bertsearch
1.0.0
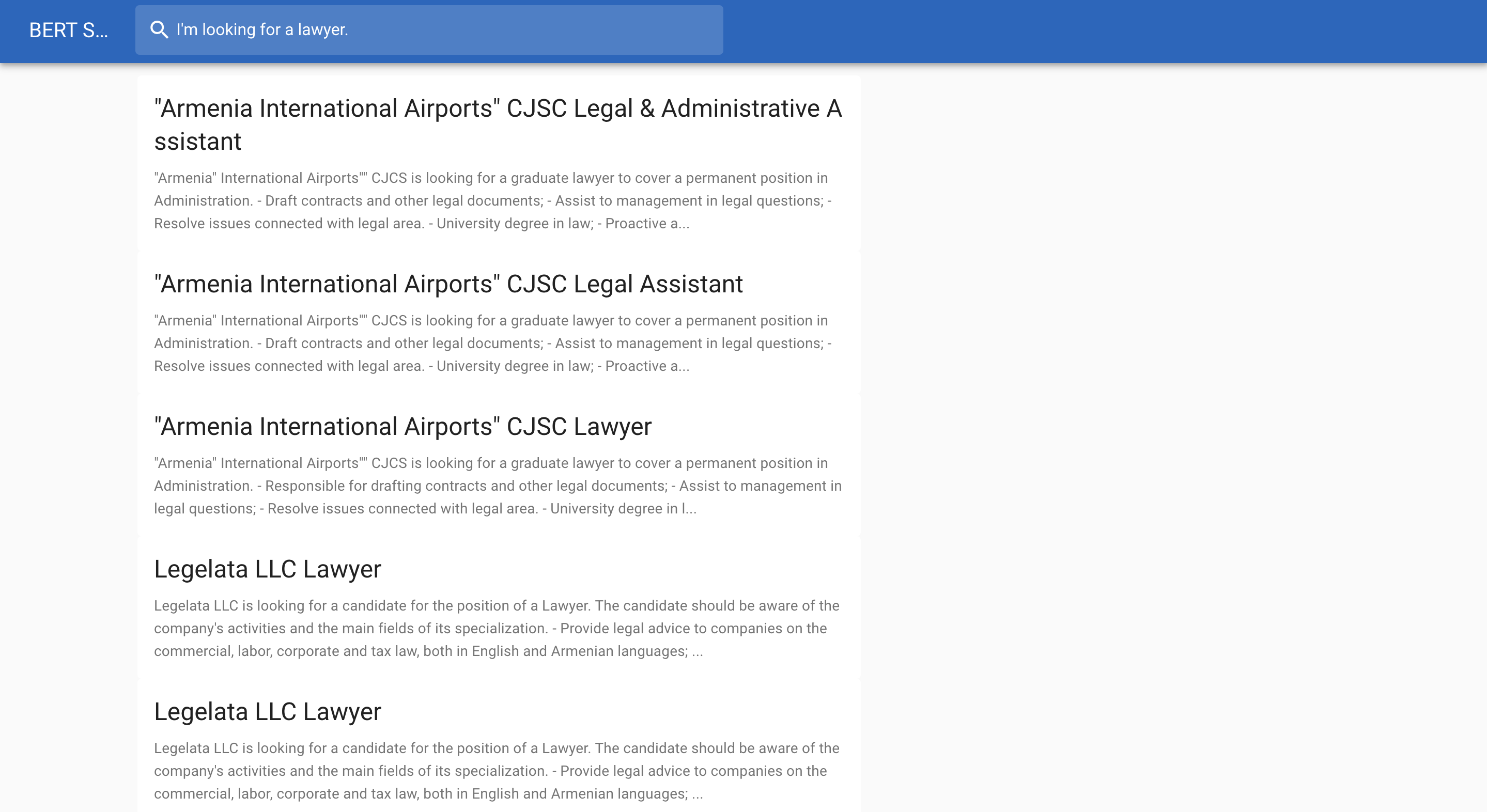
다음은 채용정보 검색 예시입니다.
