YAYI2
1.0.0

[읽어보기] [?HF Repo] [?웹 버전]
중국어 |
[2024.03.28] 모든 모델과 데이터는 매직 커뮤니티에 업로드됩니다.
[2023.12.22] 기술 보고서 YAYI 2: 다국어 오픈소스 대형 언어 모델을 출시했습니다.
YAYI 2는 Zhongke Wenge가 개발한 차세대 오픈 소스 대규모 언어 모델 로, 기본 및 채팅 버전을 포함하며 매개변수 크기는 30B입니다. YAYI2-30B는 사전 학습을 위해 2조 개 이상의 토큰으로 구성된 고품질 다국어 코퍼스를 사용하는 Transformer 기반의 대규모 언어 모델입니다. 일반 및 도메인별 애플리케이션 시나리오의 경우 미세 조정을 위해 수백만 개의 지침을 사용하고 인간 피드백 강화 학습 방법을 사용하여 모델을 인간 가치에 더 잘 맞춥니다.
이번에 오픈소스 모델은 YAYI2-30B Base 모델입니다. 우리는 Yayi 대형 모델 오픈소스를 통해 중국 사전 훈련된 대형 모델 오픈소스 커뮤니티의 발전을 촉진하고 이에 적극적으로 기여하기를 희망합니다. 오픈 소스를 통해 우리는 모든 파트너와 협력하여 Yayi 대형 모델 생태계를 구축합니다.
더 자세한 기술 정보는 기술 보고서 YAYI 2: 다국어 오픈 소스 대형 언어 모델을 참조하세요.
| 데이터 세트 이름 | 크기 | ?HF 모델 식별 | 주소 다운로드 | 매직 모델 로고 | 주소 다운로드 |
|---|---|---|---|---|---|
| YAYI2 사전 학습 데이터 | 500G | wenge-research/yayi2_pretrain_data | 데이터 세트 다운로드 | wenge-research/yayi2_pretrain_data | 데이터 세트 다운로드 |
| 모델명 | 컨텍스트 길이 | ?HF 모델 식별 | 주소 다운로드 | 매직 모델 로고 | 주소 다운로드 |
|---|---|---|---|---|---|
| YAYI2-30B | 4096 | wenge-연구/yayi2-30b | 모델 다운로드 | wenge-연구/yayi2-30b | 모델 다운로드 |
| YAYI2-30B-채팅 | 4096 | wenge-연구/yayi2-30b-채팅 | 곧 출시됩니다... |
우리는 C-Eval, MMLU, CMMLU, AGIEval, GAOKAO-Bench, GSM8K, MATH, BBH, HumanEval 및 MBPP를 포함한 여러 벤치마크 데이터 세트에 대한 평가를 수행했습니다. 우리는 언어 이해, 주제 지식, 수학적 추론, 논리적 추론 및 코드 생성에서 모델의 성능을 조사했습니다. YAYI 2 모델은 비슷한 규모의 오픈 소스 모델에 비해 상당한 성능 향상을 보여줍니다.
