self instruct
1.0.0
이 저장소에는 사전 훈련된 언어 모델을 지침과 정렬하는 방법인 Self-Instruct 문서에 대한 코드와 데이터가 포함되어 있습니다.
Self-Instruct는 언어 모델이 자연어 지침을 따르는 능력을 향상시키는 데 도움이 되는 프레임워크입니다. 이는 모델의 자체 세대를 사용하여 대규모 교육 데이터 컬렉션을 생성함으로써 수행됩니다. Self-Instruct를 사용하면 광범위한 수동 주석에 의존하지 않고도 언어 모델의 명령 따르기 기능을 향상시킬 수 있습니다.
최근에는 다양한 작업을 수행하기 위해 자연어 지시를 따를 수 있는 모델을 구축하는 데 대한 관심이 높아지고 있습니다. "명령 조정" 언어 모델로 알려진 이러한 모델은 새로운 작업에 일반화하는 능력을 보여주었습니다. 그러나 이들의 성능은 교육에 사용되는 사람이 작성한 지침 데이터의 품질과 양에 크게 좌우되므로 다양성과 창의성이 제한될 수 있습니다. 이러한 한계를 극복하려면 명령 조정 모델을 감독하고 명령 따르기 기능을 향상시키기 위한 대체 접근 방식을 개발하는 것이 중요합니다.
Self-Instruct 프로세스는 수동으로 작성된 지침의 시드 세트로 시작하여 이를 사용하여 언어 모델에 새로운 지침과 해당 입력-출력 인스턴스를 생성하도록 요청하는 반복적인 부트스트래핑 알고리즘입니다. 그런 다음 이러한 세대를 필터링하여 품질이 낮거나 유사한 세대를 제거하고 결과 데이터가 작업 풀에 다시 추가됩니다. 이 프로세스는 여러 번 반복될 수 있으며 결과적으로 지침을 보다 효과적으로 따르도록 언어 모델을 미세 조정하는 데 사용할 수 있는 대규모 지침 데이터 컬렉션이 생성됩니다.
Self-Instruct의 개요는 다음과 같습니다.
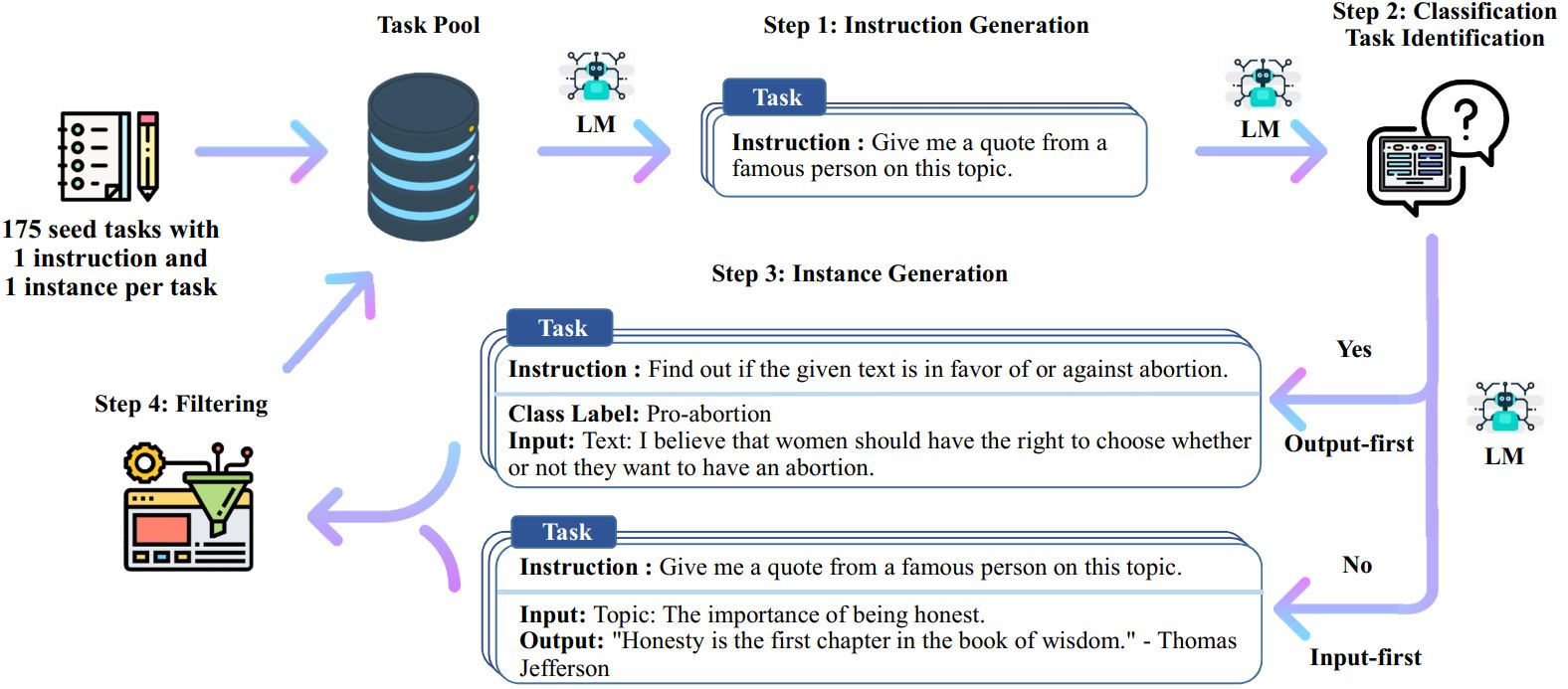
* 이 작업은 아직 진행 중입니다. 진행 과정에서 코드와 데이터를 업데이트할 수 있습니다. 버전 관리에 주의하시기 바랍니다.
우리는 82,000개의 인스턴스 입력 및 출력과 쌍을 이루는 52,000개의 명령을 포함하는 데이터세트를 출시합니다. 이 명령어 데이터는 언어 모델에 대한 명령어 조정을 수행하고 언어 모델이 명령어를 더 잘 따르도록 만드는 데 사용될 수 있습니다. 전체 모델 생성 데이터는 data/gpt3-generations/batch_221203/all_instances_82K.jsonl 에서 액세스할 수 있습니다. 깨끗한 GPT3 미세 조정 형식(프롬프트 + 완료)으로 다시 형식화된 이 데이터(+ 175개 시드 작업)는 data/finetuning/self_instruct_221203 에 저장됩니다. ./scripts/finetune_gpt3.sh 의 스크립트를 사용하여 이 데이터에 대한 GPT3를 미세 조정할 수 있습니다.
