ssebowa
1.0.0
Ssebawa는 다음을 포함한 생성적 AI 모델을 제공하는 오픈 소스 Python 라이브러리입니다.
ssebowa-llm: 텍스트 생성을 위한 LLM(대형 언어 모델),ssebowa-vllm: 시각적 이해를 위한 시각적 언어 모델(VLLM),ssebowa-imagen: 이미지 생성 및 맞춤형 미세 조정 모델,Ssebowa-vigen: 비디오 생성 모델.Ssebawa를 사용하면 쉽게 텍스트를 생성하고, 언어를 번역하고, 다양한 종류의 창의적인 콘텐츠를 작성하고, 개인화된 이미지를 생성하고, 유익한 방식으로 질문에 답할 수 있습니다.
자세한 사용법 정보는 Ssebawa 기술 문서를 참조하세요.
스크립트를 실행하기 전에 필요한 라이브러리가 설치되어 있는지 확인하십시오. 다음 명령을 실행하여 이를 수행할 수 있습니다.
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .그런 다음 Ssebowa를 설치하십시오.
pip install ssebowaColab 또는 jupyter Notebook에서 이 명령을 실행하는 경우 다음을 사용하세요.
! git clone https://github.com/huggingface/diffusers
! cd diffusers
! pip install .
! pip install ssebowa이제 라이브러리에서 모델을 가져와서 다양한 모델에 액세스할 수 있습니다.
Ssebawa-Imagen은 diffusion modeling 과 generative adversarial networks (GANs) 의 조합을 활용하여 text descriptions 에서 고품질 이미지를 생성하고 몇 장의 사진을 생성 가능한 custom model 로 전환할 수 있는 오픈 소스 이미지 합성 모델입니다. chosen subject 의 멋진 이미지. 100 billion dataset 활용하여 실제 이미지의 뉘앙스를 정확하게 포착하고 텍스트 설명을 매력적인 시각적 표현으로 효과적으로 변환할 수 있습니다.
10-20 high-quality 솔로 사진 (jpg or png) 을 10~20장 정도 준비하여 특정 디렉토리에 넣으세요.16GB or more GPU가 장착된 머신에서 실행하세요. (SDXL을 미세 조정하는 경우 24GB의 VRAM이 필요합니다.) from ssebowa.dataset import LocalDataset
from ssebowa.model import SdSsebowaModel
from ssebowa.trainer import LocalTrainer
from ssebowa.utils.image_helpers import display_images
from ssebowa.utils.prompt_helpers import make_promptDATA_DIR = " data " # The directory where you put your prepared photos
OUTPUT_DIR = " models " dataset = LocalDataset(DATA_DIR)
dataset = dataset.preprocess_images(detect_face=True)SUBJECT_NAME = " <YOUR-NAME> "
CLASS_NAME = " person " model = SdSsebowaModel(subject_name=SUBJECT_NAME, class_name=CLASS_NAME)
trainer = LocalTrainer(output_dir=OUTPUT_DIR)
predictor = trainer.fit(model, dataset)
# Use the prompt helper to create an awesome AI avatar!
prompt = next(make_prompt(SUBJECT_NAME, CLASS_NAME))
images = predictor.predict(
prompt, height=768, width=512, num_images_per_prompt=2,
)
display_images(images, fig_size=10)
from ssebowa import Ssebowa_imgen
model = Ssebowa_imgen ()예를 들어 "책장에 앉아 있는 고양이"를 생성해 보겠습니다.
image = model.generate_image( " A cat sitting on a bookshelf " )image.save( " cat_on_bookshelf.jpg " )

Ssebawa-vllm은 Ssebowa AI가 개발한 오픈 소스 VLLM(시각적 대형 언어 모델)입니다. 이미지를 이해하는 데 사용할 수 있는 강력한 도구입니다. Ssebawa-vllm은 110억 개의 시각적 매개변수와 70억 개의 언어 매개변수를 가지고 있으며 1120*1120 해상도에서 이미지 이해를 지원합니다.
from ssebowa import ssebowa_vllm
model = ssebowa_vllm ()
response = model.understand(image_path, prompt)
print(response)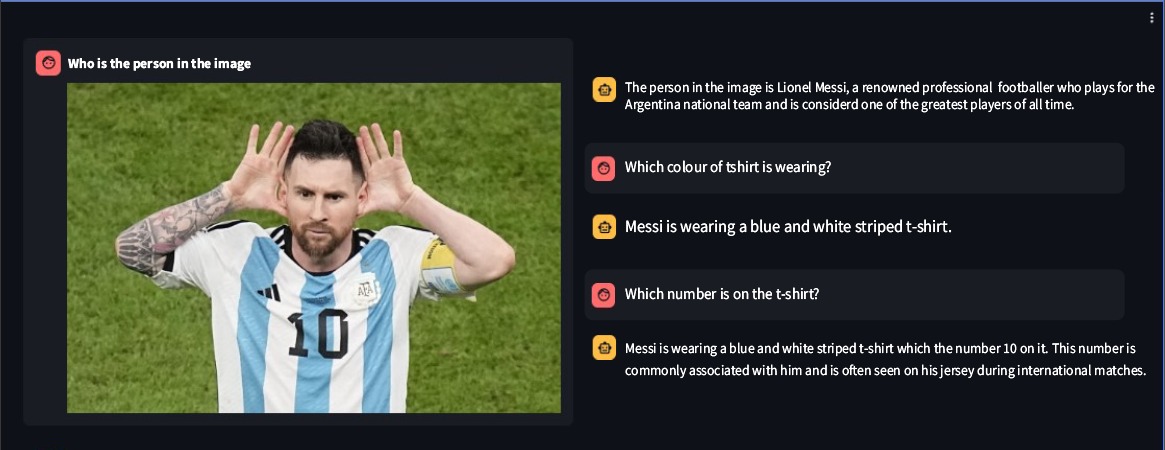
Ssebowa는 기여에 열려 있습니다! 가이드라인 진행중..
Ssebowa는 Apache License 2.0에 따라 출시됩니다.
질문이나 제안 사항이 있는 경우 언제든지 GitHub에서 문제를 공개하거나 [email protected]로 문의해 주세요.