| 주제 지식 | 수학 | 논리적 추론 | 암호 | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 모델 | C-평가(val) | MMLU | AGI평가 | CMMLU | GAOKAO-벤치 | GSM8K | 수학 | BBH | 인간평가 | MBPP |
| 5발 | 5발 | 3/0샷 | 5발 | 0샷 | 8/4샷 | 4발 | 3발 | 0샷 | 3발 | |
| MPT-30B | - | 46.9 | 33.8 | - | - | 15.2 | 3.1 | 38.0 | 25.0 | 32.8 |
| 팔콘-40B | - | 55.4 | 37.0 | - | - | 19.6 | 5.5 | 37.1 | 0.6 | 29.8 |
| LLaMA2-34B | - | 62.6 | 43.4 | - | - | 42.2 | 6.2 | 44.1 | 22.6 | 33.0 |
| 바이촨2-13B | 59.0 | 59.5 | 37.4 | 61.3 | 45.6 | 52.6 | 10.1 | 49.0 | 17.1 | 30.8 |
| Qwen-14B | 71.7 | 67.9 | 51.9 | 70.2 | 62.5 | 61.6 | 25.2 | 53.7 | 32.3 | 39.8 |
| 인턴LM-20B | 58.8 | 62.1 | 44.6 | 59.0 | 45.5 | 52.6 | 7.9 | 52.5 | 25.6 | 35.6 |
| 아퀼라2-34B | 98.5 | 76.0 | 43.8 | 78.5 | 37.8 | 50.0 | 17.8 | 42.5 | 0.0 | 41.0 |
| Yi-34B | 81.8 | 76.3 | 56.5 | 82.6 | 68.3 | 67.6 | 15.9 | 66.4 | 26.2 | 38.2 |
| YAYI2-30B | 80.9 | 80.5 | 62.0 | 84.0 | 64.4 | 71.2 | 14.8 | 54.5 | 53.1 | 45.8 |
OpenCompass Github 저장소에서 제공하는 소스 코드를 사용하여 평가를 수행했습니다. 비교 모델의 경우 2023년 12월 15일 현재 OpenCompass 목록에 평가 결과가 나열되어 있습니다. MPT, Falcon, LLaMa 2 등 OpenCompass 플랫폼 평가에 참여하지 않은 다른 모델에 대해서는 LLaMA 2에서 보고한 결과를 채택했습니다.
추론을 위해 YAYI2-30B 빠르게 사용하는 방법을 설명하기 위해 간단한 예를 제공합니다. 이 예는 단일 A100/A800에서 실행할 수 있습니다.
git clone https://github.com/wenge-research/YAYI2.git
cd YAYI2conda create --name yayi_inference_env python=3.8
conda activate yayi_inference_env이 프로젝트에는 Python 3.8 이상이 필요합니다.
pip install transformers==4.33.1
pip install torch==2.0.1
pip install sentencepiece==0.1.99
pip install accelerate==0.25.0
>> > from transformers import AutoModelForCausalLM , AutoTokenizer
>> > tokenizer = AutoTokenizer . from_pretrained ( "wenge-research/yayi2-30b" , trust_remote_code = True )
>> > model = AutoModelForCausalLM . from_pretrained ( "wenge-research/yayi2-30b" , device_map = "auto" , trust_remote_code = True )
>> > inputs = tokenizer ( 'The winter in Beijing is' , return_tensors = 'pt' )
>> > inputs = inputs . to ( 'cuda' )
>> > pred = model . generate (
** inputs ,
max_new_tokens = 256 ,
eos_token_id = tokenizer . eos_token_id ,
do_sample = True ,
repetition_penalty = 1.2 ,
temperature = 0.4 ,
top_k = 100 ,
top_p = 0.8
)
>> > print ( tokenizer . decode ( pred . cpu ()[ 0 ], skip_special_tokens = True ))처음 방문하시는 경우, 모델을 다운로드 및 로딩해야 하며, 다소 시간이 걸릴 수 있습니다.
이 프로젝트는 분산 교육 프레임워크 deepspeed를 기반으로 하는 명령 미세 조정을 지원합니다. 환경을 구성하고 해당 스크립트를 실행하여 전체 매개변수 미세 조정 또는 LoRA 미세 조정을 시작합니다.
conda create --name yayi_train_env python=3.10
conda activate yayi_train_envpip install -r requirements.txtpip install --upgrade acceleratepip install flash-attn==2.0.3 --no-build-isolation
pip install triton==2.0.0.dev20221202 --no-deps 데이터 형식: 표준 JSON 파일인 data/yayi_train_example.json 을 참조하세요. 각 데이터는 "system" 과 "conversations" 로 구성됩니다. 여기서 "system" 은 전역 역할 설정 정보이며 빈 "conversations" 일 수 있습니다. "conversations" 는 인간과 야이 캐릭터 간의 여러 차례의 대화입니다.
