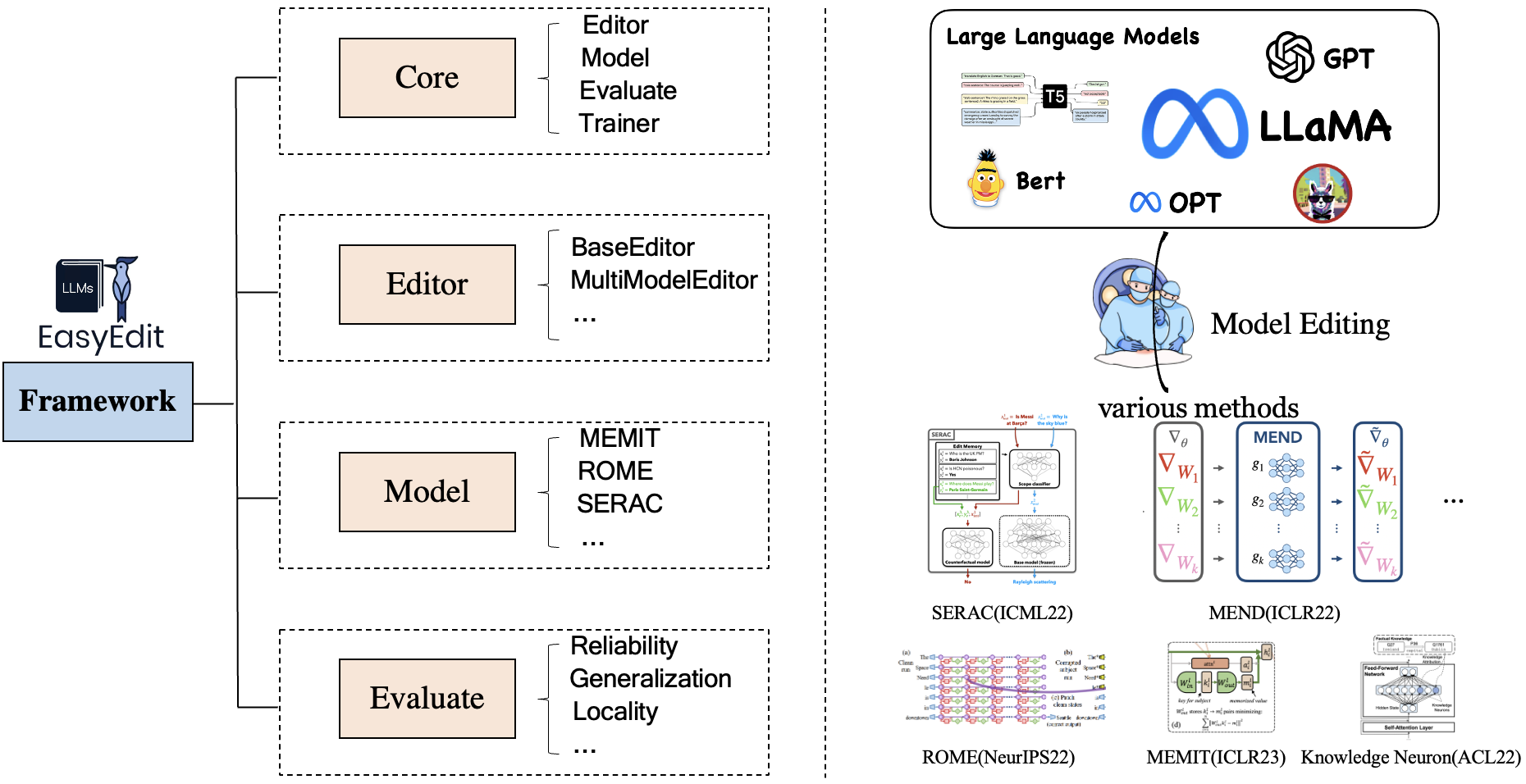
EasyEdit에는 각각 편집 시나리오, 편집 기술 및 평가 방법을 나타내는 Editor , Method 및 Evaluate 에 대한 통합 프레임워크가 포함되어 있습니다.
각 지식 편집 시나리오는 세 가지 구성 요소로 구성됩니다.
