VisualGLM 6B
1.0.0
? HF Repo • ⚒️ SwissArmyTransformer(토) • ?
• ? [CogView@NeurIPS 21] [GitHub] • ? [GLM@ACL 22] [GitHub]
Slack과 WeChat에 참여하세요
[2023.10] Zhipu AI의 차세대 다중 모달 대화 모델인 CogVLM(https://github.com/THUDM/CogVLM)에 주목해 주셔서 감사합니다. 이 모델은 시각 전문가의 새로운 아키텍처를 채택하여 10위를 차지했습니다. 권위 있는 고전적 다중 모드 작업. 현재 오픈 소스 CogVLM-17B 영어 모델은 GLM 오픈 소스 중국어 모델을 기반으로 합니다.
VisualGLM-6B는 이미지, 중국어 및 영어를 지원하는 오픈 소스 다중 모드 대화 상자 언어 모델입니다. 언어 모델은 62억 개의 매개변수가 있는 ChatGLM-6B를 기반으로 하며, 이미지 부분은 시각적 모델과 시각적 모델 사이에 다리를 구축합니다. BLIP2-Qformer 학습을 통한 언어 모델. 전체 모델은 78억 개의 매개변수로 구성됩니다. 영어 버전을 보려면 여기를 클릭하세요.
VisualGLM-6B는 이미지, 중국어, 영어를 지원하는 오픈 소스 다중 모드 대화 언어 모델입니다. 언어 모델은 ChatGLM-6B를 기반으로 하며 62억 개의 매개변수를 가지고 있습니다. 이미지 부분은 시각적 모델과 언어 모델 사이를 연결합니다. BLIP2-Qformer를 훈련함으로써 전체 모델은 총 78억 개의 매개변수를 갖게 됩니다.
VisualGLM-6B는 CogView 데이터 세트의 3천만 개의 고품질 중국어 이미지 및 텍스트 쌍을 사용하며 3억 개의 선별된 영어 이미지 및 텍스트 쌍으로 사전 학습되었습니다. 중국어와 영어의 가중치는 동일합니다. 이 학습 방법은 후속 미세 조정 단계에서 시각적 정보를 ChatGLM의 의미 공간에 더 잘 정렬하고, 모델은 긴 시각적 질문 및 답변 데이터를 학습하여 인간 선호도에 맞는 답변을 생성합니다.
VisualGLM-6B는 Transformer의 유연한 수정 및 훈련을 지원하고 Lora 및 P-tuning과 같은 매개변수의 효율적인 미세 조정 방법을 지원하는 도구 라이브러리인 SwissArmyTransformer(줄여서 sat ) 라이브러리에 의해 훈련됩니다. 본 프로젝트는 사용자 습관에 맞는 Huggingface 인터페이스를 제공하며, sat. 기반 인터페이스도 제공합니다.
모델 양자화 기술과 결합하여 사용자는 이를 소비자급 그래픽 카드에 로컬로 배포할 수 있습니다(최소 요구 사항은 INT4 양자화 수준에서 6.3G의 비디오 메모리입니다).
VisualGLM-6B 오픈 소스 모델은 오픈 소스 커뮤니티와 함께 대형 모델 기술 개발을 촉진하는 것을 목표로 합니다. 개발자와 모든 사람은 오픈 소스 계약을 준수하고 이 오픈 소스 모델과 이를 기반으로 하는 코드 및 파생물을 사용하지 마십시오. 국가와 사회에 해를 끼칠 수 있는 모든 목적을 가진 이 오픈 소스 프로젝트 및 안전 평가 및 문서화되지 않은 서비스를 유해하게 사용하는 행위. 현재 이 프로젝트에서는 웹 사이트, Android 앱, Apple iOS 애플리케이션, Windows 앱 등을 포함하여 VisualGLM-6B 기반 애플리케이션을 공식적으로 개발하지 않았습니다.
