mengzi retrieval lm
1.0.0
Langboat Technology에서는 실제 업계 요구 사항을 충족할 수 있도록 사전 훈련된 모델을 강화하여 더 가볍게 만드는 데 중점을 두고 있습니다. 이 목표를 달성하려면 검색 기반 접근 방식(예: RETRO, REALM 및 RAG)이 중요합니다.
이 저장소는 검색이 강화된 언어 모델을 실험적으로 구현한 것입니다. 현재는 GPT-Neo에서만 검색 피팅을 지원합니다.
검색 지원을 추가하기 위해 Huggingface Transformers와 lm-evaluation-harness를 분기했습니다. 인덱싱 부분은 검색과 훈련을 더 효과적으로 분리하기 위해 HTTP 서버로 구현됩니다.
대부분의 모델 구현은 RETRO-pytorch 및 GPT-Neo에서 복사되었습니다. transformers-cli 사용하여 GPT-Neo를 기반으로 Re_gptForCausalLM 이라는 새 모델을 추가한 다음 여기에 검색 부분을 추가합니다.
200G 검색 라이브러리를 사용하여 EleutherAI/gpt-neo-125M에 장착된 모델을 업로드했습니다.
다음과 같이 모델을 초기화할 수 있습니다.
from transformers import Re_gptForCausalLM
model = Re_gptForCausalLM . from_pretrained ( 'Langboat/ReGPT-125M-200G' )그리고 다음과 같이 모델을 평가합니다.
python main.py
--model retrieval
--model_args pretrained=model_path
--device 0
--tasks wikitext,lambada,winogrande,mathqa,pubmedqa
--batch_size 1우리는 문장_변환기의 임베딩을 텍스트 표현으로 사용하여 유사성을 계산합니다. 다음과 같이 Sentence-BERT 모델을 초기화할 수 있습니다.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer ( 'all-MiniLM-L12-v2' )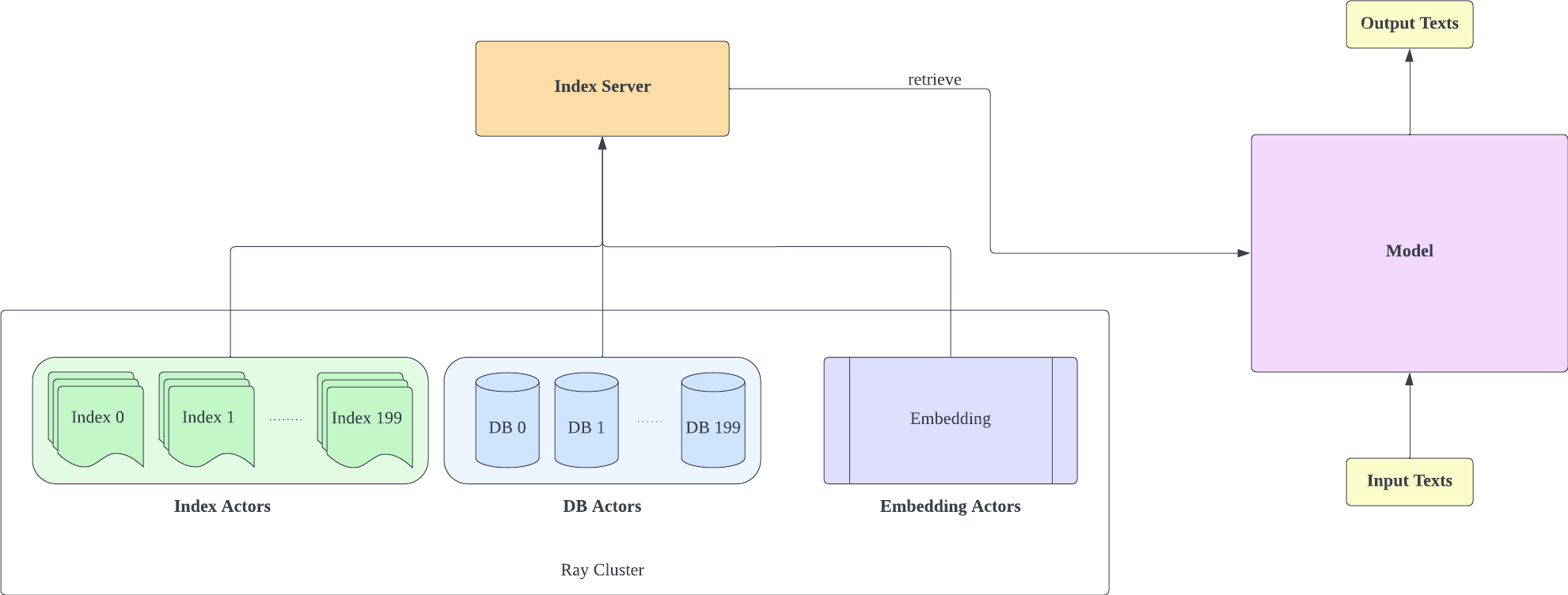
conda create -n mengzi-retrieval-fit python=3.7
conda activate mengzi-retrieval-fit
conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia
git clone https://github.com/Langboat/mengzi-retrieval-lm.git
cd mengzi-retrieval-lm
git submodule update --init --recursive
pip install -r requirement.txt
cd transformers/
pip install -e .
