LipGER
Initial Release
이는 InterSpeech 2024에서 구두 발표를 위해 선정된 LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition 논문의 공식 구현입니다.
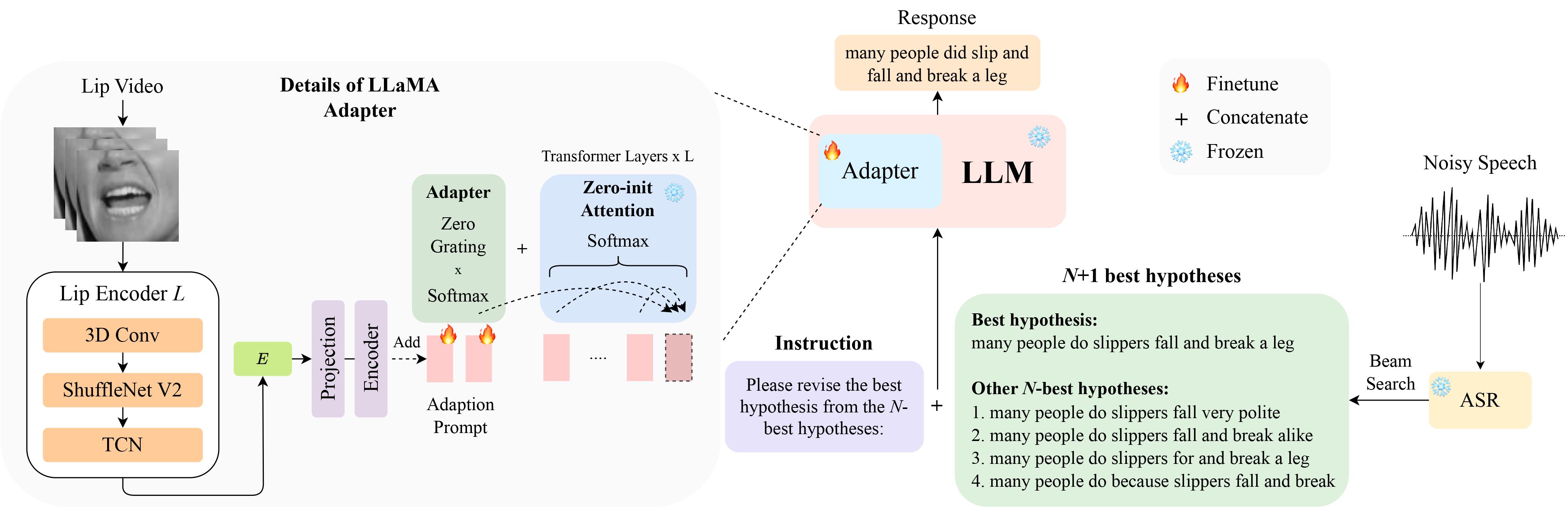
LipHyp 데이터는 여기에서 다운로드하실 수 있습니다!
pip install -r requirements.txt
먼저 다음을 사용하여 체크포인트를 준비합니다.
pip install huggingface_hub
python scripts/download.py --repo_id meta-llama/Llama-2-7b-chat-hf --token your_hf_token
python scripts/convert_hf_checkpoint.py --checkpoint_dir checkpoints/meta-llama/Llama-2-7b-chat-hf사용 가능한 모든 체크포인트를 보려면 다음을 실행하세요.
python scripts/download.py | grep Llama-2자세한 내용은 이 링크를 참조할 수도 있으며, 여기서 다른 모델에 대한 다른 체크포인트도 준비할 수 있습니다. 특히 실험에는 TinyLlama를 사용합니다.
체크포인트는 여기에서 확인하실 수 있습니다. 다운로드 후 여기에서 체크포인트 경로를 변경하세요.
LipGER에서는 모든 train, val 및 테스트 파일이 Sample_data.json 형식일 것으로 예상합니다. 파일의 인스턴스는 다음과 같습니다.
{
"Dataset": "dataset_name",
"Uid": "unique_id",
"Caption": "The ground truth transcription.",
"Noisy_Wav": "path_to_noisy_wav",
"Mouthroi": "path_to_mouth_roi_mp4",
"Video": "path_to_video_mp4",
"nhyps_base": [ list of N-best hypotheses ],
}
N-최고 가설을 생성할 수 있는 훈련된 ASR 모델을 통해 음성 파일을 전달해야 합니다. 이 저장소에서는 이를 달성하는 데 도움이 되는 두 가지 방법을 제공합니다. 다른 방법을 사용해 보세요.
pip install whisper 사용하여 Whisper를 설치한 다음 data 폴더에서 nhyps.py를 실행하면 문제가 없을 것입니다! 두 방법 모두 목록의 첫 번째 가설이 가장 좋은 가설이고 나머지는 N-최고 가설입니다(JSON의 목록 nhyps_base 필드로 전달되고 다음 단계에서 프롬프트를 구성하는 데 사용됩니다).
또한 제공된 메서드는 음성만 입력으로 사용합니다. 시청각 N-최고 가설 생성을 위해 Auto-AVSR을 사용했습니다. 코드와 관련하여 도움이 필요하면 문제를 제기해 주세요!
모든 음성 파일에 해당하는 비디오가 있다고 가정하고 다음 단계에 따라 비디오에서 입 ROI를 자릅니다.
python crop_mouth_script.py
python covert_lip.py
그러면 mp4 ROI가 hdf5로 변환되고, 코드는 동일한 json 파일에서 mp4 ROI의 경로를 hdf5 ROI로 변경합니다. default.yaml에서 "검출기"를 변경하여 "mediapipe" 및 "retinaface" 탐지기 중에서 선택할 수 있습니다.
N-최적 가설을 얻은 후 필요한 형식으로 JSON 파일을 구성합니다. 데이터 준비가 사람마다 다를 수 있으므로 이 부분에 대한 구체적인 코드를 제공하지는 않지만 코드는 간단해야 합니다. 다시 한 번 의심스러운 점이 있으면 문제를 제기하세요!
LipGER 훈련 스크립트는 훈련이나 평가를 위해 JSON을 사용하지 않습니다. pt파일로 변환하셔야 합니다. 이를 달성하려면 Convert_to_pt.py를 실행할 수 있습니다! 27행에서 원하는 대로 model_name 변경하고 58행에서 JSON에 경로를 추가합니다.
LipGER를 미세 조정하려면 다음을 실행하세요.
sh finetune.sh
여기서 data (데이터 세트 이름 포함), --train_path 및 --val_path (훈련에 대한 절대 경로 및 유효한 .pt 파일 포함) 값을 수동으로 설정해야 합니다.
추론을 위해 먼저 lipger.py( exp_path 및 checkpoint_dir )에서 해당 경로를 변경한 다음 (적절한 테스트 데이터 경로 인수를 사용하여) 실행합니다.
sh infer.sh
입 자르기 ROI에 대한 코드는 Visual_Speech_Recognition_for_Multiple_Languages에서 영감을 받았습니다.
LipGER의 코드는 RobustGER에서 영감을 받았습니다. 우리 논문이나 코드가 유용하다고 생각되면 해당 논문도 인용해 주세요.
@inproceedings{ghosh23b_interspeech,
author={Sreyan Ghosh and Sonal Kumar and Ashish Seth and Purva Chiniya and Utkarsh Tyagi and Ramani Duraiswami and Dinesh Manocha},
title={{LipGER: Visually-Conditioned Generative Error Correction for Robust Automatic Speech Recognition}},
year=2024,
booktitle={Proc. INTERSPEECH 2024},
}


