QuillGPT
1.0.0

QuillGPT는 Vaswani 등의 Attention is All You Need 논문의 아키텍처를 기반으로 하는 GPT 디코더 블록의 구현입니다. 알. PyTorch에서 구현되었습니다. 또한 이 저장소에는 훈련된 가중치와 함께 두 가지 사전 훈련된 모델(Shakespearean GPT 및 Harpoon GPT)이 포함되어 있습니다. 실험과 배포를 쉽게 하기 위해 이러한 모델과 확장 가능한 배포를 위해 Docker 컨테이너화로 구현된 FastAPI 마이크로서비스를 대화형으로 탐색할 수 있는 Streamlit Playground가 제공됩니다. 또한 훈련된 모델을 보여주는 노트북과 함께 새로운 GPT 모델을 훈련하고 추론을 수행하기 위한 Python 스크립트도 찾을 수 있습니다. 텍스트 인코딩 및 디코딩을 용이하게 하기 위해 간단한 토크나이저가 구현됩니다. QuillGPT를 탐색하여 이러한 도구를 활용하고 자연어 처리 프로젝트를 향상시키십시오!
이 저장소에는 두 가지 사전 훈련된 모델과 가중치가 포함되어 있습니다.
| 특징 | 셰익스피어 GPT | 하푼 GPT |
|---|---|---|
| 매개변수 | 10.7M | 226M |
| 가중치 | 가중치 | 가중치 |
