graph gpt
v0.4.0
이 저장소는 PyTorch에서 "GraphGPT: Generative Pre-trained Transformers를 사용한 그래프 학습"의 공식 구현입니다.
GraphGPT: 사전 훈련된 생성적 변환기를 사용한 그래프 학습
Qifang Zhao, Weidong Ren, Tianyu Li, Xiaoxiao Xu, Hong Liu
2024년 10월 13일
CHANGELOG.md 확인하세요.2024년 8월 18일
CHANGELOG.md 확인하세요.2024년 7월 9일
2024년 3월 19일
permute_nodes 구현합니다.StackedGSTTokenizer 를 추가하면 시퀀스 길이가 많이 줄어듭니다.2024년 1월 23일
2024년 1월 3일

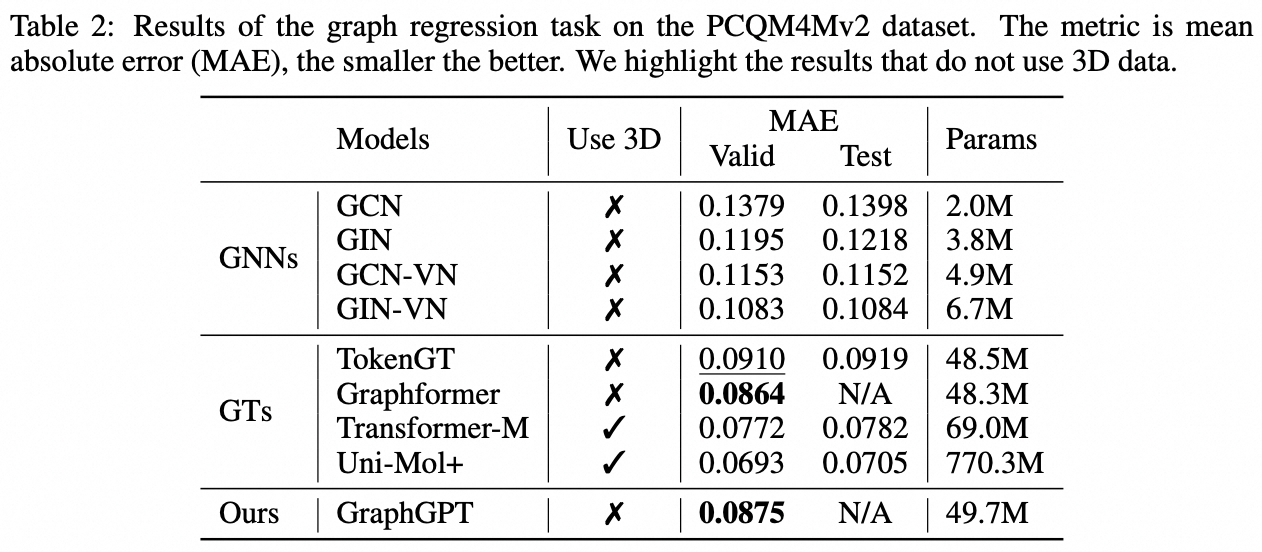
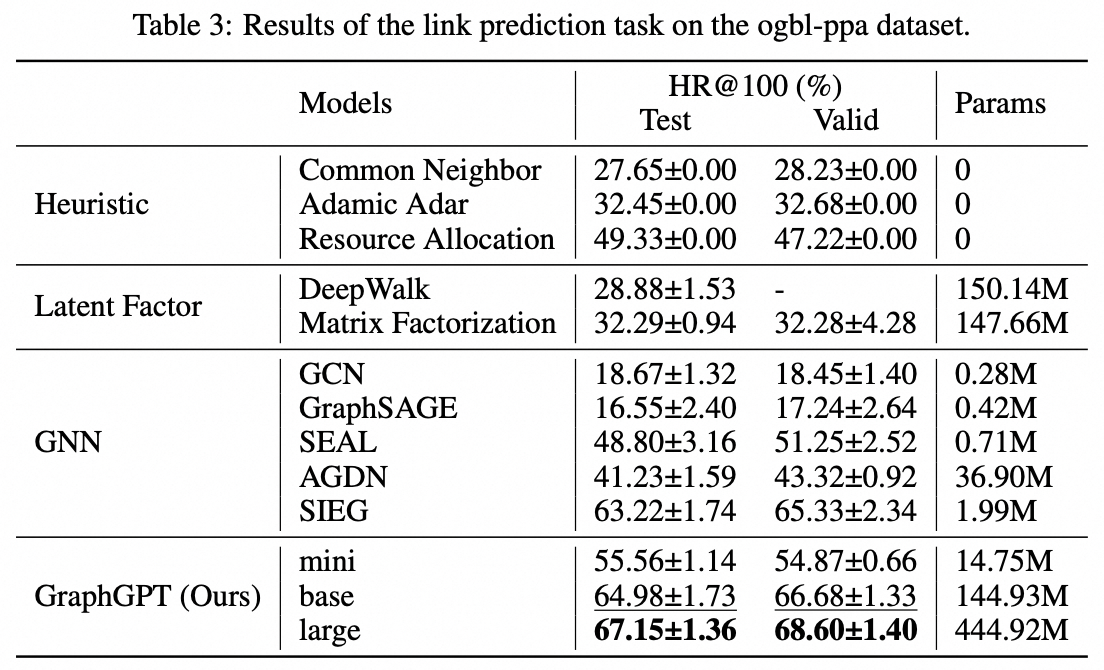
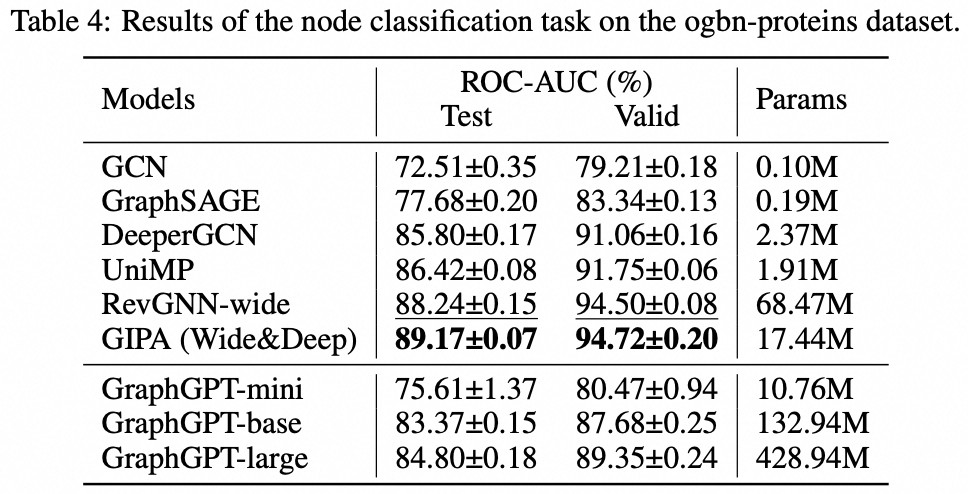
우리는 자기 지도형 생성적 사전 훈련 그래프 오일러 변환기(GET)를 통한 그래프 학습을 위한 새로운 모델인 GraphGPT를 제안합니다. 