VisualGLM-6B는 아직 v1 버전이기 때문에 현재 이미지 설명 사실성/모델 환각 문제, 이미지 세부 정보 캡처 부족, 언어 모델의 일부 제한 사항 등 몇 가지 제한 사항이 있는 것으로 알려져 있습니다. 모델은 훈련의 모든 단계에서 데이터 규정 준수 및 정확성을 보장하기 위해 노력하지만 VisualGLM-6B 모델의 규모가 작고 모델이 확률 및 무작위 요인의 영향을 받는다는 사실로 인해 출력 내용의 정확성을 보장할 수 없습니다. , 모델은 쉽게 오해를 불러일으킬 수 있습니다(자세한 내용은 제한 사항 섹션 참조). VisualGLM의 후속 버전에서는 이러한 문제를 최적화하기 위한 노력이 이루어질 것입니다. 본 프로젝트는 오픈 소스 모델 및 코드 또는 모델이 오도, 남용, 유포 또는 부적절하게 악용되어 발생하는 데이터 보안 및 여론 위험으로 인해 발생하는 위험과 책임을 지지 않습니다.
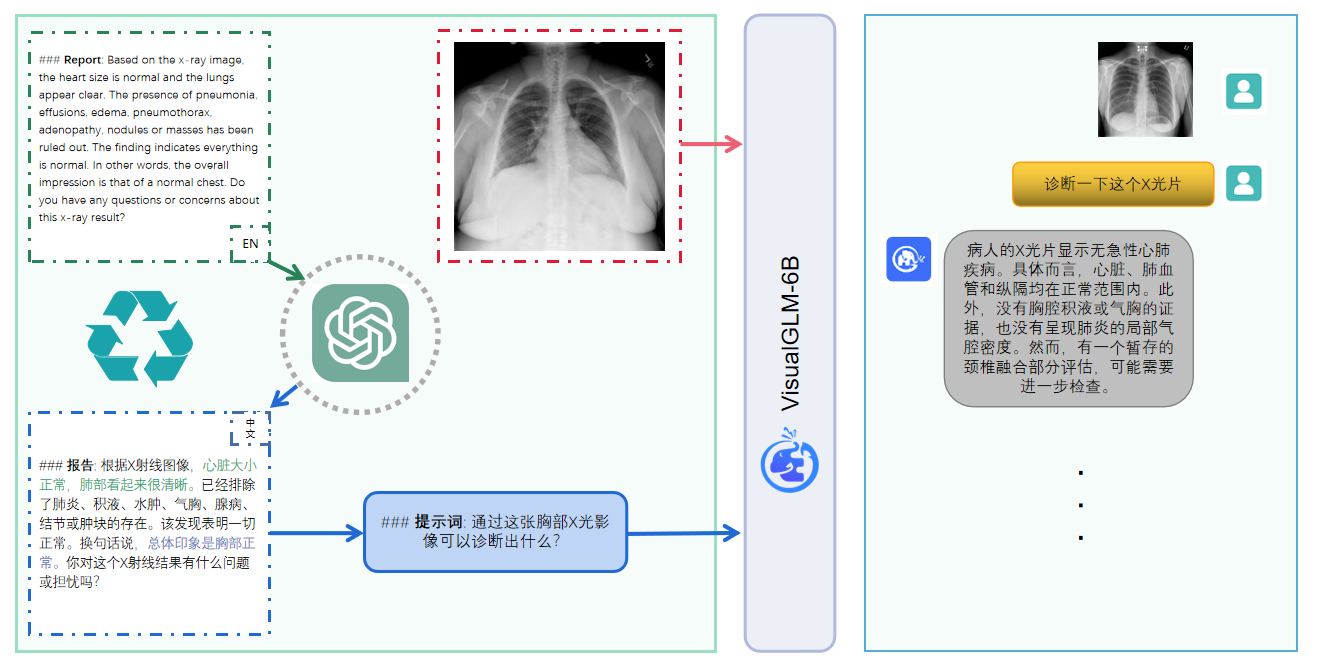
VisualGLM-6B는 이미지 설명 관련 지식에 대한 질의응답을 수행할 수 있습니다. 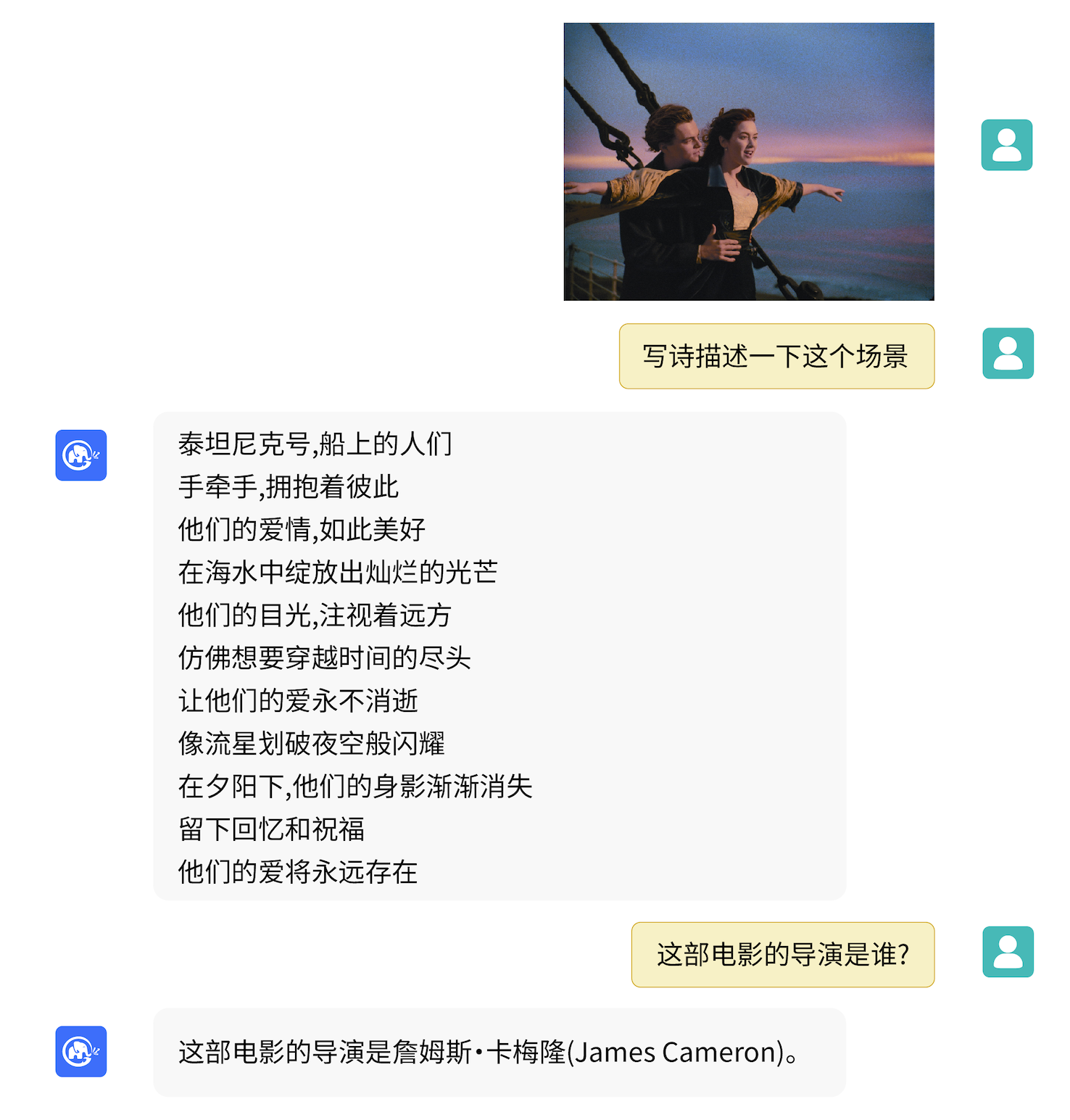



pip를 사용하여 종속성 설치
pip install -i https://pypi.org/simple -r requirements.txt
# 国内请使用aliyun镜像,TUNA等镜像同步最近出现问题,命令如下
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements.txt
이때 sat 라이브러리 교육을 지원하는 deepspeed 라이브러리가 기본적으로 설치됩니다. 이 라이브러리는 모델 추론에 필요하지 않습니다. 동시에 일부 Windows 환경에서는 이 라이브러리를 설치할 때 문제가 발생할 수 있습니다. deepspeed 설치를 우회하려면 명령을 다음과 같이 변경할 수 있습니다.