작동 지침: Yayi 모델의 전체 매개변수 미세 조정을 시작하려면 다음 명령을 실행하십시오. 이 명령은 다중 시스템 및 다중 카드 교육을 지원합니다. 16*A100(80G) 이상의 하드웨어 구성을 사용하는 것이 좋습니다.
deepspeed --hostfile config/hostfile
--module training.trainer_yayi2
--report_to " tensorboard "
--data_path " ./data/yayi_train_example.json "
--model_name_or_path " your_model_path "
--output_dir " ./output "
--model_max_length 2048
--num_train_epochs 1
--per_device_train_batch_size 1
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " steps "
--save_steps 500
--save_total_limit 10
--learning_rate 5e-6
--warmup_steps 2000
--lr_scheduler_type cosine
--logging_steps 1
--gradient_checkpointing True
--deepspeed " ./config/deepspeed.json "
--bf16 True 또는 명령줄을 통해 시작하세요.
bash scripts/start.sh 지침 미세 조정을 위해 ChatML 템플릿을 사용해야 하는 경우 명령의 --module training.trainer_yayi2 --module training.trainer_chatml 로 변경할 수 있습니다. Chat 템플릿을 사용자 정의해야 하는 경우 수정할 수 있습니다. training_chatml.py의 채팅 템플릿에 있는 시스템 , 사용자 및 보조자라는 세 가지 역할에 대한 특수 토큰 정의입니다. 다음은 ChatML 템플릿의 예입니다. 훈련 중에 이 템플릿이나 사용자 정의 템플릿을 사용하는 경우 추론 중에도 일관성이 있어야 합니다.
<|im_start|>system
You are a helpful and harmless assistant named YAYI.<|im_end|>
