SDV
v1.17.2 - 2024-11-18
이 저장소는 DataCebo의 프로젝트인 The Synthetic Data Vault Project의 일부입니다.



SDV( Synthetic Data Vault )는 표 형식의 합성 데이터를 생성하기 위한 원스톱 상점으로 설계된 Python 라이브러리입니다. SDV는 다양한 기계 학습 알고리즘을 사용하여 실제 데이터의 패턴을 학습하고 이를 합성 데이터에서 에뮬레이트합니다.
? 머신러닝을 사용하여 합성 데이터를 생성합니다. SDV는 고전적인 통계 방법(GaussianCopula)부터 딥 러닝 방법(CTGAN)에 이르는 다양한 모델을 제공합니다. 단일 테이블, 여러 연결된 테이블 또는 순차 테이블에 대한 데이터를 생성합니다.
데이터를 평가하고 시각화합니다. 다양한 측정을 통해 합성 데이터를 실제 데이터와 비교합니다. 문제를 진단하고 품질 보고서를 생성하여 더 많은 통찰력을 얻으세요.
제약 조건을 전처리하고 익명화하고 정의합니다. 데이터 처리를 제어하여 합성 데이터의 품질을 향상시키고, 다양한 유형의 익명화 중에서 선택하고, 논리적 제약 조건의 형태로 비즈니스 규칙을 정의하세요.
| 중요한 링크 | |
|---|---|
 튜토리얼 튜토리얼 | SDV를 직접 경험해 보세요. 튜토리얼 노트북을 실행하고 코드를 직접 실행해 보세요. |
| 문서 | 사용자 가이드 및 API 참조를 통해 SDV 라이브러리를 사용하는 방법을 알아보세요. |
| ? 블로그 | SDV 사용, 모델 배포 및 합성 데이터 커뮤니티에 대해 더 많은 통찰력을 얻으십시오. |
 지역 사회 지역 사회 | 공지 사항과 토론을 위해 Slack 작업 공간에 참여하세요. |
| 웹사이트 | 프로젝트에 대한 자세한 내용은 SDV 웹사이트를 확인하세요. |
SDV는 Business Source License에 따라 공개적으로 제공됩니다. pip 또는 conda를 사용하여 SDV를 설치합니다. 장치의 다른 소프트웨어와의 충돌을 피하기 위해 가상 환경을 사용하는 것이 좋습니다.
pip install sdvconda install -c pytorch -c conda-forge sdv시작하려면 데모 데이터세트를 로드하세요. 이 데이터 세트는 가상의 호텔에 숙박하는 손님을 설명하는 단일 테이블입니다.
from sdv . datasets . demo import download_demo
real_data , metadata = download_demo (
modality = 'single_table' ,
dataset_name = 'fake_hotel_guests' )
데모에는 각 열의 데이터 유형과 기본 키( guest_email )를 포함하여 데이터 세트에 대한 설명인 메타데이터 도 포함되어 있습니다.
다음으로 합성 데이터를 생성하는 데 사용할 수 있는 객체인 SDV 신시사이저를 생성할 수 있습니다. 실제 데이터로부터 패턴을 학습하고 이를 복제하여 합성 데이터를 생성합니다. GaussianCopulaSynthesizer를 사용해 보겠습니다.
from sdv . single_table import GaussianCopulaSynthesizer
synthesizer = GaussianCopulaSynthesizer ( metadata )
synthesizer . fit ( data = real_data )이제 합성기는 합성 데이터를 생성할 준비가 되었습니다!
synthetic_data = synthesizer . sample ( num_rows = 500 )합성 데이터에는 다음과 같은 속성이 있습니다.
SDV 라이브러리를 사용하면 합성 데이터를 실제 데이터와 비교하여 평가할 수 있습니다. 품질 보고서를 생성하여 시작해 보세요.
from sdv . evaluation . single_table import evaluate_quality
quality_report = evaluate_quality (
real_data ,
synthetic_data ,
metadata ) Generating report ...