pip install -i https://mirrors.aliyun.com/pypi/simple/ -r requirements_wo_ds.txt
pip install -i https://mirrors.aliyun.com/pypi/simple/ --no-deps "SwissArmyTransformer>=0.4.4"
Huggingface 변환기 라이브러리를 사용하여 모델을 호출하는 경우( 위 종속성 패키지도 설치해야 합니다! ) 다음 코드를 전달할 수 있습니다(여기서 이미지 경로는 로컬 경로임).
from transformers import AutoTokenizer , AutoModel
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True )
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). half (). cuda ()
image_path = "your image path"
response , history = model . chat ( tokenizer , image_path , "描述这张图片。" , history = [])
print ( response )
response , history = model . chat ( tokenizer , image_path , "这张图片可能是在什么场所拍摄的?" , history = history )
print ( response ) 위의 코드는 transformers 에 의해 모델 구현 및 매개변수를 자동으로 다운로드합니다. 전체 모델 구현은 Hugging Face Hub에서 찾을 수 있습니다. Hugging Face Hub에서 모델 매개변수를 다운로드하는 속도가 느린 경우 여기에서 모델 매개변수 파일을 수동으로 다운로드하고 모델을 로컬로 로드할 수 있습니다. 구체적인 방법은 로컬에서 모델 로드를 참조하세요. 변환기 라이브러리 모델을 기반으로 한 수량화, CPU 추론, Mac MPS 백엔드 가속 등에 대한 자세한 내용은 ChatGLM-6B의 저비용 배포를 참조하세요.
SwissArmyTransformer 라이브러리를 사용하여 모델을 호출하는 경우 방법은 유사합니다. 환경 변수 SAT_HOME 사용하여 모델 다운로드 위치를 결정할 수 있습니다. 이 창고 디렉토리에서:
import argparse
from transformers import AutoTokenizer
tokenizer = AutoTokenizer . from_pretrained ( "THUDM/chatglm-6b" , trust_remote_code = True )
from model import chat , VisualGLMModel
model , model_args = VisualGLMModel . from_pretrained ( 'visualglm-6b' , args = argparse . Namespace ( fp16 = True , skip_init = True ))
from sat . model . mixins import CachedAutoregressiveMixin
model . add_mixin ( 'auto-regressive' , CachedAutoregressiveMixin ())
image_path = "your image path or URL"
response , history , cache_image = chat ( image_path , model , tokenizer , "描述这张图片。" , history = [])
print ( response )
response , history , cache_image = chat ( None , model , tokenizer , "这张图片可能是在什么场所拍摄的?" , history = history , image = cache_image )
print ( response ) sat 라이브러리를 사용하면 매개변수의 효율적인 미세 조정도 쉽게 수행할 수 있습니다.
다중 모드 작업은 광범위하게 분산되어 있으며 유형도 다양하므로 사전 교육으로 모든 것을 다룰 수 없는 경우가 많습니다. 여기에서는 20개의 주석이 달린 이미지를 사용하여 "배경" 질문에 답하는 모델의 능력을 향상시키는 소규모 샘플 미세 조정의 예를 제공합니다.
fewshot-data.zip 의 압축을 풀고 다음 명령을 실행하세요.
bash finetune/finetune_visualglm.sh
현재 세 가지 미세 조정 방법이 지원됩니다.
--layer_range 및 --lora_rank 매개변수는 특정 시나리오 및 데이터 볼륨에 따라 조정될 수 있습니다.bash finetune/finetune_visualglm_qlora.sh 사용을 고려할 수 있습니다. QLoRA는 ChatGLM의 선형 계층을 4비트로 양자화하고 미세 조정을 위해 9.8GB의 비디오 메모리만 필요합니다.--use_lora --use_ptuning 으로 바꿀 수 있지만 모델 적용 시나리오가 매우 고정되어 있지 않는 한 권장되지 않습니다.훈련 후에 추론을 위해 다음 명령을 사용할 수 있습니다.
python cli_demo.py --from_pretrained your_checkpoint_path --prompt_zh 这张图片的背景里有什么内容?
