AttackVLM
1.0.0
[프로젝트 페이지] | [슬라이드] | [arXiv] | [데이터 저장소]
In this research, we evaluate the adversarial robustness of recent large vision-language (generative) models (VLMs), under the most realistic and challenging setting with threat model of black-box access and targeted goal.
Our proposed method aims for the targeted response generation over large VLMs such as MiniGPT-4, LLaVA, Unidiffuser, BLIP/2, Img2Prompt, etc.
In other words, we mislead and let the VLMs say what you want, regardless of the content of the input image query.

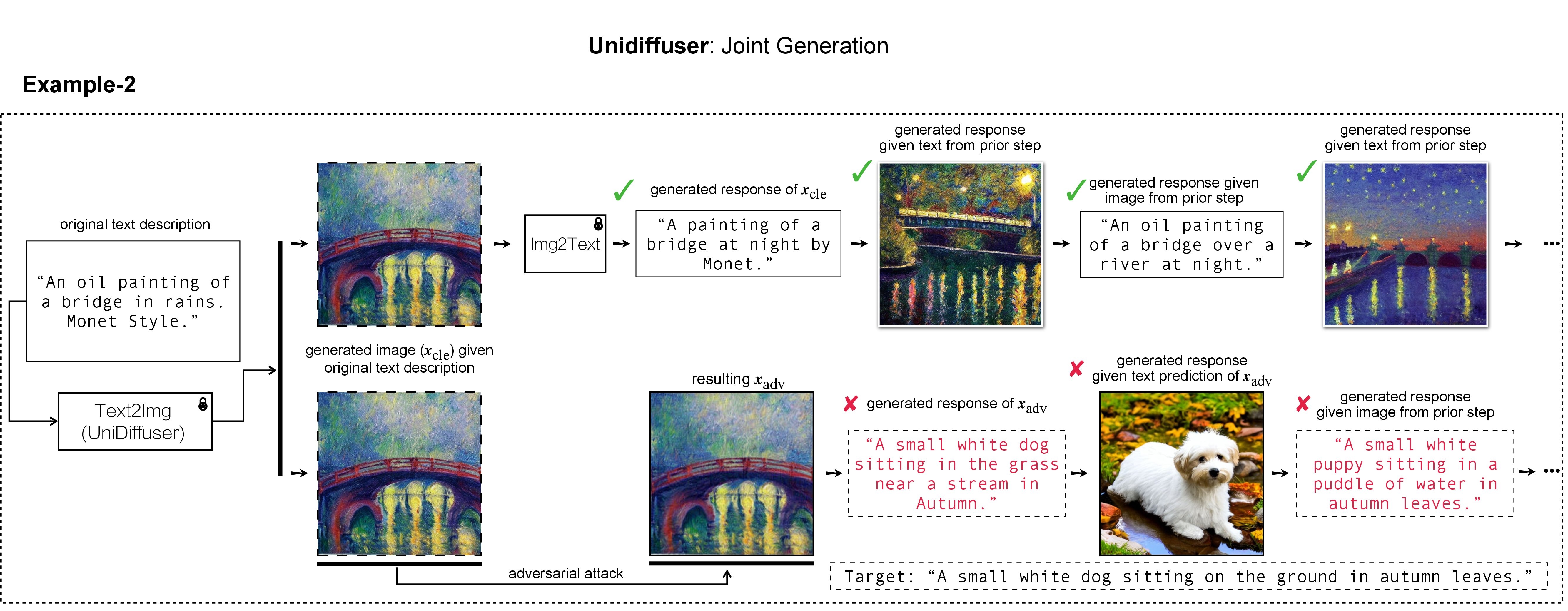
우리 작업에서는 대상 이미지 생성 및 시연을 위해 DALL-E, Midjourney 및 Stable Diffusion을 사용했습니다. 대규모 실험에서는 대상 이미지 생성을 위해 Stable Diffusion을 적용합니다. Stable Diffusion을 설치하기 위해 Latent Diffusion Models에 따라 conda 환경을 초기화합니다. 다음을 사용하여 ldm 이라는 적절한 기본 conda 환경을 만들고 활성화할 수 있습니다.
conda env create -f environment.yaml
conda activate ldm
다양한 피해자 모델의 경우 공식 구현 및 콘다 환경을 따릅니다.