| 모델 구성 | 구성 | 구성 |
| 훈련 데이터 | 셰익스피어 연극의 텍스트(input.txt) | 책의 임의 텍스트(corpus.txt) |
| 임베딩 유형 | 문자 임베딩 | 문자 임베딩 |
| 교육용 노트북 | 공책 | 공책 |
| 하드웨어 | 엔비디아 T4 | 엔비디아 A100 |
| 훈련 및 검증 손실 | 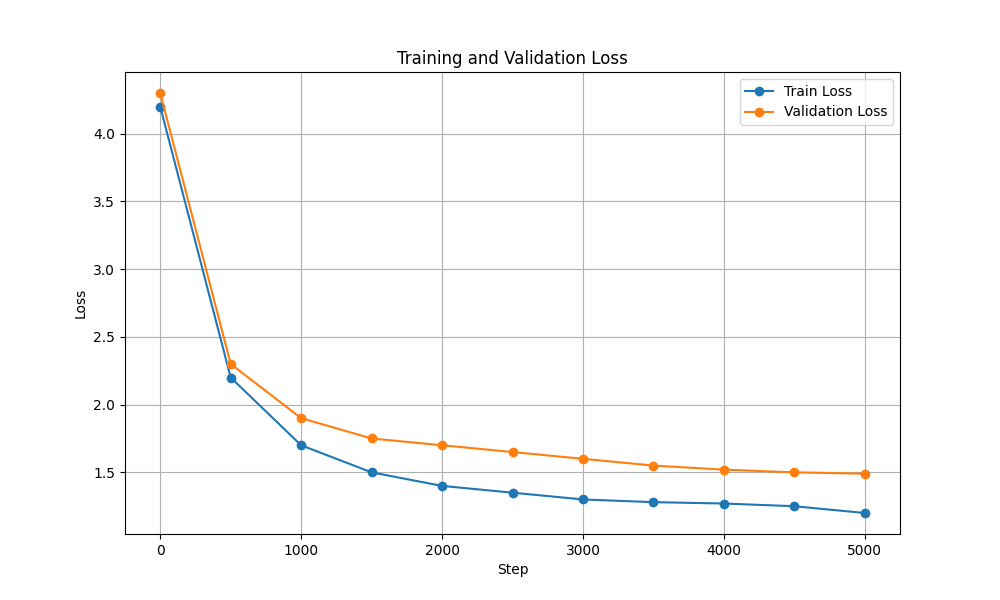 | 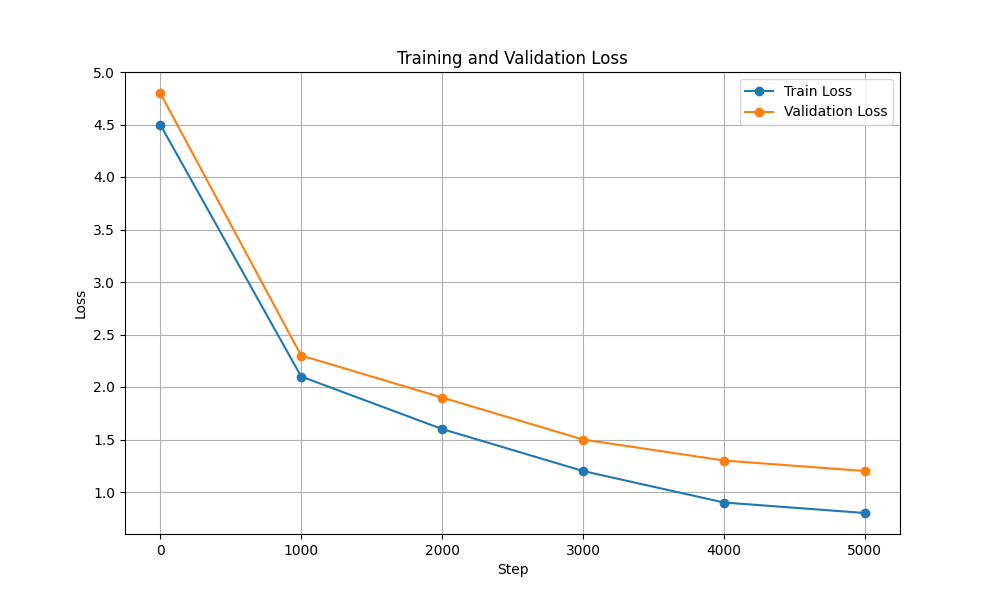 |
학습 및 추론 스크립트를 실행하려면 다음 단계를 따르세요.
git clone https://github.com/NotShrirang/GPT-From-Scratch.git
cd GPT-From-Scratchpip install -r requirements.txt계속하기 전에 여기에서 Harpoon GPT의 가중치를 다운로드했는지 확인하세요!
Streamlit Cloud Service에서 호스팅됩니다. 여기 링크를 통해 방문하실 수 있습니다.
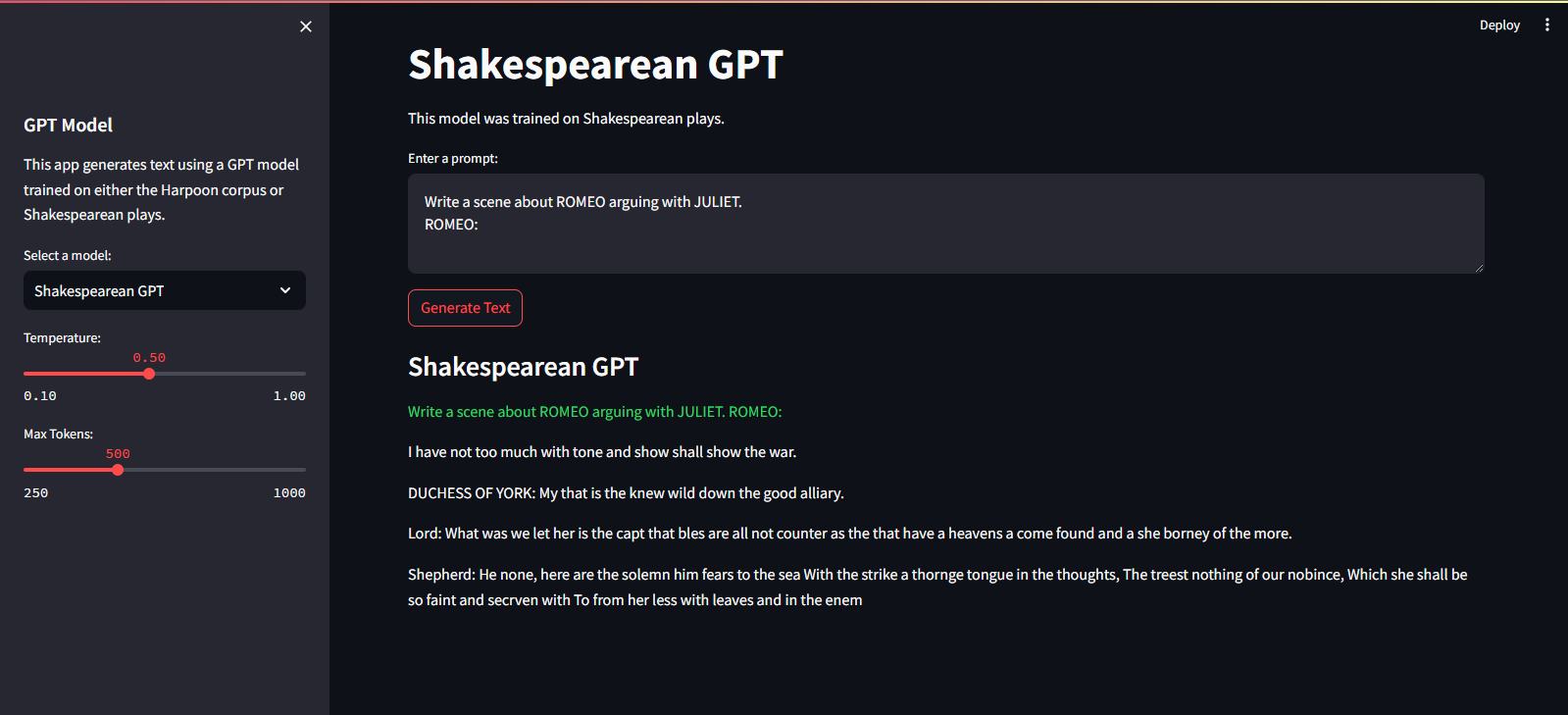
streamlit run app.pypython main.py./run.sh start-dev./run.sh stop-devGPT 모델을 학습하려면 다음 단계를 따르세요.
데이터를 준비합니다. 전체 텍스트 데이터를 단일 .txt 파일에 넣고 저장합니다.
변환기 구성을 작성하고 파일을 저장합니다.
예: json { "data_path": "data/corpus.txt", "vocab_size": 135, "batch_size": 32, "block_size": 256, "max_iters": 3000, "eval_interval": 300, "learning_rate": 3e-5, "eval_iters": 50, "n_embd": 1024, "n_head": 12, "n_layer": 18, "dropout": 0.3, }
스크립트 scripts/train_gpt.py 사용하여 모델 훈련
python scripts/train_gpt.py
--config_path config/config.json
--data_path data/corpus.txt
--output_dir trained_models (요구 사항에 따라 config_path , data_path 및 output_dir 변경할 수 있습니다.)
output_dir 에 저장됩니다.훈련 후에는 텍스트 생성을 위해 훈련된 GPT 모델을 사용할 수 있습니다. 다음은 추론을 위해 훈련된 모델을 사용하는 예입니다.