<|im_start|>user
Hello!<|im_end|>
<|im_start|>assistant
Hello! How can I assist you today?<|im_end|>
<|im_start|>user
1+1=<|im_end|>
<|im_start|>assistant
1+1 equals 2.<|im_end|>
bash scripts/start_lora.sh 사전 훈련 단계에서는 모델의 언어 능력을 훈련시키기 위해 인터넷 데이터를 활용했을 뿐만 아니라, 모델의 전문 능력을 향상시키기 위해 일반 선택 데이터와 도메인 데이터를 추가했습니다. 데이터 분포는 다음과 같습니다. 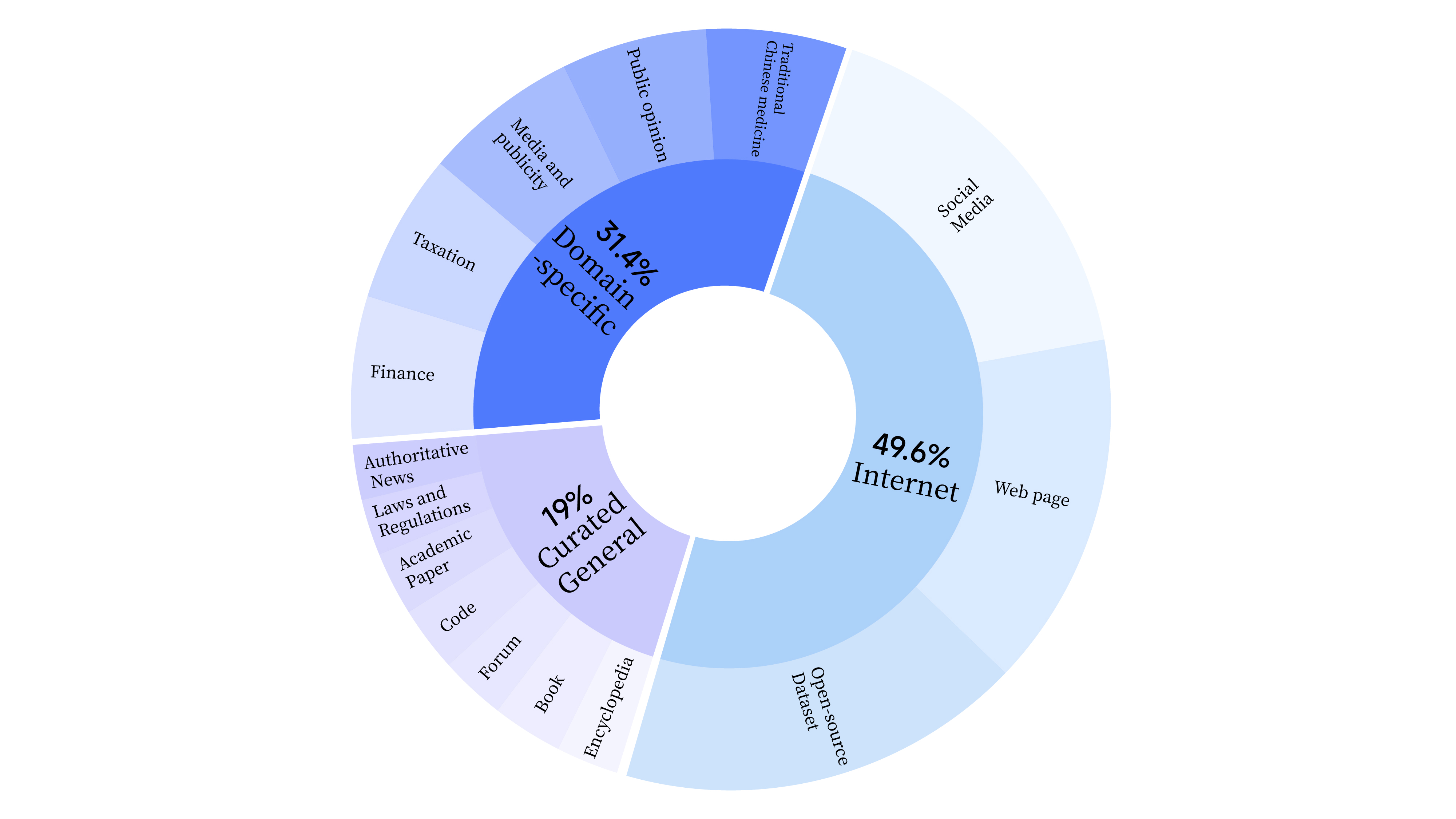
우리는 표준화, 경험적 정리, 다단계 중복 제거, 독성 필터링 등 4가지 모듈을 포함하여 모든 측면에서 데이터 품질을 개선하기 위한 일련의 데이터 처리 파이프라인을 구축했습니다. 총 240TB의 원시 데이터를 수집했고, 전처리 후에는 10.6TB의 고품질 데이터만 남았습니다. 전반적인 과정은 다음과 같습니다. 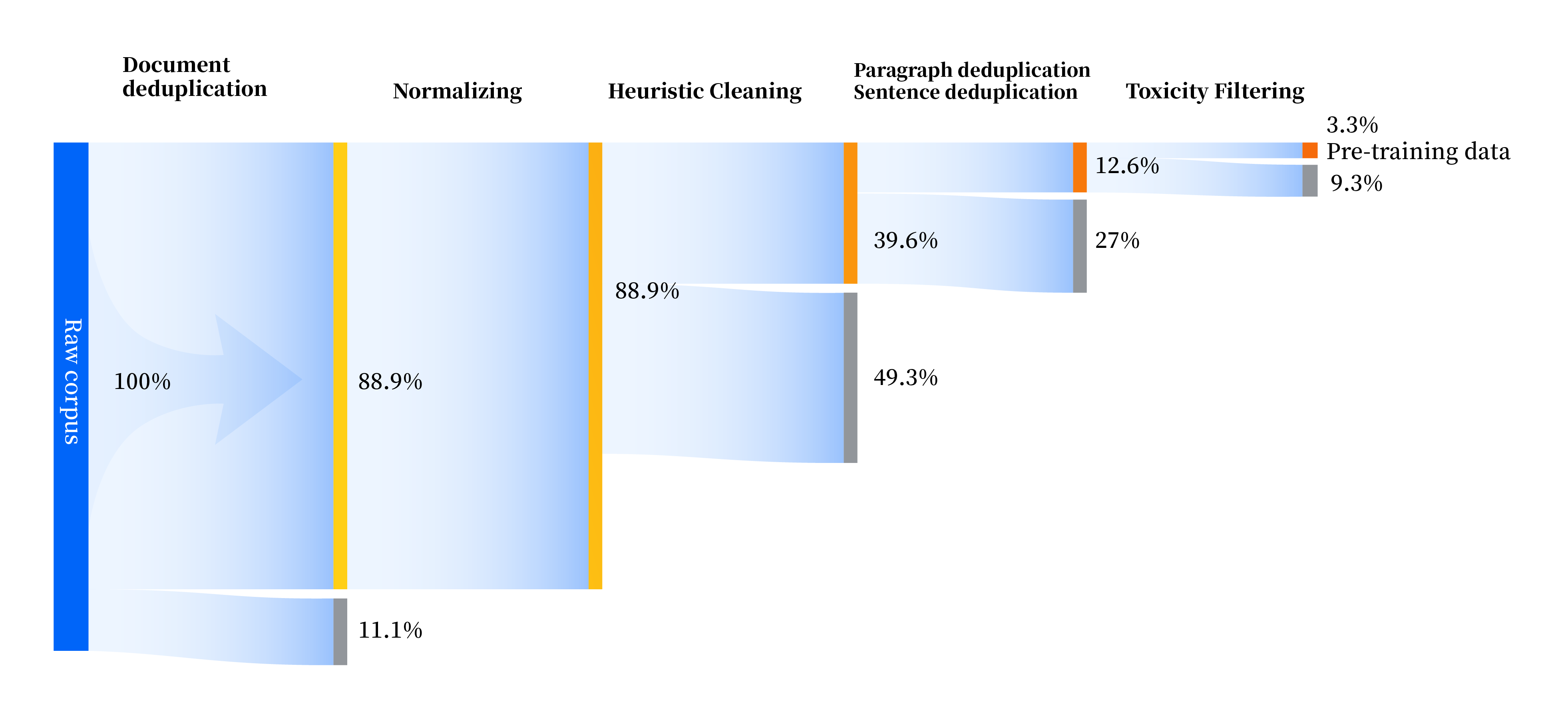

