SynMeter
1.0.0

[2024년 11월 24일] SynMeter에 새로운 SOTA HP 합성기 REaLTabFormer를 추가합니다! 사용해 보세요!
[2024년 9월 18일] SynMeter에 새로운 SOTA HP 신디사이저 TabSyn을 추가합니다! 사용해 보세요!
새 Conda 환경을 만들고 설정합니다.
conda create -n synmeter python==3.9
conda activate synmeter
pip install -r requirements.txt # install dependencies
pip install -e . # package the library ./lib/info/ROOT_DIR 에서 기본 사전을 변경합니다.
ROOT_DIR = root_to_synmeter
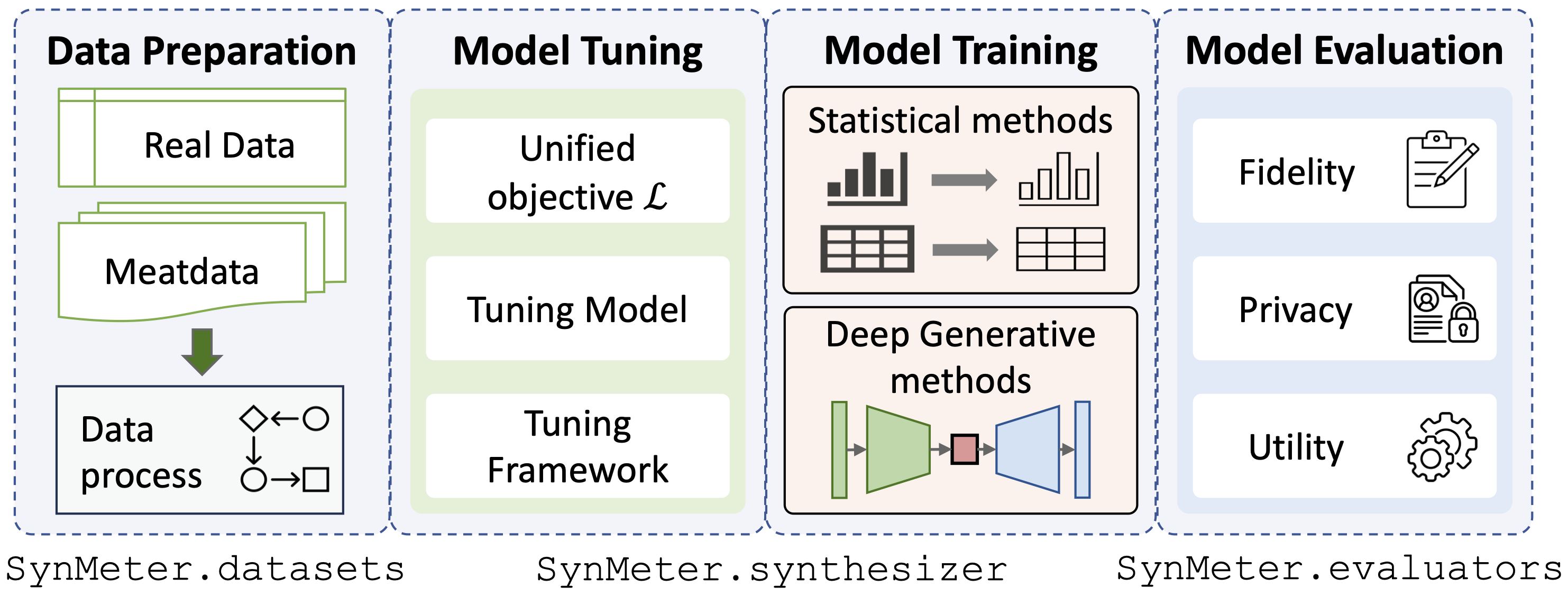
./dataset 에 넣어 쉽게 사용할 수도 있습니다../exp/evaluators 에서 제공합니다.python scripts/tune_evaluator.py -d [dataset] -c [cuda]우리는 모델 튜닝을 위한 통합된 튜닝 목표를 제공하므로 단 하나의 명령으로 모든 종류의 신디사이저를 튜닝할 수 있습니다.