먼저 바닐라 변환기 인코더/디코더 백본과 각 그래프 또는 샘플링된 하위 그래프를 오일러 경로를 사용하여 가역적으로 노드, 에지 및 속성을 나타내는 토큰 시퀀스로 바꾸는 변환으로 구성된 GET을 소개합니다. 그런 다음 NTP(다음 토큰 예측) 작업 또는 SMTP(예약된 마스크 토큰 예측) 작업을 사용하여 GET을 사전 훈련합니다. 마지막으로 지도 작업을 통해 모델을 미세 조정합니다. 이 직관적이면서도 효과적인 모델은 단백질-단백질 연관 데이터 세트인 ogbl-ppa인 대규모 분자 데이터 세트 PCQM4Mv2에서 그래프, 에지 및 노드 수준 작업을 위한 최첨단 방법에 비해 우수하거나 유사한 결과를 달성합니다. , OGB(Open Graph Benchmark)의 인용 네트워크 데이터세트 ogbl-citation2 및 ogbn-단백질 데이터세트입니다. 또한 생성적 사전 훈련을 통해 GNN 및 이전 그래프 변환기의 기능을 뛰어넘는 지속적으로 성능이 향상되면서 최대 2B+ 매개변수까지 GraphGPT를 훈련할 수 있습니다.
오일러화된 그래프를 시퀀스로 변환한 후 노드 및 에지 속성을 시퀀스에 연결하는 여러 가지 방법이 있습니다. 우리는 이러한 메소드를 short , long , prolonged 으로 명명합니다.
그래프가 주어지면 먼저 오일러화한 다음 이를 동등한 시퀀스로 바꿉니다. 그런 다음 노드를 주기적으로 다시 인덱싱합니다.