cd ..
python -c " from sentence_transformers import SentenceTransformer; model = SentenceTransformer('all-MiniLM-L12-v2') " IVF1024PQ48을 faiss 인덱스 팩토리로 사용하여 인덱스와 데이터베이스를 Huggingface 모델 허브에 업로드했습니다. 이는 다음 명령을 사용하여 다운로드할 수 있습니다.
download_index_db.py에서 다운로드하려는 인덱스 및 데이터베이스 수를 지정할 수 있습니다.
python -u download_index_db.py --num 200여기에서 장착된 모델을 수동으로 다운로드할 수 있습니다: https://huggingface.co/Langboat/ReGPT-125M-200G
인덱스 서버는 FastAPI와 Ray를 기반으로 합니다. Ray's Actor를 사용하면 계산 집약적인 작업이 비동기식으로 캡슐화되어 단 하나의 FastAPI 서버 인스턴스로 CPU 및 GPU 리소스를 효율적으로 활용할 수 있습니다. 다음과 같이 인덱스 서버를 초기화할 수 있습니다.
cd index-server/
ray start --head
python -u api.py
--config config_IVF1024PQ48.json
--db_path ../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966
- 구성 IVF1024PQ48.json 샤드 개수는 다운로드한 인덱스 수와 일치해야 합니다. db_path 아래에서 현재 다운로드된 인덱스 번호를 확인할 수 있습니다.
- 이 구성은 A100-40G에서 테스트되었으므로 다른 GPU를 사용하는 경우 하드웨어에 맞게 조정하는 것이 좋습니다.
- 인덱스 서버를 배포한 후 lm-evaluation-harness/config.json 및 train/config.json에서 request_server를 수정해야 합니다.
- config_IVF1024PQ48.json에서 Encoder_actor_count를 줄여 필요한 메모리 리소스를 줄일 수 있습니다.
· db_path:huggingface에서 데이터베이스를 다운로드하는 위치입니다. "../db/models—Langboat—Pile-DB/snapshots/fd35bcce75db5c1b7385a28018029f7465b4e966"은 예입니다.
이 명령은 Huggingface에서 데이터베이스와 인덱스 데이터를 다운로드합니다.
구성 파일(config IVF1024PQ48)에서 인덱스 폴더를 인덱스 폴더의 경로를 가리키도록 변경하고, 데이터베이스 폴더의 스냅샷을 db 경로로 api.py 스크립트에 보냅니다.
다음 명령을 사용하여 인덱스 서버를 중지합니다.
ray stop
- 훈련, 평가, 추론 중에 인덱스 서버를 활성화된 상태로 유지해야 한다는 점을 명심하세요.
훈련을 구현하려면 train/train.py를 사용하십시오. train/config.json을 수정하여 훈련 매개변수를 변경할 수 있습니다.
다음과 같이 훈련을 초기화할 수 있습니다.
cd train
python -u train.py
- 인덱스 서버는 메모리 리소스를 사용해야 하므로 인덱스 서버와 모델 교육을 다른 GPU에 배포하는 것이 좋습니다.
텍스트 손실과 그 복잡성을 판단하기 위한 추론으로 train/inference.py를 활용합니다.
cd train
python -u inference.py
--model_path Langboat/ReGPT-125M-200G
--file_name data/test_data.json
- 데이터 폴더의 test_data.json 및 train_data.json은 현재 지원되는 파일 형식이므로 데이터를 이 형식으로 수정할 수 있습니다.
평가 방법으로 lm-evaluation-harness 사용
모델 훈련의 seq_len이 1025이기 때문에 모델 비교를 위한 초기 설정으로 lm-evaluation-harness의 seq_len을 1025로 설정했습니다.
cd lm-evaluation-harness
python setup.py installpython main.py
--model retrieval
--model_args pretrained=Langboat/ReGPT-125M-200G
--device 0
--tasks wikitext
--batch_size 1· model_path : 피팅 모델 경로
python main.py
--model gpt2
--model_args pretrained=EleutherAI/gpt-neo-125M
--device 0
--tasks wikitext
--batch_size 1평가 결과는 다음과 같습니다
| 모델 | 위키텍스트 word_perplexity |
|---|---|
| EleutherAI/gpt-neo-125M | 35.8774 |
| 랭보트/ReGPT-125M-200G | 22.115 |
| EleutherAI/gpt-neo-1.3B | 17.6979 |
| 랭보트/ReGPT-125M-400G | 14.1327 |
@software { mengzi-retrieval-lm-library ,
title = { {Mengzi-Retrieval-LM} } ,
author = { Wang, Yulong and Bo, Lin } ,
url = { https://github.com/Langboat/mengzi-retrieval-lm } ,
month = { 9 } ,
year = { 2022 } ,
version = { 0.0.1 } ,
}