Editor : LM용 BaseEditor( 사실적 지식 및 생성 편집기), MultiModalEditor( MultiModal Knowledge ) 등.Method : 사용된 특정 지식 편집 기술(예: ROME , MEND , ..)Evaluate : 지식 편집 성능을 평가하기 위한 지표입니다 .Reliability , Generalization , Locality , Portability현재 지원되는 지식 편집 기술은 다음과 같습니다.
참고 1: 이 툴킷의 제한된 호환성으로 인해 T-Patcher, KE, CaliNet을 포함한 일부 지식 편집 방법은 지원되지 않습니다.
참고 2: 마찬가지로 MALMEN 방법도 같은 이유로 부분적으로만 지원되며 계속해서 개선될 예정입니다.
특정 요구 사항에 따라 다양한 편집 방법을 선택할 수 있습니다.
| 방법 | T5 | GPT-2 | GPT-J | GPT-네오 | 야마 | 바이촨 | 채팅GLM | 인턴LM | 퀀 | 미스트랄 |
|---|---|---|---|---|---|---|---|---|---|---|
| FT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 아다로라 | ✅ | ✅ | ||||||||
| 세락 | ✅ | ✅ | ✅ | ✅ | ||||||
| 이케 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 수선 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| KN | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 로마 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| r-로마 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| MEMIT | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | |
| 개미 | ✅ | ✅ | ✅ | |||||||
| 우아함 | ✅ | ✅ | ✅ | |||||||
| 멜로 | ✅ | |||||||||
| PMET | ✅ | ✅ | ||||||||
| 지시편집 | ✅ | ✅ | ||||||||
| DINM | ✅ | ✅ | ✅ | |||||||
| 지혜로운 | ✅ | ✅ | ✅ | ✅ | ✅ | |||||
| 알파편집 | ✅ | ✅ | ✅ |
❗️❗️ Mistral을 사용하려면
transformers라이브러리를 4.34.0 버전으로 수동으로 업데이트하세요. 다음 코드를 사용할 수 있습니다:pip install transformers==4.34.0.
| 일하다 | 설명 | 길 |
|---|---|---|
| 지시편집 | InstructEdit: 대규모 언어 모델을 위한 명령어 기반 지식 편집 | 빠른 시작 |
| DINM | 지식 편집을 통한 대규모 언어 모델 해독 | 빠른 시작 |
| 지혜로운 | 현명한: 대규모 언어 모델의 평생 모델 편집을 위한 지식 메모리 재고 | 빠른 시작 |
| 개념편집 | 대규모 언어 모델에 대한 개념 지식 편집 | 빠른 시작 |
| MM편집 | 다중 모드 대형 언어 모델을 편집할 수 있습니까? | 빠른 시작 |
| 성격편집 | 대규모 언어 모델의 성격 편집 | 빠른 시작 |
| 즉각적인 | PROMPT 기반 지식 편집 방법 | 빠른 시작 |
벤치마크: KnowEdit [껴안는 얼굴][WiseModel][ModelScope]
❗️❗️ 참고로 KnowEdit은 지식 편집에 대한 종합적인 평가를 위해 WikiBio , ZsRE , WikiData Counterfact , WikiData Recent , conssent , Sanitation 을 포함한 기존 데이터 세트를 재구성하고 확장하여 구성됩니다. 해당 데이터세트의 구축자와 유지관리자에게 특별한 감사를 드립니다.
Counterfact와 WikiData Counterfact는 동일한 데이터 세트가 아닙니다.
| 일 | 지식 삽입 | 지식 수정 | 지식 삭제 | |||
|---|---|---|---|---|---|---|
| 데이터세트 | 최근 위키 | ZsRE | 위키바이오 | WikiData 반대말 | 동의하다 | 위생 |
| 유형 | 사실 | 질문 답변 | 환각 | 반대말 | 감정 | 원하지 않는 정보 |
| # 기차 | 570 | 10,000 | 592 | 1,455 | 14,390 | 80 |
| # 시험 | 1,266 | 1301 | 1,392 | 885 | 800 | 80 |
사용자가 KnowEdit을 쉽게 사용할 수 있도록 자세한 스크립트를 제공합니다. 예제를 참조하세요.
