이 코드는 이미지를 지도로 변환(Translating Images Into Maps) 논문을 기반으로 하는 기존 이미지에서 BEV 딥 러닝 모델을 기반으로 구축되었습니다. 이 코드는 Python 3.7을 사용하여 작성되었습니다. nuScenes 데이터 세트에 대해 교육을 받았습니다. 설치할 종속성 및 데이터 세트는 저장소의 ReadMe를 참조하세요.
첫 번째 단계는 "translating-images-into-maps-main"이라는 폴더를 만들고 여기에 모든 파일을 다운로드하는 것입니다. 그런 다음 파일 크기가 크기 때문에 훈련의 최신 체크포인트와 검증에 사용되는 미니 nuScenes 데이터 세트를 이 Google 드라이브에서 다운로드할 수 있습니다. 이러한 폴더는 "translating-images-into-maps-main" 디렉터리에 직접 추가되어야 합니다.
다음은 이 저장소에 필요한 라이브러리 목록입니다.
opencv
numpy
pyquaternion
shapely
lmdb
nuscenes-devkit
pillow
matplotlib
torchvision
descartes
scipy
tensorboard
scikit-image
cv2
이 저장소의 기능을 사용하려면 다음 명령줄 인수를 변경해야 할 수 있습니다.
--name: name of the experiment
--video-name: name of the video file within the video root and without extension
--savedir: directory to save experiments to
--val-interval: number of epochs between validation runs
--root: directory of the repository
--video-root: absolute directory to the video input
--nusc-version: nuscenes version (either “v1.0-mini” or “v1.0-trainval” for the full US dataset)
--train-split: training split (either “train_mini" or “train_roddick” for the full US dataset)
--val-split: validation split (either “val_mini" or “val_roddick” for the full US dataset)
--data-size: percentage of dataset to train on
--epochs: number of epochs to train for
--batch-size: batch size
--cuda-available: environment used (0 for cpu, 1 for cuda)
--iou: iou metric used (0 for iou, 1 for diou)
모델 학습과 관련하여 다음 명령줄 인수를 수정할 수 있습니다.
--optimizer: optimizer for gradient descent to run during training. Default: adam
--lr: learning rate. Default: 5e-5
--momentum: momentum for Stochastic gradient descent. Default: 0.9
--weight-decay: weight decay. Default: 1e-4
--lr-decay: learning rate decay. Default: 0.99
NuScenes Mini 및 Full 데이터세트는 다음 위치에서 찾을 수 있습니다.
NuScene 미니:
NuScenes 전체 미국:
NuScene 미니 및 전체 데이터 세트에는 동일한 이미지 입력 형식(lmdb 또는 png)이 없으므로 둘 중 하나를 사용하려면 코드에 일부 수정 사항을 적용해야 합니다.
mini 인수를 false로 변경하여 미니 데이터 세트와 train.py , validation.py 및 inference.py 파일의 인수 경로 및 분할을 사용합니다. data = nuScenesMaps (
root = args . root ,
split = args . val_split ,
grid_size = args . grid_size ,
grid_res = args . grid_res ,
classes = args . load_classes_nusc ,
dataset_size = args . data_size ,
desired_image_size = args . desired_image_size ,
mini = True ,
gt_out_size = ( 200 , 200 ),
)
loader = DataLoader (
data ,
batch_size = args . batch_size ,
shuffle = False ,
num_workers = 0 ,
collate_fn = src . data . collate_funcs . collate_nusc_s ,
drop_last = True ,
pin_memory = True
)data_loader.py 함수의 151-153 또는 146-149 행에 주석을 달거나 주석 처리를 제거합니다. # if mini:
image_input_key = pickle . dumps ( id , protocol = 3 )
with self . images_db . begin () as txn :
value = txn . get ( key = image_input_key )
image = Image . open ( io . BytesIO ( value )). convert ( mode = 'RGB' )
# else:
# original_nusenes_dir = "/work/scitas-share/datasets/Vita/civil-459/NuScenes_full/US/samples/CAM_FRONT"
# new_cam_path = os.path.join(original_nusenes_dir, Path(cam_path).name)
# image = Image.open(new_cam_path).convert(mode='RGB')사전 학습된 체크포인트는 여기에서 찾을 수 있습니다.
체크포인트는 이 저장소의 루트 디렉터리에서 /pretrained_models/27_04_23_11_08 내에 보관되어야 합니다. 다른 디렉토리에서 로드하려면 다음 인수를 변경하십시오.