python scripts/tune_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda] 조정 후 구성은 /exp/dataset/synthesizer 에 기록되어야 하며 SynMeter는 이를 사용하여 신디사이저를 훈련하고 저장할 수 있습니다.
python scripts/train_synthesizer.py -d [dataset] -m [synthesizer] -s [seed] -c [cuda]합성 데이터의 충실도 평가:
python scripts/eval_fidelity.py -d [dataset] -m [synthesizer] -s [seed] -t [target] 합성 데이터의 개인정보 보호 평가:
python scripts/eval_privacy.py -d [dataset] -m [synthesizer] -s [seed]합성 데이터의 유용성 평가:
python scripts/eval_utility.py -d [dataset] -m [synthesizer] -s [seed] 평가 결과는 해당 사전 /exp/dataset/synthesizer 아래에 저장되어야 합니다.
SynMeter의 한 가지 장점은 새로운 합성 알고리즘을 추가하는 가장 쉬운 방법을 제공한다는 것입니다. 세 단계가 필요합니다.
./synthesizer/my_synthesiszer 에 모듈식으로 새로운 합성 코드를 작성합니다../exp/base_config 에 기본 구성을 생성합니다../synthesizer 에 train , sample 및 tune 세 가지 함수가 포함된 호출 Python 함수를 만듭니다.그런 다음 새로운 신디사이저를 자유롭게 조정하고 실행하고 테스트할 수 있습니다!
| 방법 | 유형 | 설명 | 참조 |
|---|---|---|---|
| MST | DP | 이 방법은 확률적 그래픽 모델을 사용하여 데이터 합성에 대한 저차원 한계의 의존성을 학습합니다. | 종이, 코드 |
| PrivSyn | DP | 합성 데이터 세트를 반복적으로 업데이트하여 목표 잡음 한계와 일치하도록 만드는 비모수적 DP 합성기입니다. | 종이, 코드 |
| 방법 | 유형 | 설명 | 참조 |
|---|---|---|---|
| CTGAN | HP | 표 형식 데이터를 처리할 수 있는 조건부 생성 적대 신경망입니다. | 종이, 코드 |
| 파테간 | DP | 이 방법은 PATE(Private Aggregation of Teacher Ensembles) 프레임워크를 사용하고 이를 GAN에 적용합니다. | 종이, 코드 |
| 방법 | 유형 | 설명 | 참조 |
|---|---|---|---|
| TVAE | HP | 표 형식의 데이터를 처리할 수 있는 조건부 VAE 네트워크입니다. | 종이, 코드 |
| 방법 | 유형 | 설명 | 참조 |
|---|---|---|---|
| 탭DDPM | HP | 표 형식 데이터 합성을 위해 확산 모델 사용 | 종이, 코드 |
| 탭신 | HP | 합성을 위해 잠재 확산 모델과 VAE를 사용합니다. | 종이, 코드 |
| 테이블확산 | DP | 차등 개인 정보 보호 하에서 테이블 형식 데이터 세트를 생성합니다. | 종이, 코드 |
| 방법 | 유형 | 설명 | 참조 |
|---|---|---|---|
| 엄청난 | HP | LLM을 사용하여 테이블 형식 데이터 세트를 미세 조정합니다. | 종이, 코드 |
| REaLTab이전 | HP | GPT-2를 사용하여 표 형식 데이터의 관계 종속성을 학습합니다. | 종이, 코드 |
충실도 메트릭 : 우리는 Wasserstein 거리를 모든 단방향 및 양방향 한계에 의해 계산되는 원칙적인 충실도 메트릭으로 간주합니다.
개인 정보 보호 지표 : HP와 DP 신디사이저 모두의 회원 개인 정보 보호 위험을 측정하기 위해 MDS(회원 공개 점수)를 고안했습니다.
유틸리티 지표 : 우리는 기계 학습 친화력과 쿼리 오류를 사용하여 합성 데이터의 유용성을 측정합니다.
자세한 내용과 사용법은 당사의 문서를 참조하세요.
이 프로젝트에는 많은 우수한 합성 알고리즘과 오픈 소스 라이브러리가 사용됩니다.