(1/2) Evaluating Column Shapes: |████████████████| 9/9 [00:00<00:00, 1133.09it/s]|
Column Shapes Score: 89.11%
(2/2) Evaluating Column Pair Trends: |██████████████████████████████████████████| 36/36 [00:00<00:00, 502.88it/s]|
Column Pair Trends Score: 88.3%
Overall Score (Average): 88.7%
이 개체는 0~100%(100이 가장 좋음) 범위의 전체 품질 점수와 세부 분석을 계산합니다. 더 많은 통찰력을 얻으려면 합성 데이터와 실제 데이터를 시각화할 수도 있습니다.
from sdv . evaluation . single_table import get_column_plot
fig = get_column_plot (
real_data = real_data ,
synthetic_data = synthetic_data ,
column_name = 'amenities_fee' ,
metadata = metadata
)
fig . show ()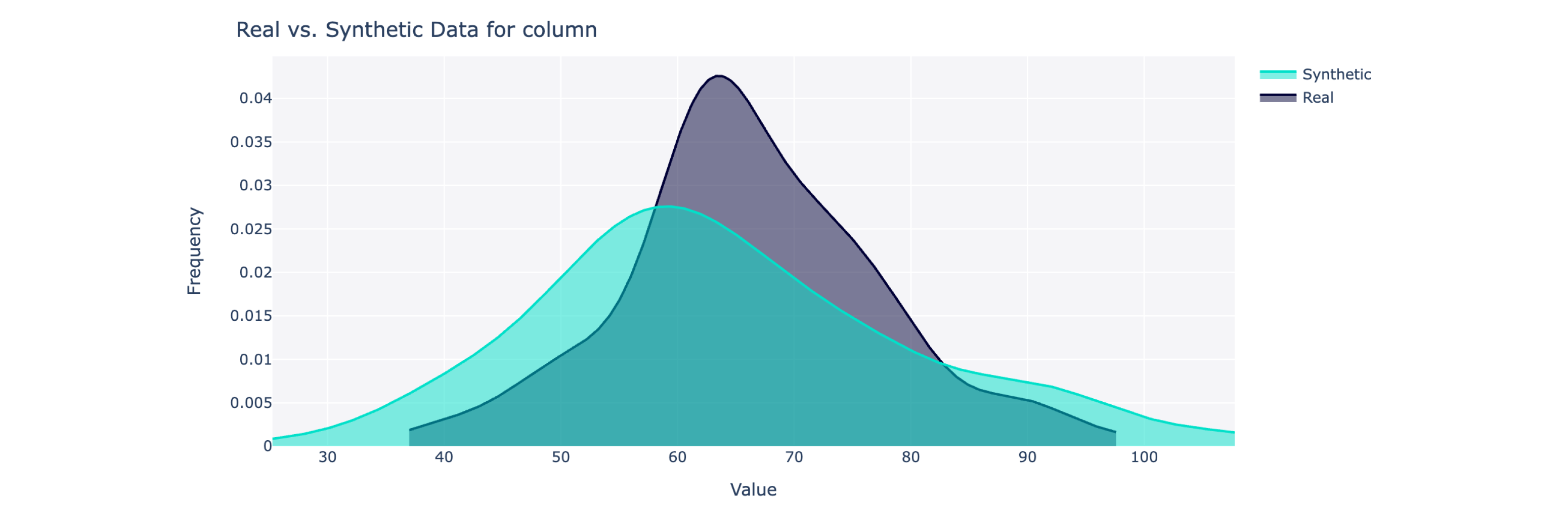
SDV 라이브러리를 이용하면 단일 테이블, 다중 테이블, 순차 데이터를 합성할 수 있습니다. 또한 전처리, 익명화, 제약 조건 추가를 포함한 전체 합성 데이터 워크플로우를 사용자 정의할 수도 있습니다.
자세히 알아보려면 SDV 데모 페이지를 방문하세요.
수년 동안 SDV 생태계를 구축하고 유지해 온 기여자 팀에 감사드립니다!
기여자 보기
연구에 SDV를 사용하는 경우 다음 논문을 인용해 주세요.
네하 파트키, 로이 웨지, 칼얀 비라마차네니 . 합성 데이터 저장소. IEEE DSAA 2016.
@inproceedings{
SDV,
title={The Synthetic data vault},
author={Patki, Neha and Wedge, Roy and Veeramachaneni, Kalyan},
booktitle={IEEE International Conference on Data Science and Advanced Analytics (DSAA)},
year={2016},
pages={399-410},
doi={10.1109/DSAA.2016.49},
month={Oct}
}
Synthetic Data Vault 프로젝트는 2016년 MIT의 Data to AI Lab에서 처음 만들어졌습니다. 4년간의 연구와 기업과의 견인 끝에 우리는 프로젝트 성장을 목표로 2020년 DataCebo를 만들었습니다. 현재 DataCebo는 합성 데이터 생성 및 평가를 위한 최대 규모의 생태계인 SDV의 자랑스러운 개발자입니다. 다음을 포함하여 합성 데이터를 지원하는 여러 라이브러리가 있습니다.
완전히 통합된 솔루션이자 합성 데이터를 위한 원스톱 상점인 SDV 패키지를 사용해 시작해 보세요. 또는 특정 요구 사항에 따라 독립 실행형 라이브러리를 사용하세요.