 논문에서 설명한 대로 유연한 표적 공격을 달성하기 위해 사전 훈련된 텍스트-이미지 모델을 활용하여 단일 캡션을 표적 텍스트로 제공하여 표적 이미지를 생성합니다. 결과적으로 이 방법으로 공격 대상 캡션을 직접 지정할 수 있습니다!
논문에서 설명한 대로 유연한 표적 공격을 달성하기 위해 사전 훈련된 텍스트-이미지 모델을 활용하여 단일 캡션을 표적 텍스트로 제공하여 표적 이미지를 생성합니다. 결과적으로 이 방법으로 공격 대상 캡션을 직접 지정할 수 있습니다!
우리는 실험에서 텍스트-이미지 생성기로 Stable Diffusion, DALL-E 또는 Midjourney를 사용합니다. 여기서는 시연을 위해 Stable Diffusion을 사용합니다(오픈 소스에 감사드립니다!).
git clone https://github.com/CompVis/stable-diffusion.git
cd stable-diffusion
그런 다음 MS-COCO에서 전체 대상 캡션을 준비하거나 처리되고 정리된 버전을 다운로드하십시오.
https://drive.google.com/file/d/19tT036LBvqYonzI7PfU9qVi3jVGApKrg/view?usp=sharing
./stable-diffusion/ 으로 옮깁니다. 실험에서는 적대적 공격을 위해 COCO 캡션의 하위 집합(예: 10 , 100 , 1K , 10K , 50K )을 무작위로 샘플링할 수 있습니다. 예를 들어, 10K COCO 캡션을 대상 텍스트 c_tar로 무작위로 샘플링하여 다음 파일에 저장했다고 가정해 보겠습니다.
https://drive.google.com/file/d/1e5W3Yim7ZJRw3_C64yqVZg_Na7dOawaF/view?usp=sharing
대상 이미지 h_ξ(c_tar)는 아래 스크립트와 txt2img_coco.py 사용하여 샘플링된 COCO 캡션에서 텍스트 프롬프트를 읽어 Stable Diffusion을 통해 얻을 수 있습니다( txt2img_coco.py ./stable-diffusion/ 으로 이동하세요. 하이퍼파라미터는 다음과 같을 수 있습니다. 귀하의 선호에 따라 조정됨):
python txt2img_coco.py
--ddim_eta 0.0
--n_samples 10
--n_iter 1
--scale 7.5
--ddim_steps 50
--plms
--skip_grid
--ckpt ./_model_pool/sd-v1-4-full-ema.ckpt
--from-file './name_of_your_coco_captions_file.txt'
--outdir './path_of_your_targeted_images'
여기서 ckpt는 Stable Diffusion v1에서 제공되며 여기에서 다운로드할 수 있습니다: sd-v1-4-full-ema.ckpt.
Stable Diffusion에 의한 텍스트-이미지 생성에 대한 추가 구현 세부 사항은 여기에서 확인할 수 있습니다.