python scripts/inference_gpt.py
--config_path config/shakespearean_config.json
--weights_path weights/GPT_model_char.pt
--max_length 500
--prompt " Once upon a time " 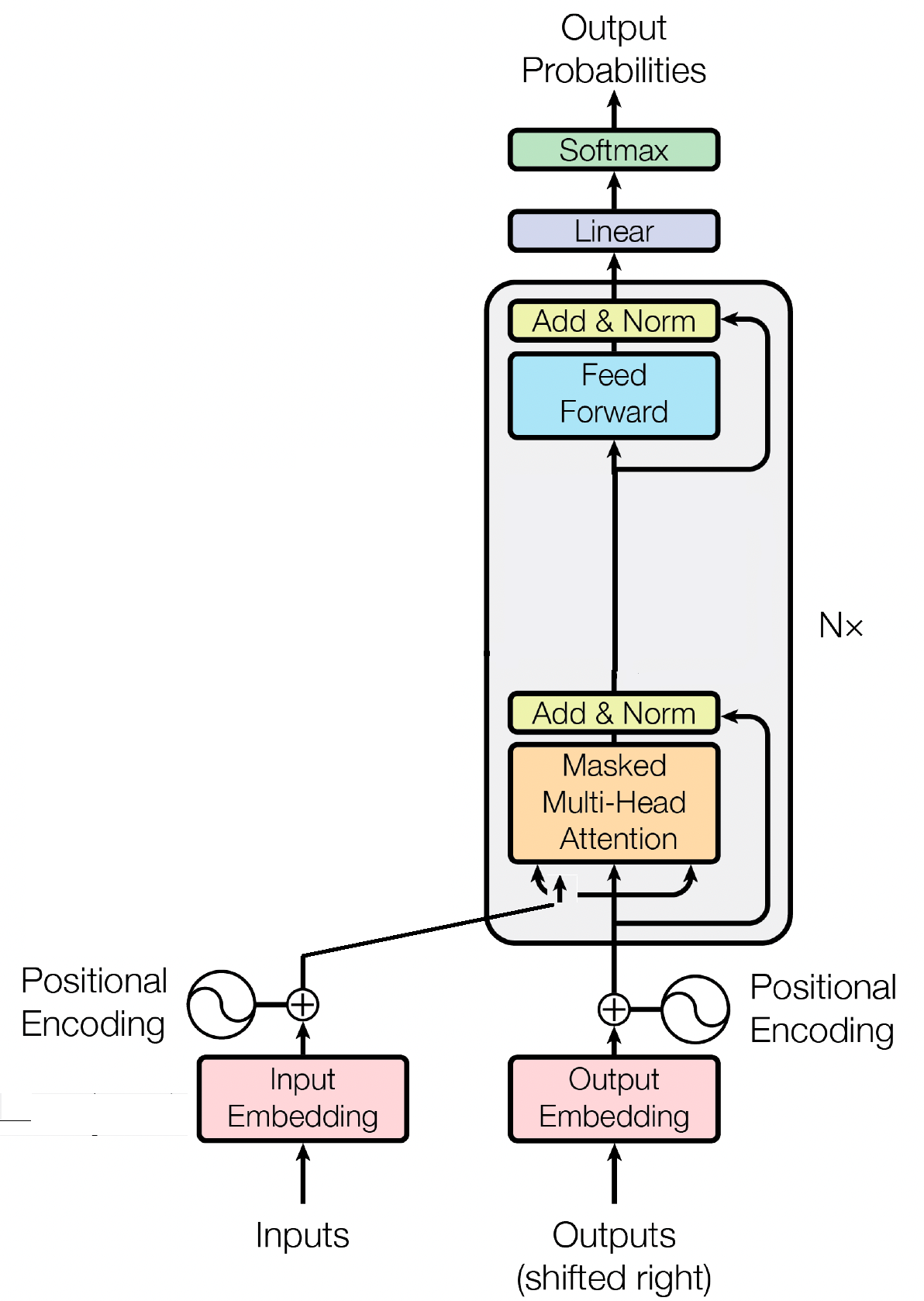
디코더 블록은 GPT(Generative Pre-trained Transformer) 모델의 중요한 구성 요소이며, GPT가 실제로 텍스트를 생성하는 곳입니다. Self-Attention 메커니즘을 활용하여 입력 시퀀스를 처리하고 일관된 출력을 생성합니다. 각 디코더 블록은 self-attention 레이어, 피드포워드 신경망 및 레이어 정규화를 포함한 여러 레이어로 구성됩니다. Self-Attention 레이어를 사용하면 모델이 시퀀스에서 다양한 단어의 중요성을 평가하여 위치에 관계없이 컨텍스트와 종속성을 포착할 수 있습니다. 이를 통해 GPT 모델은 상황에 맞는 텍스트를 생성할 수 있습니다.
입력 임베딩은 입력 토큰을 의미 있는 숫자 표현으로 변환하여 GPT와 같은 변환기 기반 모델에서 중요한 역할을 합니다. 이러한 임베딩은 모델의 초기 입력 역할을 하며 시퀀스의 단어에 대한 의미 정보를 캡처합니다. 이 프로세스에는 입력 시퀀스의 각 토큰을 유사한 토큰이 서로 더 가깝게 배치되는 고차원 벡터 공간에 매핑하는 작업이 포함됩니다. 이를 통해 모델은 서로 다른 단어 간의 관계를 이해하고 입력 데이터로부터 효과적으로 학습할 수 있습니다. 그런 다음 입력 임베딩은 추가 처리를 위해 모델의 후속 레이어에 공급됩니다.