미세 조정하기 전:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:人们总是被生活琐事所困扰,无法摆脱束缚.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一张狗的图片,它躺在木地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是一台电脑键盘和两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
미세 조정 후:
欢迎使用 VisualGLM-6B 模型,输入图像URL或本地路径读图,继续输入内容对话,clear 重新开始,stop 终止程序
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/2p.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是雨天,
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了雨天的情景,雨水淅淅沥沥地落在地面上。人们穿着雨衣或雨伞,走在雨中,似乎在寻找着什么.
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/meme.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是木质地板。
用户:什么颜色的地板
VisualGLM-6B:这张图片的背景是蓝色的。
用户:描述一下这张图片。
VisualGLM-6B:这张图片描绘了一只棕色的小狗躺在蓝色的木质地板上。
用户:clear
请输入图像路径或URL(回车进入纯文本对话): fewshot-data/passport.png
用户:这张图片的背景里有什么内容?
VisualGLM-6B:这张图片的背景是电脑键盘。
用户:描述一下这张图片。
VisualGLM-6B:这张图片的特点是电脑键盘和护照。
用户:有几张护照
VisualGLM-6B:两张护照。
用户:clear
请输入图像路径或URL(回车进入纯文本对话):
LoRA 부분의 매개변수를 원래 가중치로 병합하려면 merge_lora() 호출하면 됩니다. 예를 들면 다음과 같습니다.
from finetune_visualglm import FineTuneVisualGLMModel
import argparse
model , args = FineTuneVisualGLMModel . from_pretrained ( 'checkpoints/finetune-visualglm-6b-05-19-07-36' ,
args = argparse . Namespace (
fp16 = True ,
skip_init = True ,
use_gpu_initialization = True ,
device = 'cuda' ,
))
model . get_mixin ( 'lora' ). merge_lora ()
args . layer_range = []
args . save = 'merge_lora'
args . mode = 'inference'
from sat . training . model_io import save_checkpoint
save_checkpoint ( 1 , model , None , None , args ) 미세 조정을 위해서는 deepspeed 라이브러리를 설치해야 합니다. 현재 이 프로세스는 Linux 시스템만 지원합니다. Windows 시스템에 대한 추가 샘플 지침과 프로세스 지침은 가까운 시일 내에 완료될 예정입니다.
python cli_demo.py 프로그램은 자동으로 sat 모델을 다운로드하고 명령줄에서 대화형 대화를 수행합니다. 대화 기록을 지우려면 명령을 입력하고 Enter를 눌러 프로그램을 종료합니다.
 이 프로그램은 생성 프로세스와 양자화 정확도를 제어하기 위해 다음과 같은 하이퍼파라미터를 제공합니다.
이 프로그램은 생성 프로세스와 양자화 정확도를 제어하기 위해 다음과 같은 하이퍼파라미터를 제공합니다.
usage: cli_demo.py [-h] [--max_length MAX_LENGTH] [--top_p TOP_P] [--top_k TOP_K] [--temperature TEMPERATURE] [--english] [--quant {8,4}]
optional arguments:
-h, --help show this help message and exit
--max_length MAX_LENGTH
max length of the total sequence
--top_p TOP_P top p for nucleus sampling
--top_k TOP_K top k for top k sampling
--temperature TEMPERATURE
temperature for sampling
--english only output English
--quant {8,4} quantization bits
훈련 중에 영어 질문과 답변 쌍의 프롬프트 단어는 Q: A: :인 반면, 중국어 프롬프트는问:答: 웹 데모에서는 중국어 프롬프트가 사용되므로 영어 응답이 더 나빠집니다. 필요한 경우 중국어와 혼합하여 영어로 답변하려면 cli_demo.py 에서 --english 옵션을 사용하세요.