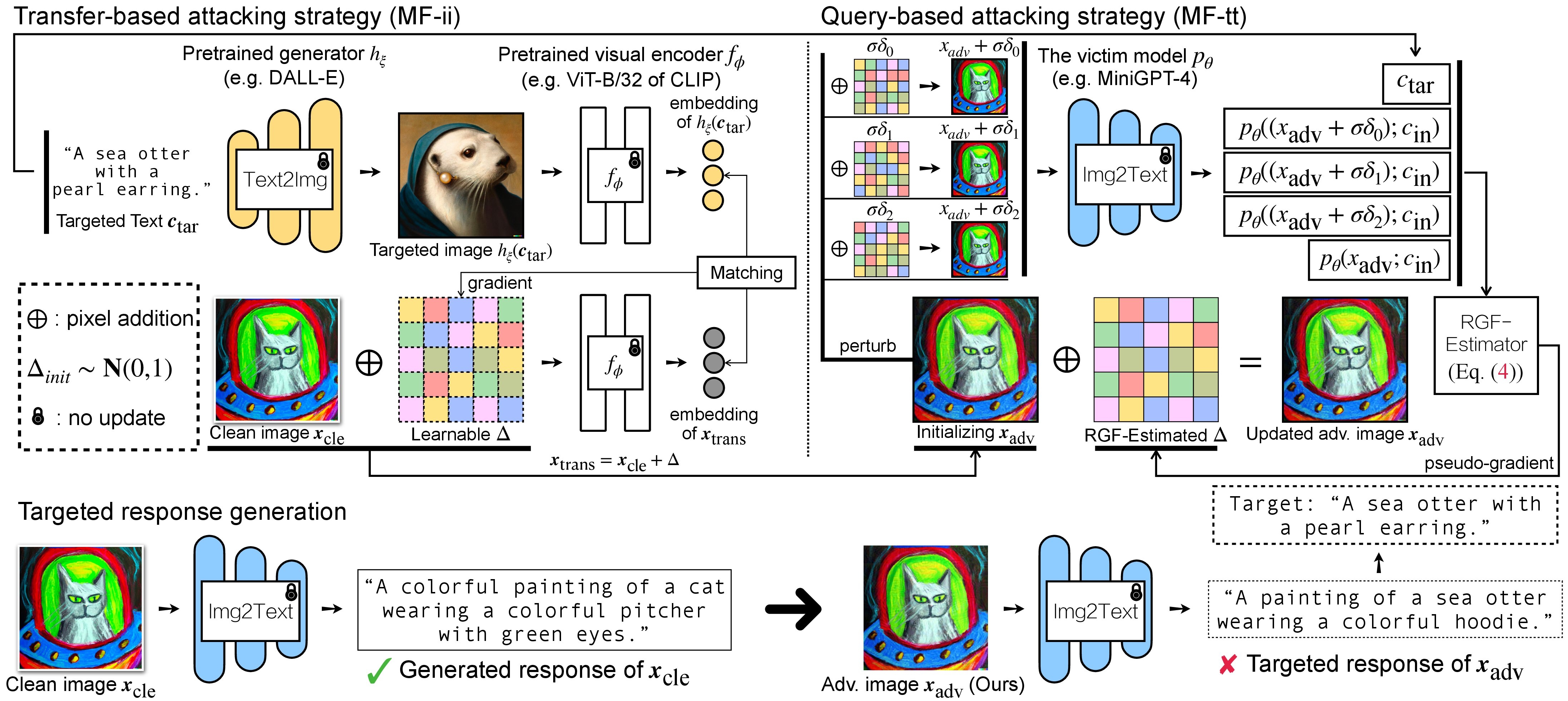
VLM에 대한 적대적 공격에는 (1) 전송 기반 공격 전략과 (2) (1)을 초기화로 사용하는 쿼리 기반 공격 전략의 두 단계가 있습니다. BLIP/BLIP-2/Img2Prompt 모델의 경우 ./LAVIS_tool 을 참조하세요. 여기서는 예로 Unidiffuser를 사용합니다.
git clone https://github.com/thu-ml/unidiffuser.git
cd unidiffuser
cp ../unidff_tool/* ./
그런 다음 여기 단계에 따라 unidiffuser 라는 적절한 conda 환경을 만들고 해당 모델 가중치를 준비합니다( uvit_v1.pth U-ViT의 가중치로 사용합니다).
conda activate unidiffuser
bash _train_adv_img_trans.sh
제작된 adv 이미지 x_trans는 --output 에 지정된 dir of white-box transfer images 에 저장됩니다. 그런 다음 이미지를 텍스트로 변환하고 생성된 x_trans 응답을 저장합니다. 이는 다음을 통해 달성할 수 있습니다.
python _eval_i2t_dataset.py
--batch_size 100
--mode i2t
--img_path 'dir of white-box transfer images'
--output 'dir of white-box transfer captions'
생성된 응답은 .txt 형식의 dir of white-box transfer captions 에 저장됩니다. RGF 추정기를 통한 의사 기울기 추정에 이를 사용할 것입니다.