knowedit
├── WikiBio
│ ├── wikibio-test-all.json
│ └── wikibio-train-all.json
├── ZsRE
│ └── ZsRE-test-all.json
├── wiki_counterfact
│ ├── test_cf.json
│ └── train_cf.json
├── convsent
│ ├── blender_test.json
│ ├── blender_train.json
│ └── blender_val.json
├── convsent
│ ├── trivia_qa_test.json
│ └── trivia_qa_train.json
└── wiki_recent
├── recent_test.json
└── recent_train.json
| 데이터세트 | 포옹얼굴 | 현명한 모델 | 모델범위 | 설명 |
|---|---|---|---|---|
| 확인하기편집 | [껴안는 얼굴] | [와이즈모델] | [모델 범위] | 중국어 지식 편집용 데이터 세트 |
CKnowEdit 은 중국어 지식 베이스에서 가져온 모든 데이터를 포함하여 중국어의 특징이 강한 지식 편집을 위한 고품질 중국어 데이터세트입니다. 이는 현재 LLM이 중국어를 이해하는 데 내재된 뉘앙스와 어려움을 더 깊이 식별하도록 세심하게 설계되어 LLM 내에서 중국어 관련 지식을 개선하기 위한 강력한 리소스를 제공합니다.
CKnowEdit 의 데이터에 대한 필드 설명은 다음과 같습니다.
"prompt" : query inputed to the model ( str )
"target_old" : the incorrect response previously generated by the model ( str )
"target_new" : the accurate answer of the prompt ( str )
"portability_prompt" : new prompts related to the target knowledge ( list or None )
"portability_answer" : accurate answers corresponding to the portability_prompt ( list or None )
"locality_prompt" : new prompts unrelated to the target knowledge ( list or None )
"locality_answer" : accurate answers corresponding to the locality_prompt ( list or None )
"rephrase" : alternative ways to phrase the original prompt ( list ) CknowEdit
├── Chinese Literary Knowledge
│ ├── Ancient Poetry
│ ├── Proverbs
│ └── Idioms
├── Chinese Linguistic Knowledge
│ ├── Phonetic Notation
│ └── Classical Chinese
├── Chinese Geographical Knowledge
└── Ruozhiba
| 데이터세트 | 구글 드라이브 | BaiduNetDisk | 설명 |
|---|---|---|---|
| ZsRE 플러스 | [구글드라이브] | [바이두넷디스크] | 질문 변경을 사용한 질문 답변 데이터세트 |
| 카운터팩트 플러스 | [구글드라이브] | [바이두넷디스크] | 엔터티 교체를 사용한 반박 데이터 세트 |
지식 편집의 효율성을 검증하기 위해 zsre 및 counterfact 데이터 세트를 제공합니다. 여기에서 다운로드할 수 있습니다. [구글 드라이브], [바이두넷디스크].
editing-data
├── counterfact
│ ├── counterfact-edit.json
│ ├── counterfact-train.json
│ └── counterfact-val.json
├── locality
│ ├── Commonsense Task
│ │ ├── piqa_valid-labels.lst
│ │ └── piqa_valid.jsonl
│ ├── Distracting Neighbor
│ │ └── counterfact_distracting_neighbor.json
│ └── Other Attribution
│ └── counterfact_other_attribution.json
├── portability
│ ├── Inverse Relation
│ │ └── zsre_inverse_relation.json
│ ├── One Hop
│ │ ├── counterfact_portability_gpt4.json
│ │ └── zsre_mend_eval_portability_gpt4.json
│ └── Subject Replace
│ ├── counterfact_subject_replace.json
│ └── zsre_subject_replace.json