- - savedir = "pretrained_models" # Careful, this path is relative in validation.py but global in train.py
- - name = "27_04_23_11_08"scitas를 훈련하려면 루트 디렉터리에서 다음 스크립트를 시작해야 합니다.
sbatch job.script.sh
CPU에서 로컬로 훈련하려면:
python3 train.py
명령줄 인수를 사용하여 스크립트를 조정해야 합니다.
scitas에서 모델 성능을 검증하려면 다음을 수행하십시오.
sbatch job.validate.sh
CPU에서 로컬로 훈련하려면:
python3 validate.py
명령줄 인수를 사용하여 스크립트를 조정해야 합니다.
scitas의 비디오를 추론하려면 다음을 수행하십시오.
sbatch job.evaluate.sh
CPU에서 로컬로 훈련하려면:
python3 inference.py
특히 다음과 같이 명령줄 인수를 사용하여 스크립트를 조정해야 합니다.
--batch-size // 1 for the test videos
--video-name
--video-root
이 프로젝트는 EPFL의 Alexandre Alahi 교수가 가르치는 자율주행차 딥러닝 과정 CIVIL-459의 맥락에서 만들어졌습니다. 우리는 박사과정 학생 Yuejiang Liu의 지도를 받았습니다. 이 과정 프로젝트의 주요 목표는 Tesla 자동 조종 장치 시스템에서 사용할 수 있는 딥 러닝 모델을 개발하는 것입니다. 우리 그룹에서는 단안 카메라 이미지에서 조감도 이미지로의 전환을 검토해 왔습니다. 이는 의미론적 분할을 사용하여 자동차, 인도, 보행자 및 지평선과 같은 요소를 분류함으로써 수행될 수 있습니다.
BEV 딥 러닝 모델에 대한 단안 이미지를 연구하는 동안 보행자에 관한 정보가 분할 중에 손실되어 분류가 제대로 이루어지지 않는다는 사실을 발견했습니다. 아래 이미지에서 볼 수 있듯이 평가 시 우리가 선택한 모델은 nuScenes 데이터 세트의 14개 객체 클래스에 대해 평균 25.7% IoU(Intersection over Union)에 도달합니다. 운전 가능 차량에 대한 예측 정확도는 양호하지만(74.5%) 자전거, 장벽 및 트레일러에 대해서는 상당히 낮습니다. 그러나 보행자에 대한 예측 정확도(9.5%)는 너무 낮다. 이렇게 낮은 정확도로 인해 누군가가 길을 건너지 않고 길을 건너는 경우 사고가 발생할 수 있습니다.

우리 연구에 대한 자세한 내용은 드라이브에서 확인할 수 있습니다.
보행자 감지 불량이 현재 훈련된 모델에서 가장 즉각적인 문제인 것처럼 보였기 때문에 우리는 더 적합한 손실 함수를 조사하고 nuScenes 데이터 세트에서 새 모델을 훈련하여 정확도를 향상시키는 것을 목표로 했습니다.
우리가 구축한 모델은 다음을 사용하여 훈련되었습니다.
또 다른 문제
그만큼
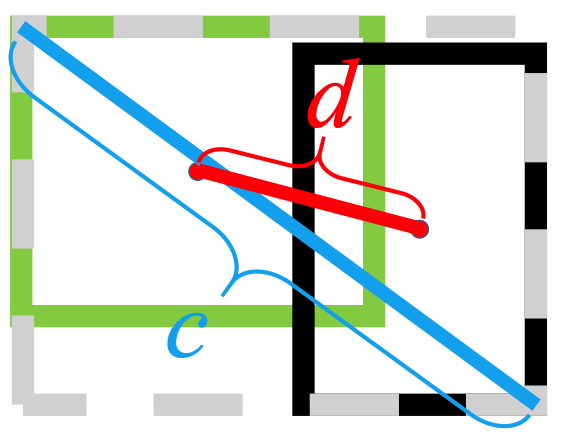
예측 상자와 대상 상자 사이의 거리를 최소화하기 위해 L2 표준을 사용하고 보다 빠르게 수렴합니다.