ChatGLM-6B 에서 상속된 타자기 효과 명령줄 도구도 제공합니다. 이 도구는 Huggingface 모델을 사용합니다.
python cli_demo_hf.py모델 병렬 다중 카드 배포도 지원합니다. (sat의 최신 버전을 업데이트해야 합니다. 이전에 체크포인트를 다운로드한 경우 수동으로 삭제하고 다시 다운로드해야 합니다.)
torchrun --nnode 1 --nproc-per-node 2 cli_demo_mp.py
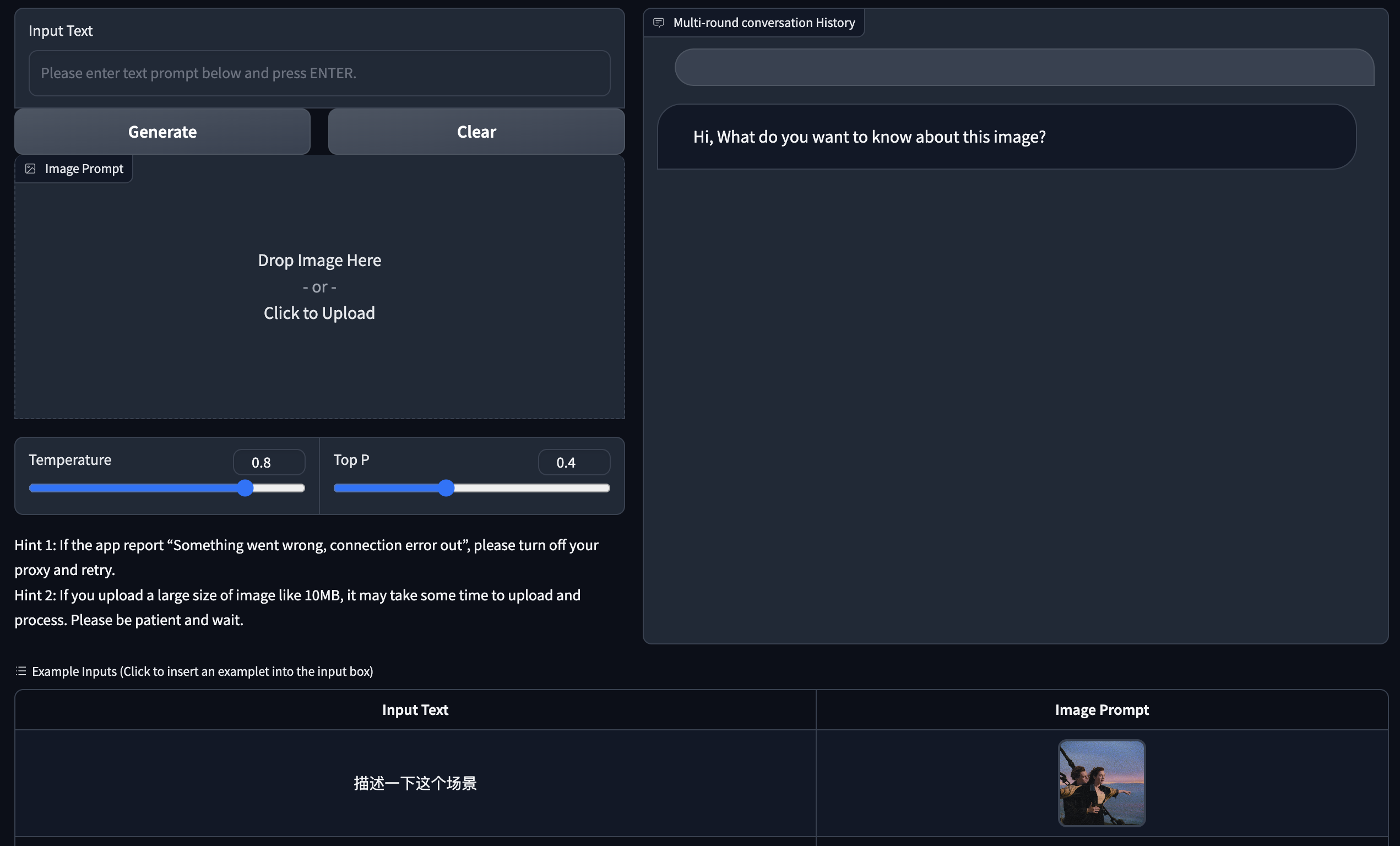
Gradio를 기반으로 한 웹 버전 데모를 제공합니다. 먼저 Gradio를 설치하세요: pip install gradio . 그런 다음 이 웨어하우스를 다운로드하고 입력하여 web_demo.py 실행하세요.
git clone https://github.com/THUDM/VisualGLM-6B
cd VisualGLM-6B
python web_demo.py
프로그램은 자동으로 sat 모델을 다운로드하고, 웹 서버를 실행하고, 주소를 출력합니다. 출력 주소를 브라우저에서 열어서 사용하세요.