└── zsre
├── zsre_mend_eval.json
├── zsre_mend_train_10000.json
└── zsre_mend_train.json
spouse 등 일대일 관계에 대한 평가| 데이터세트 | 구글 드라이브 | HuggingFace 데이터세트 | 설명 |
|---|---|---|---|
| 개념편집 | [구글드라이브] | [HuggingFace 데이터셋] | 개념 지식 편집을 위한 데이터세트 |
data
└──concept_data.json
├──final_gpt2_inter.json
├──final_gpt2_intra.json
├──final_gptj_inter.json
├──final_gptj_intra.json
├──final_llama2chat_inter.json
├──final_llama2chat_intra.json
├──final_mistral_inter.json
└──final_mistral_intra.json
개념별 평가 지표
Instance Change : 이러한 인스턴스 수준 변경의 복잡성 캡처Concept Consistency : 생성된 개념 정의의 의미론적 유사성 | 데이터세트 | 구글 드라이브 | BaiduNetDisk | 설명 |
|---|---|---|---|
| E-IC | [구글드라이브] | [바이두넷디스크] | 이미지 캡션 편집을 위한 데이터 세트 |
| E-VQA | [구글드라이브] | [바이두넷디스크] | 시각적 질문 답변 편집을 위한 데이터 세트 |
editing-data
├── caption
│ ├── caption_train_edit.json
│ └── caption_eval_edit.json
├── locality
│ ├── NQ dataset
│ │ ├── train.json
│ │ └── validation.json
├── multimodal_locality
│ ├── OK-VQA dataset
│ │ ├── okvqa_loc.json
└── vqa
├── vqa_train.json
└── vqa_eval.json
| 데이터세트 | HuggingFace 데이터세트 | 설명 |
|---|---|---|
| 안전편집 | [HuggingFace 데이터셋] | LLM 해독을 위한 데이터 세트 |
data
└──SafeEdit_train.json
└──SafeEdit_val.json
└──SafeEdit_test.json
특정 평가 지표 해독
Defense Duccess (DS) : LLM을 수정하는 데 사용되는 적대적 입력(공격 프롬프트 + 유해한 질문)에 대해 편집된 LLM의 해독 성공률입니다.Defense Generalization (DG) : 도메인 외부 악성 입력에 대해 편집된 LLM의 해독 성공률입니다.General Performance : 관련 없는 작업 수행에 대한 부작용입니다. | 방법 | 설명 | GPT-2 | 야마 |
|---|---|---|---|
| 이케 | 상황 내 학습(ICL) 편집 | [Colab-gpt2] | [콜라브라마] |
| 로마 | 뉴런을 찾은 후 편집 | [Colab-gpt2] | [콜라브라마] |
| MEMIT | 뉴런을 찾은 후 편집 | [Colab-gpt2] | [콜라브라마] |
참고: EasyEdit에는 Python 3.9+를 사용하십시오. 시작하려면 간단히 conda를 설치하고 다음을 실행하십시오.
git clone https://github.com/zjunlp/EasyEdit.git
conda create -n EasyEdit python=3.9.7
...
pip install -r requirements.txt결과는 모두 기본 구성을 기반으로 합니다.
| 라마-2-7B | chatglm2 | gpt-j-6b | gpt-xl | |
|---|---|---|---|---|
| FT | 60GB | 58GB | 55GB | 7GB |
| 세락 | 42GB | 32GB | 31GB | 10GB |
| 이케 | 52GB | 38GB | 38GB | 10GB |
| 수선 | 46GB | 37GB | 37GB | 13GB |
| KN | 42GB | 39GB | 40GB | 12GB |
| 로마 | 31GB | 29GB | 27GB | 10GB |
| MEMIT | 33GB | 31GB | 31GB | 11GB |
| 아다로라 | 29GB | 24GB | 25GB | 8GB |
| 우아함 | 27GB | 23GB | 6GB | |
| 지혜로운 | 34GB | 27GB | 7GB |
약 5초 정도의 대규모 언어 모델(LLM) 편집
다음 예는 EasyEdit으로 편집을 수행하는 방법을 보여줍니다. 더 많은 예제와 튜토리얼은 예제에서 찾을 수 있습니다.
BaseEditor언어 양식 지식 편집을 위한 클래스입니다. 특정 요구 사항에 따라 적절한 편집 방법을 선택할 수 있습니다.
EasyEdit 의 모듈성과 유연성을 통해 쉽게 모델을 편집할 수 있습니다.