YAYI 2 모델의 손실 곡선은 아래 그림에 나와 있습니다. 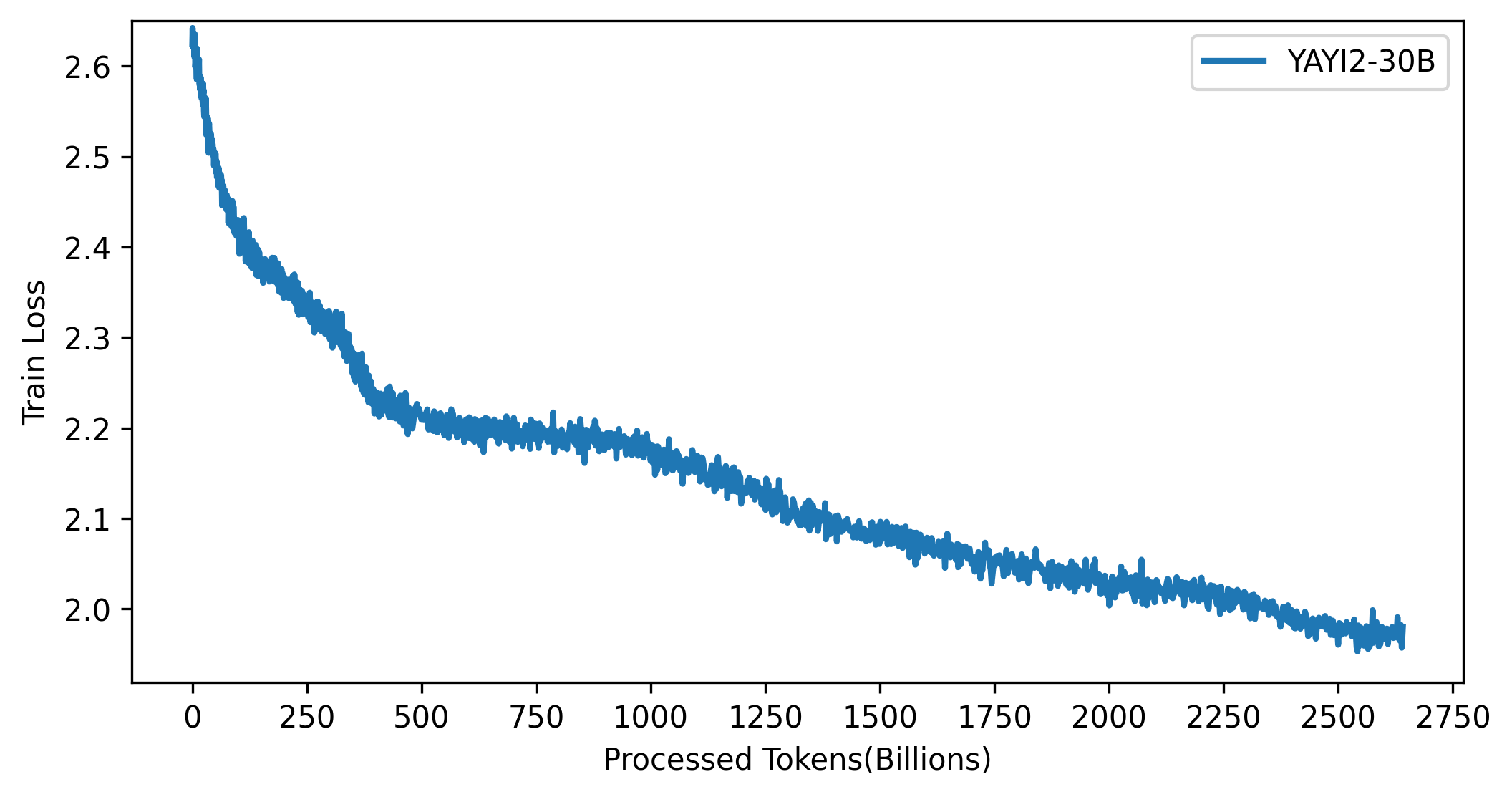
이 프로젝트의 코드는 Apache-2.0 프로토콜에 따른 오픈 소스입니다. 커뮤니티의 YAYI 2 모델 및 데이터 사용은 "Yayi YAYI 2 모델 커뮤니티 라이센스 계약"을 준수해야 합니다. YAYI 2 시리즈 모델 또는 그 파생 제품을 상업적 목적으로 사용해야 하는 경우 "YAYI 2 모델 상업 등록 정보"를 작성하여 [email protected]으로 보내주시면 이메일 수신 후 3영업일 이내에 답변해 드립니다. 검토는 매일 진행됩니다. 검토를 통과한 후에는 상업용 라이선스를 받게 됩니다. 사용 시 "YAYI 2 모델 상업용 라이선스 계약"의 관련 내용을 엄격히 준수하시기 바랍니다.
귀하의 작업에 우리 모델을 사용하는 경우, 우리 논문을 인용해 주십시오:
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}