수평 늘이기

수직 스트레치
또한 DIOU 손실은 원활한 수렴을 장려하는 정규화 용어를 도입합니다.
다음 이미지에서 볼 수 있듯이,
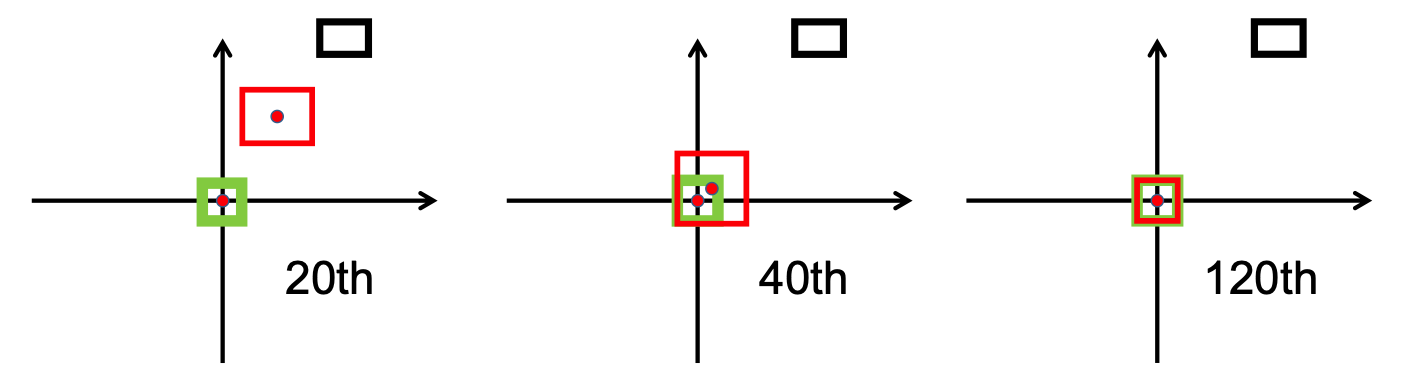
연구 단계 이후에 우리는 다음을 구현했습니다. /src/utils.py 파일의 bbox_overlaps_diou 함수에서 손실이 발생했습니다.
그런 다음 이 함수는 멀티스케일을 계산하는 데 사용됩니다. compute_multiscale_iou 함수에서. 각 수업마다, iou 입력 인수의 함수에서)는 배치 크기에 따라 계산됩니다. 함수의 출력은 멀티스케일을 포함하는 사전 iou_dict 입니다.
그런 다음 train.py 에서 이 값을 사용했습니다. val-interval epoch마다 한 번씩 평가 실행에 사용되었습니다. 이 값은 손실을 표시하는 데 사용되는 validation.py 에서도 사용되었습니다.
우리는 제공된 체크포인트 checkpoint-008.pth.gz 로 시작하는 NuScenes 데이터세트에서 모델을 훈련했습니다.
또 다른 기여는 모든 해당 레이블 및 IoU 값을 사용하여 클래스를 더 잘 구분할 수 있는 새로운 시각화 형식입니다. 이는 visualization.py 파일에서 구현되었습니다.
마지막으로 우리는 .mp4 비디오를 입력으로 가져와 이를 개별 이미지 프레임으로 분해하는 모드를 구현하기 위해 노력했습니다. 그런 다음 모델에 의해 평가되고 inference.py 파일에서 분할 결과를 시각화할 수 있습니다.
이 모델의 훈련 전략에 대한 예비 아이디어를 얻기 위해 먼저 NuScenes 미니 데이터 세트에서 훈련하기로 결정했습니다. checkpoint-008.pth.gz 부터 시작하여 사용된 IoU 메트릭(하나는 IoU, 다른 하나는 DIOU)이 다른 두 가지 모델을 훈련할 수 있었습니다. 10번의 훈련 후 NuScenes 미니 배치에서 얻은 결과는 아래 표에 나와 있습니다.