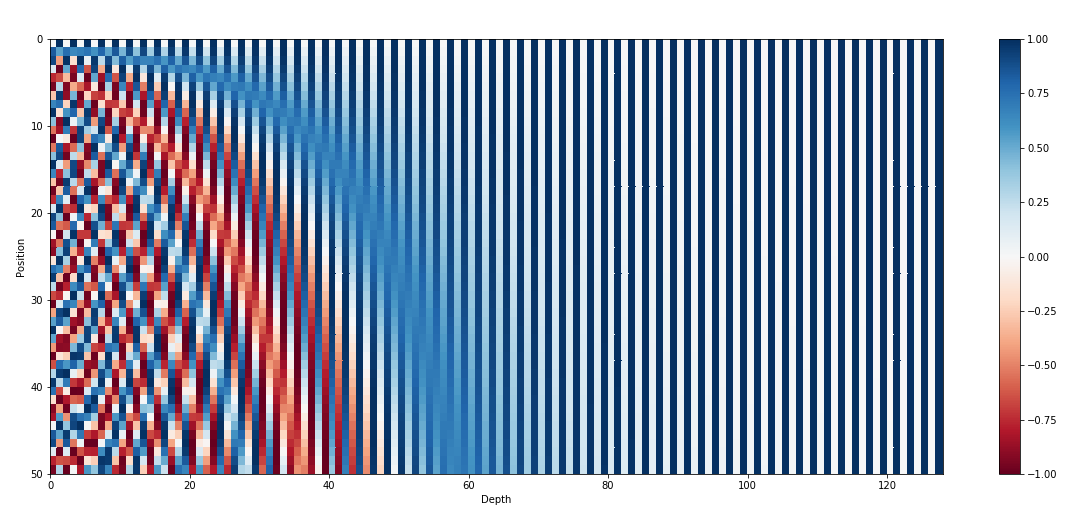
입력 임베딩 외에도 위치 임베딩은 GPT와 같은 변환기 아키텍처의 또 다른 중요한 구성 요소입니다. 변환기에는 시퀀스의 토큰 순서에 대한 고유 정보가 부족하므로 모델에 위치 정보를 제공하기 위해 위치 임베딩이 도입되었습니다. 이러한 임베딩은 시퀀스 내 각 토큰의 위치를 인코딩하여 모델이 위치에 따라 토큰을 구별할 수 있도록 합니다. 위치 임베딩을 통합함으로써 GPT와 같은 변환기는 데이터의 순차적 특성을 효과적으로 캡처하고 생성된 텍스트에서 올바른 단어 순서를 유지하는 일관된 출력을 생성할 수 있습니다.

GPT와 같은 변환기 기반 모델의 기본 메커니즘인 Self-attention은 중요도 점수를 순서대로 다른 단어에 할당하는 방식으로 작동합니다. 이 프로세스에는 주의 점수 계산, 주의 가중치를 얻기 위한 소프트맥스 적용, 마지막으로 이러한 가중치를 입력 임베딩과 결합하여 상황에 맞는 표현을 생성하는 세 가지 주요 단계가 포함됩니다. 기본적으로 self-attention을 사용하면 모델이 관련 단어에 더 집중하고 덜 중요한 단어는 덜 강조하여 입력 데이터 내의 상황별 종속성에 대한 효과적인 학습을 촉진할 수 있습니다. 이 메커니즘은 장거리 종속성과 상황별 뉘앙스를 캡처하는 데 중추적인 역할을 하여 변환기 모델이 긴 텍스트 시퀀스를 생성할 수 있도록 합니다.
MIT © Shrirang Mahajan
자유롭게 끌어오기 요청을 제출하고, 이슈를 생성하고, 소문을 퍼뜨리세요!
이 저장소에 별표를 표시하면 저를 지원해 주세요!