MF-ii + MF-tt (예: 8px)에 대해 고정된 교란 예산을 사용한다고 가정합니다. bash _train_trans_and_query_fixed_budget.sh
반면, 별도의 섭동 예산 으로 전송+쿼리 기반 공격을 수행하려는 경우 추가로 스크립트를 제공합니다.
bash _train_trans_and_query_more_budget.sh
여기서는 wandb 사용하여 CLIP 점수(예: RN50, ViT-B/32, ViT-L/14 등)의 이동 평균을 동적으로 모니터링하여 (a) 생성된 응답(trans/ 쿼리 이미지) 및 (b) 사전 정의된 타겟 텍스트 c_tar .
아래 예시는 점선이 쿼리 후 CLIP 점수(이미지 캡션)의 이동 평균을 나타냅니다. 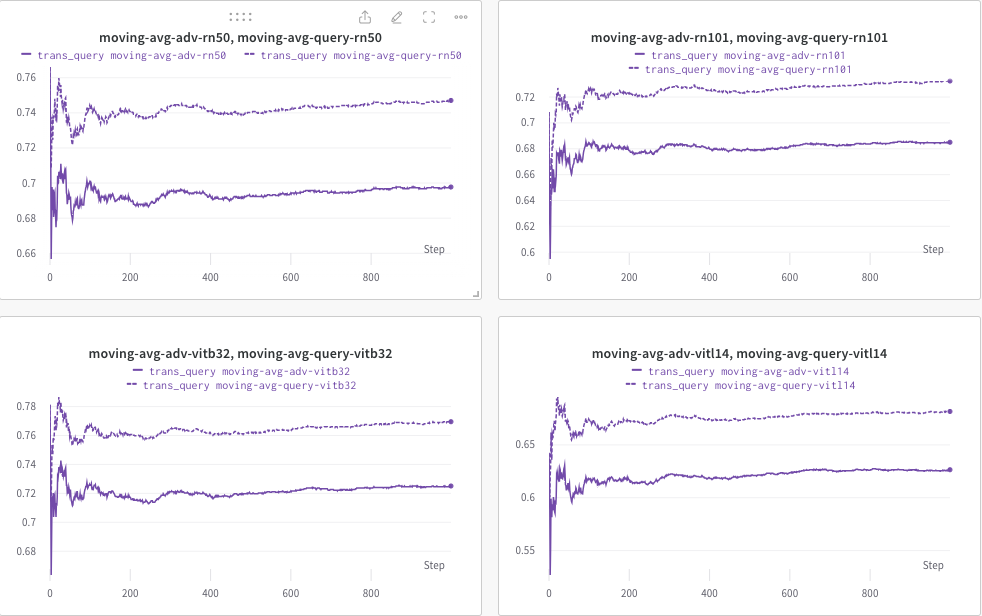
한편, 쿼리 후 이미지 캡션이 저장되며 디렉토리는 --output 으로 지정할 수 있습니다.
이 프로젝트가 귀하의 연구에 유용하다고 생각되면 다음 논문을 인용하는 것을 고려해 보십시오.
@inproceedings{zhao2023evaluate,
title={On Evaluating Adversarial Robustness of Large Vision-Language Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Li, Chongxuan and Cheung, Ngai-Man and Lin, Min},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems},
year={2023}
}
한편, (다중 모드) 확산 모델에 워터마크 삽입을 목표로 하는 관련 연구는 다음과 같습니다.
@article{zhao2023recipe,
title={A Recipe for Watermarking Diffusion Models},
author={Zhao, Yunqing and Pang, Tianyu and Du, Chao and Yang, Xiao and Cheung, Ngai-Man and Lin, Min},
journal={arXiv preprint arXiv:2303.10137},
year={2023}
}
MiniGPT-4, LLaVA, Unidiffuser, LAVIS 및 CLIP의 훌륭한 기본 구현에 감사드립니다. 또한 LLaMA 체크폰트를 오픈소스로 제공한 @MetaAI에게도 감사드립니다. 우리 연구에서 @Midjourney가 생성한 즐겁고 시각적으로 즐거운 이미지를 제공해 주신 SiSi에게 감사드립니다.