1단계: 편집할 개체로 PLM을 정의합니다. 편집할 PLM을 선택합니다. EasyEdit HuggingFace에서 검색할 수 있는 부분 모델(지금까지 T5 , GPTJ , GPT-NEO , LlaMA )을 지원합니다. 해당 구성 파일 디렉터리는 hparams/YUOR_METHOD/YOUR_MODEL.YAML (예: hparams/MEND/gpt2-xl.yaml 입니다. 지식 편집을 위한 개체를 선택하려면 해당 model_name 설정하세요.
model_name : gpt2-xl
model_class : GPT2LMHeadModel
tokenizer_class : GPT2Tokenizer
tokenizer_name : gpt2-xl
model_parallel : false # true for multi-GPU editing2단계: 적절한 지식 편집 방법 선택
## In this case, we use MEND method, so you should import `MENDHyperParams`
from easyeditor import MENDHyperParams
## Loading config from hparams/MEMIT/gpt2-xl.yaml
hparams = MENDHyperParams . from_hparams ( './hparams/MEND/gpt2-xl' )3단계: 편집 설명자 및 편집 대상 제공
## edit descriptor: prompt that you want to edit
prompts = [
'What university did Watts Humphrey attend?' ,
'Which family does Ramalinaceae belong to' ,
'What role does Denny Herzig play in football?'
]
## You can set `ground_truth` to None !!!(or set to original output)
ground_truth = [ 'Illinois Institute of Technology' , 'Lecanorales' , 'defender' ]
## edit target: expected output
target_new = [ 'University of Michigan' , 'Lamiinae' , 'winger' ] 4단계: BaseEditor 로 결합 EasyEdit Huggingface: from_hparams 와 같이 Editor 초기화하는 간단하고 통합된 방법을 제공합니다.
## Construct Language Model Editor
editor = BaseEditor . from_hparams ( hparams )5단계: 평가용 데이터 제공 이식성과 지역성에 대한 데이터는 모두 선택 사항 입니다(기본 편집 성공률 평가에만 없음으로 설정). 두 가지 모두에 대한 데이터 형식은 dict 입니다. 각 측정 차원에 대해 해당 프롬프트와 해당 실제값을 제공해야 합니다. 다음은 데이터의 예입니다.
locality_inputs = {
'neighborhood' :{
'prompt' : [ 'Joseph Fischhof, the' , 'Larry Bird is a professional' , 'In Forssa, they understand' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
},
'distracting' : {
'prompt' : [ 'Ray Charles, the violin Hauschka plays the instrument' , 'Grant Hill is a professional soccer Magic Johnson is a professional' , 'The law in Ikaalinen declares the language Swedish In Loviisa, the language spoken is' ],
'ground_truth' : [ 'piano' , 'basketball' , 'Finnish' ]
}
}위의 예에서는 "이웃"과 "산만함"에 대한 편집 방법의 성능을 평가합니다.
6단계: 편집 및 평가가 완료되었습니다! 편집할 모델에 대한 편집 및 평가를 수행할 수 있습니다. edit 기능은 수정된 모델 가중치뿐만 아니라 편집 프로세스와 관련된 일련의 측정항목을 반환합니다. [ sequential_edit=True ]
metrics , edited_model , _ = editor . edit (
prompts = prompts ,
ground_truth = ground_truth ,
target_new = target_new ,
locality_inputs = locality_inputs ,
sequential_edit = False # True: start continuous editing ✈️
)
## metrics: edit success, rephrase success, locality e.g.
## edited_model: post-edit modelEasyEdit의 최대 입력 길이는 512입니다. 이 길이를 초과하면 "CUDA 오류: 장치 측 어설션이 트리거되었습니다."라는 오류가 발생합니다. 다음 파일에서 최대 길이를 수정할 수 있습니다:LINK
7단계: 롤백 순차 편집에서 편집 결과가 만족스럽지 않고 이전 편집 내용을 잃고 싶지 않은 경우 롤백 기능을 사용하여 이전 편집 내용을 취소할 수 있습니다. 현재는 GRACE 방식만 지원합니다. 여러분이 해야 할 일은 edit_key를 사용하여 편집 내용을 되돌리는 코드 한 줄뿐입니다.
editor.rolllback('edit_key')
EasyEdit에서는 기본적으로 edit_key로 target_new를 사용합니다.
편집 전후의 모델 예측 평가를 포함하여 반환 측정 항목을 dict 형식으로 지정합니다. 각 편집에는 다음 측정항목이 포함됩니다.
rewrite_acc rephrase_acc locality portablility 

