Copulas
v0.12.0 - 2024-11-12
이 저장소는 DataCebo의 프로젝트인 The Synthetic Data Vault Project의 일부입니다.

Copulas 는 다변량 분포를 모델링하고 코퓰러 함수를 사용하여 샘플링하기 위한 Python 라이브러리입니다. 수치 데이터 테이블이 주어지면 Copulas를 사용하여 분포를 학습하고 동일한 통계 속성에 따라 새로운 합성 데이터를 생성합니다.
주요 특징:
다변량 데이터를 모델링합니다. Archimedian Copulas, Gaussian Copulas 및 Vine Copulas를 포함한 다양한 일변량 분포 및 코퓰러 중에서 선택하십시오.
모델을 구축한 후 실제 데이터와 합성 데이터를 시각적으로 비교하세요 . 시각화는 1D 히스토그램, 2D 산점도 및 3D 산점도로 사용할 수 있습니다.
학습된 매개변수에 액세스하고 조작합니다. 모델 내부에 완벽하게 액세스하여 원하는 대로 매개변수를 설정하거나 조정하세요.
pip 또는 conda를 사용하여 Copulas 라이브러리를 설치합니다.
pip install copulasconda install -c conda-forge copulas데모 데이터 세트를 사용해 시작해 보세요. 이 데이터 세트에는 3개의 숫자 열이 포함되어 있습니다.
from copulas . datasets import sample_trivariate_xyz
real_data = sample_trivariate_xyz ()
real_data . head ()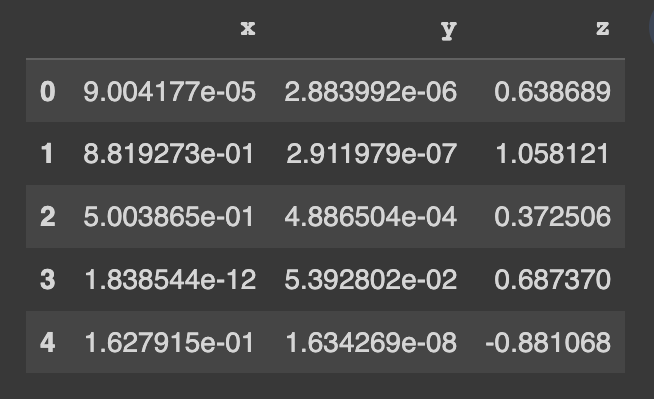
코퓰러를 사용하여 데이터를 모델링하고 이를 사용하여 합성 데이터를 생성합니다. Copulas 라이브러리는 Gaussian Copula, Vine Copulas 및 Archimedian Copulas를 포함한 다양한 옵션을 제공합니다.
from copulas . multivariate import GaussianMultivariate
copula = GaussianMultivariate ()
copula . fit ( real_data )
synthetic_data = copula . sample ( len ( real_data ))실제 데이터와 합성 데이터를 나란히 시각화합니다. 이 작업을 3D로 수행해 전체 데이터 세트를 살펴보겠습니다.
from copulas . visualization import compare_3d
compare_3d ( real_data , synthetic_data )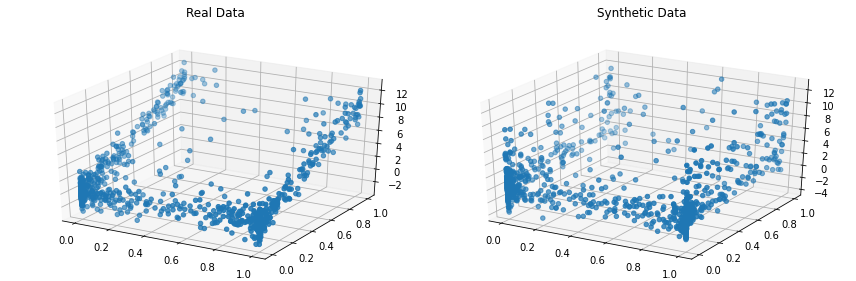
Colab Notebook에서 직접 코드를 실행하고 새로운 기능을 알아보려면 아래를 클릭하세요.
설명서 사이트에서 Copulas 라이브러리에 대해 자세히 알아보세요.
질문이나 문제가 있나요? Slack 채널에 참여하여 Copulas 및 합성 데이터에 대해 자세히 논의하세요. 버그를 발견하거나 기능 요청이 있는 경우 GitHub에서 문제를 열 수도 있습니다.
Copulas에 기여하는 데 관심이 있으십니까? 시작하려면 기여 가이드를 읽어보세요.
Copulas 오픈소스 프로젝트는 2018년 MIT의 Data to AI Lab에서 처음 시작되었습니다. 수년 동안 라이브러리를 구축하고 유지해 주신 기여자 팀에 감사드립니다!
기여자 보기

Synthetic Data Vault 프로젝트는 2016년 MIT의 Data to AI Lab에서 처음 만들어졌습니다. 4년간의 연구와 기업과의 견인 끝에 우리는 프로젝트 성장을 목표로 2020년 DataCebo를 만들었습니다. 현재 DataCebo는 합성 데이터 생성 및 평가를 위한 최대 규모의 생태계인 SDV의 자랑스러운 개발자입니다. 다음을 포함하여 합성 데이터를 지원하는 여러 라이브러리가 있습니다.
완전히 통합된 솔루션이자 합성 데이터를 위한 원스톱 상점인 SDV 패키지를 사용해 시작해 보세요. 또는 특정 요구 사항에 따라 독립 실행형 라이브러리를 사용하세요.