참고 : 이 데이터는 언어 모델(GPT3)에 의해 생성된 것이므로 필연적으로 일부 오류나 편견이 포함되어 있습니다. 우리는 논문에 있는 200개의 무작위 명령에 대한 데이터 품질을 분석한 결과, 데이터 포인트의 46%에 문제가 있을 수 있음을 발견했습니다. 우리는 사용자가 이 데이터를 주의해서 사용할 것을 권장하고 결함을 필터링하거나 개선할 수 있는 새로운 방법을 제안합니다.
또한 (잘 연구된 NLP 작업이 아닌) 사용자 지향 애플리케이션을 기반으로 전문가가 작성한 새로운 252개 작업 세트와 해당 지침을 출시합니다. 이 데이터는 자기 지도서의 인간 평가 섹션에 사용됩니다. 자세한 내용은 인간 평가 README를 참조하세요.
자체 시드 작업이나 기타 모델을 사용하여 Self-Instruct 데이터를 생성하기 위해 여기에서 전체 파이프라인에 대한 스크립트를 오픈 소스로 제공합니다. 현재 코드는 OpenAI API를 통해 액세스할 수 있는 GPT3 모델에서만 테스트되었습니다.
데이터를 생성하기 위한 스크립트는 다음과 같습니다.
# 1. 시드 작업에서 명령어를 생성합니다./scripts/generate_instructions.sh# 2. 명령어가 분류 작업을 나타내는지 여부를 식별합니다./scripts/is_clf_or_not.sh# 3. 각 명령어에 대한 인스턴스를 생성합니다./scripts/generate_instances. sh# 4. 필터링, 처리 및 재포맷./scripts/prepare_for_finetuning.sh
Self-Instruct 프레임워크나 데이터를 사용하는 경우 자유롭게 인용해 주세요.
@misc{selfinstruct, title={Self-Instruct: 자체 생성 명령으로 언어 모델 정렬}, 작성자={Wang, Yizhong 및 Kordi, Yeganeh 및 Mishra, Swaroop 및 Liu, Alisa 및 Smith, Noah A. 및 Khashabi, Daniel 및 Hajishirzi, Hannaneh}, 저널={arXiv 사전 인쇄 arXiv:2212.10560}, 연도={2022}} 