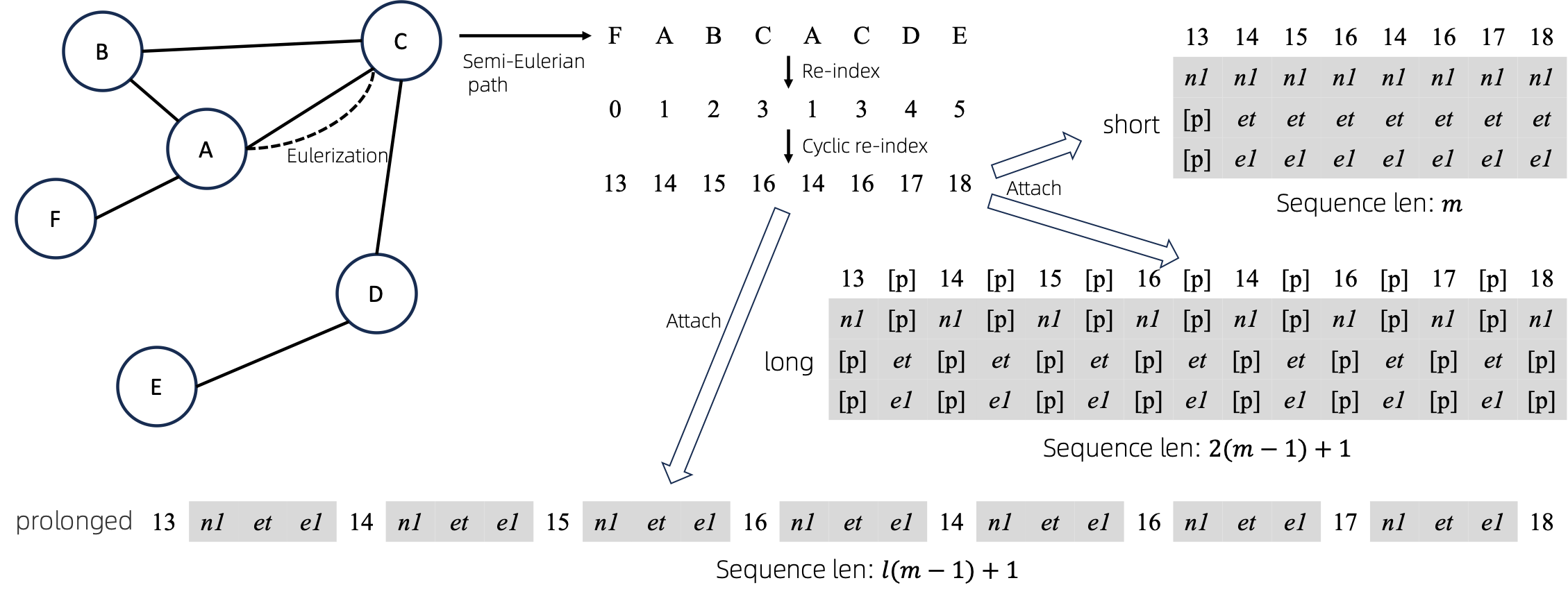
그래프에 하나의 노드 속성과 하나의 간선 속성이 있다고 가정하고 위에는 short , long 및 prolong 메서드가 나와 있습니다.
위 그림에서 n1 , n2 , e1 node 및 edge 속성의 토큰을 나타내고, [p] 패딩 토큰을 나타낸다.
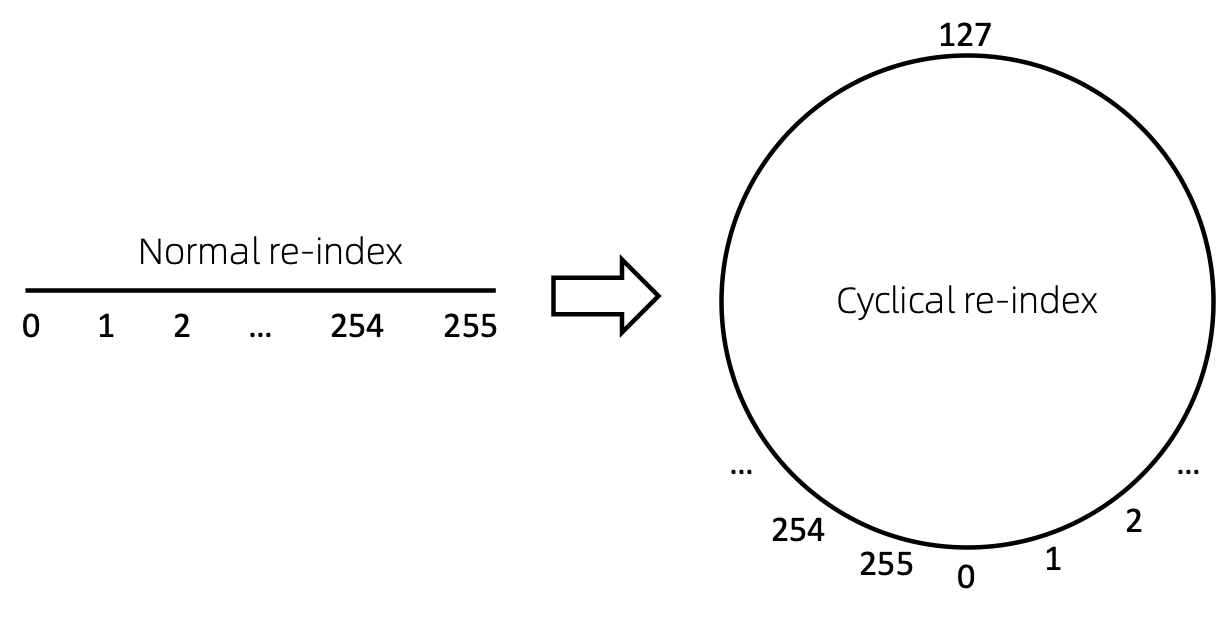
노드 시퀀스를 다시 인덱싱하는 간단한 방법은 0부터 시작하여 점진적으로 1을 추가하는 것입니다. 이러한 방식으로 작은 인덱스의 토큰은 충분히 훈련되지만 큰 인덱스는 그렇지 않습니다. 이를 극복하기 위해 우리는 주어진 범위(예 [0, 255] 의 난수로 시작하여 1씩 증가하는 cyclical re-index 제안합니다. 경계(예: 255 )에 도달한 후 다음 노드 인덱스는 0이 됩니다. .