| BERT 기반, 케이스 없음 | 12층, 768개 숨김, 12개 헤드, 110M 매개변수 |
| BERT-대형, 케이스 없음 | 24레이어, 1024개 히든, 16헤드, 340M 매개변수 |
| BERT 베이스, 케이스형 | 12층, 768개 숨김, 12개 헤드, 110M 매개변수 |
| BERT-대형, 케이스형 | 24레이어, 1024개 히든, 16헤드, 340M 매개변수 |
| BERT 기반, 다국어 케이스(신규) | 104개 언어, 12레이어, 768개 숨겨진, 12개 헤드, 1억 1천만 개의 매개변수 |
| BERT 기반, 다국어 케이스(구형) | 102개 언어, 12레이어, 768개 숨겨진, 12개 헤드, 1억 1천만 개의 매개변수 |
| BERT-Base, 중국어 | 중국어 간체 및 번체, 12레이어, 768개 숨김, 12헤드, 110M 매개변수 |
$ wget https://storage.googleapis.com/bert_models/2018_10_18/cased_L-12_H-768_A-12.zip
$ unzip cased_L-12_H-768_A-12.zip사전 학습된 BERT 모델과 Elasticsearch의 인덱스 이름을 환경 변수로 설정해야 합니다.
$ export PATH_MODEL=./cased_L-12_H-768_A-12
$ export INDEX_NAME=jobsearch$ docker-compose up 주의 : BERT 컨테이너에는 높은 메모리가 필요하므로 가능하면 Docker의 메모리 구성에 높은 메모리( 8GB 이상)를 할당하십시오.
인덱스 생성 API를 사용하여 Elasticsearch 클러스터에 새 인덱스를 추가할 수 있습니다. 인덱스를 생성할 때 다음을 지정할 수 있습니다.
예를 들어, title , text 및 text_vector 필드가 있는 jobsearch 색인을 생성하려면 다음 명령을 사용하여 색인을 생성할 수 있습니다.
$ python example/create_index.py --index_file=example/index.json --index_name=jobsearch
# index.json
{
" settings " : {
" number_of_shards " : 2,
" number_of_replicas " : 1
},
" mappings " : {
" dynamic " : " true " ,
" _source " : {
" enabled " : " true "
},
" properties " : {
" title " : {
" type " : " text "
},
" text " : {
" type " : " text "
},
" text_vector " : {
" type " : " dense_vector " ,
" dims " : 768
}
}
}
} 주의 : text_vector 의 dims 값은 사전 학습된 BERT 모델의 희미한 값과 일치해야 합니다.
색인을 생성하면 일부 문서의 색인을 생성할 준비가 된 것입니다. 여기서 요점은 BERT를 사용하여 문서를 벡터로 변환하는 것입니다. 결과 벡터는 text_vector 필드에 저장됩니다. 데이터를 JSON 문서로 변환해 보겠습니다.
$ python example/create_documents.py --data=example/example.csv --index_name=jobsearch
# example/example.csv
" Title " , " Description "
" Saleswoman " , " lorem ipsum "
" Software Developer " , " lorem ipsum "
" Chief Financial Officer " , " lorem ipsum "
" General Manager " , " lorem ipsum "
" Network Administrator " , " lorem ipsum "스크립트를 완료한 후 다음과 같은 JSON 문서를 얻을 수 있습니다.
# documents.jsonl
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Saleswoman" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Software Developer" , "text_vector" : [...]}
{ "_op_type" : "index" , "_index" : "jobsearch" , "text" : "lorem ipsum" , "title" : "Chief Financial Officer" , "text_vector" : [...]}
...데이터를 JSON으로 변환한 후 지정된 인덱스에 JSON 문서를 추가하고 검색 가능하게 만들 수 있습니다.
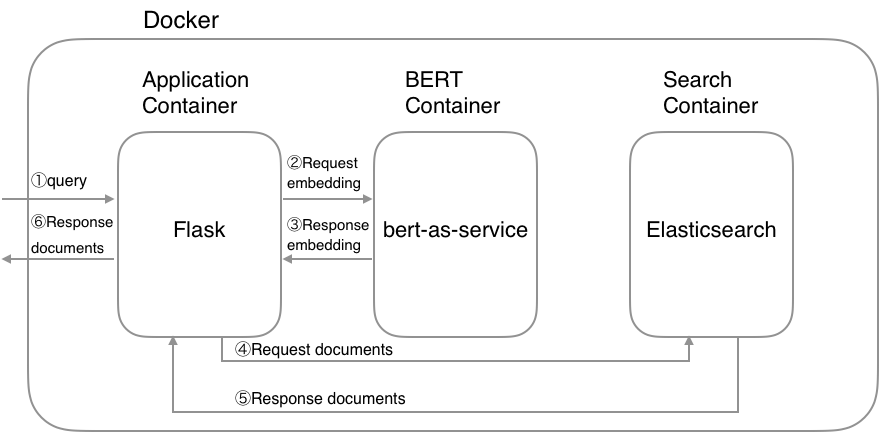
$ python example/index_documents.pyhttp://127.0.0.1:5000으로 이동합니다.