ChatGLM-6B 에서 상속된 타자기 효과 웹 버전 도구도 제공됩니다. 이 도구는 Huggingface 모델을 사용하며 시작 후 포트 :8080 에서 실행됩니다.
python web_demo_hf.py 두 웹 버전 데모 모두 명령줄 매개변수 --share 허용하여 gradio 공개 링크를 생성하고, --quant 4 및 --quant 8 허용하여 각각 4비트 양자화/8비트 양자화를 사용하여 비디오 메모리 사용량을 줄입니다.
먼저, 추가 종속성을 설치해야 합니다 pip install fastapi uvicorn 그런 다음 웨어하우스에서 api.py를 실행해야 합니다.
python api.py 프로그램은 기본적으로 로컬 포트 8080에 배포되고 POST 메서드를 통해 호출되는 sat 모델을 자동으로 다운로드합니다. 다음은 curl 사용하여 요청하는 예입니다. 일반적으로 코드 메소드를 사용하여 POST를 수행할 수도 있습니다.
echo " { " image " : " $( base64 path/to/example.jpg ) " , " text " : "描述这张图片" , " history " :[]} " > temp.json
curl -X POST -H " Content-Type: application/json " -d @temp.json http://127.0.0.1:8080얻은 반환 값은 다음과 같습니다.
{
"response":"这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。",
"history":[('描述这张图片', '这张图片展现了一只可爱的卡通羊驼,它站在一个透明的背景上。这只羊驼长着一张毛茸茸的耳朵和一双大大的眼睛,它的身体是白色的,带有棕色斑点。')],
"status":200,
"time":"2023-05-16 20:20:10"
}
Huggingface 모델을 사용하는 api_hf.py도 제공되며, 사용법은 sat 모델의 API와 일치합니다.
python api_hf.pyHuggingface 구현에서 모델은 기본적으로 FP16 정밀도로 로드되며 위 코드를 실행하려면 약 15GB의 비디오 메모리가 필요합니다. GPU의 메모리가 제한되어 있는 경우 양자화 모드에서 모델을 로드해 볼 수 있습니다. 그것을 사용하는 방법:
# 按需修改,目前只支持 4/8 bit 量化。下面将只量化ChatGLM,ViT 量化时误差较大
model = AutoModel . from_pretrained ( "THUDM/visualglm-6b" , trust_remote_code = True ). quantize ( 8 ). half (). cuda () sat 구현에서는 먼저 매개변수를 전달하여 로딩 위치를 cpu 로 변경한 다음 수량화를 수행해야 합니다. 방법은 다음과 같습니다. 자세한 내용은 cli_demo.py 참조하세요.
from sat . quantization . kernels import quantize
quantize ( model , args . quant ). cuda ()
# 只需要 7GB 显存即可推理본 프로젝트는 V1 버전으로, 시각적 모델과 언어 모델의 매개변수와 계산량이 상대적으로 적습니다. 주요 개선 방향을 다음과 같이 정리했습니다.
이 저장소의 코드는 Apache-2.0 계약에 따른 오픈 소스입니다. VisualGLM-6B 모델의 가중치를 사용하려면 모델 라이센스를 준수해야 합니다.
우리 작업이 도움이 되었다고 생각하시면 다음 논문을 인용해 보세요.
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
@article{ding2021cogview,
title={Cogview: Mastering text-to-image generation via transformers},
author={Ding, Ming and Yang, Zhuoyi and Hong, Wenyi and Zheng, Wendi and Zhou, Chang and Yin, Da and Lin, Junyang and Zou, Xu and Shao, Zhou and Yang, Hongxia and others},
journal={Advances in Neural Information Processing Systems},
volume={34},
pages={19822--19835},
year={2021}
}
VisualGLM-6B의 명령 미세 조정 단계에 있는 데이터 세트에는 MiniGPT-4 및 LLAVA 프로젝트의 영어 그래픽 및 텍스트 데이터 일부와 많은 클래식 크로스 모달 작업 데이터 세트가 포함되어 있습니다. 기여.