구식. 곧 업데이트됩니다.
git clone https://github.com/alibaba/graph-gpt.gitconda create -n graph_gpt python=3.8 pytorch==1.13.1 torchvision==0.14.1 torchaudio==0.13.1 pytorch-cuda=11.7 -c pytorch -c nvidia
conda activate graph_gpt
cd graph-gpt
pip install -r ./requirements.txt
pip install torch-scatter torch-sparse -f https://data.pyg.org/whl/torch-1.13.1+cpu.html
sudo apt-get install bc데이터 세트는 Python 패키지 ogb를 사용하여 다운로드됩니다.
./examples 에서 스크립트를 실행하면 데이터세트가 자동으로 다운로드됩니다.
그러나 PCQM4M-v2 데이터 세트는 크기가 커서 다운로드 및 전처리에 문제가 있을 수 있습니다. 데이터 세트를 별도로 다운로드하고 전처리하려면 cd ./src/utils/ 및 python dataset_utils.py 권장합니다.
./examples/graph_lvl/pcqm4m_v2_pretrain.sh 에서 매개변수를 수정합니다(예: dataset_name , model_name , batch_size , workerCount 등). 그런 다음 ./examples/graph_lvl/pcqm4m_v2_pretrain.sh 실행하여 PCQM4M-v2로 모델을 사전 학습합니다. 데이터 세트../examples/toy_examples/reddit_pretrain.sh 를 직접 실행하세요../examples/graph_lvl/pcqm4m_v2_supervised.sh 에서 매개변수를 수정합니다(예: dataset_name , model_name , batch_size , workerCount , pretrain_cpt 등). 그런 다음 ./examples/graph_lvl/pcqm4m_v2_supervised.sh 실행하여 다운스트림 작업으로 미세 조정합니다. ../examples/toy_examples/reddit_supervised.sh 직접 실행하세요. .pre-commit-config.yaml : Python에 대해 다음 내용으로 파일을 생성합니다. repos :
- repo : https://github.com/pre-commit/pre-commit-hooks
rev : v4.4.0
hooks :
- id : check-yaml
- id : end-of-file-fixer
- id : trailing-whitespace
- repo : https://github.com/psf/black
rev : 23.7.0
hooks :
- id : blackpre-commit install : git 후크에 사전 커밋을 설치합니다.pre-commit install 실행하는 것이 항상 가장 먼저 수행되어야 합니다.pre-commit run --all-files : 저장소에서 모든 사전 커밋 후크를 실행합니다.pre-commit autoupdate : 후크를 최신 버전으로 자동 업데이트합니다.git commit -n : 다음 명령을 사용하여 특정 커밋에 대한 사전 커밋 검사를 비활성화할 수 있습니다. 이 작업이 유용하다고 생각되면 다음 논문을 친절하게 인용해 주세요.
@article{zhao2024graphgpt,
title={GraphGPT: Graph Learning with Generative Pre-trained Transformers},
author={Zhao, Qifang and Ren, Weidong and Li, Tianyu and Xu, Xiaoxiao and Liu, Hong},
journal={arXiv preprint arXiv:2401.00529},
year={2024}
}자오 치팡([email protected])
우리 작업에 대한 귀하의 제안에 진심으로 감사드립니다!
MIT 라이선스에 따라 출시됨( LICENSE 참조):
Ali-GraphGPT-project is an AI project on training large scale transformer decoder with graph datasets,
developed by Alibaba and licensed under the MIT License.