이러한 결과를 살펴보면, 우리가 가설을 바탕으로 삼은 보행자 계층은 전혀 결정적인 결과를 제시하지 못하고 있음을 확인할 수 있었다. 따라서 우리는 미니데이터세트가 우리의 요구에 충분하지 않다고 결론을 내리고 훈련을 Scitas의 전체 데이터세트로 옮기기로 결정했습니다.
8개의 새로운 시대에 대해 checkpoint-008.pth.gz 에서 새로운 모델(DIoU 또는 IoU 포함)을 훈련한 후 유망한 결과를 관찰했습니다. 새로 학습된 모델의 성능을 비교하기 위해 미니 데이터 세트에 대한 검증 단계를 수행했습니다. 이 데이터 세트 이미지의 결과 시각화가 아래에 제공됩니다.
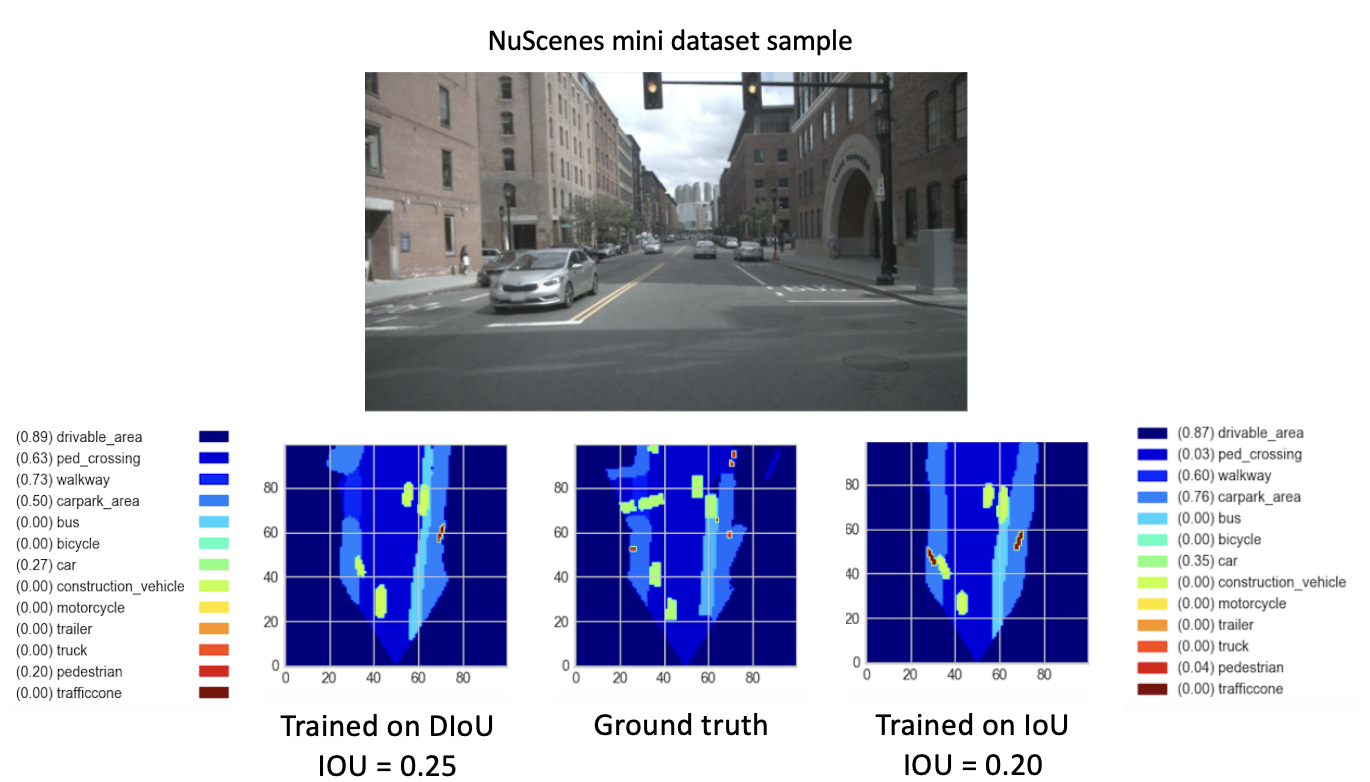
여기서는

이 결과는 마침내 더 나은 성능을 보여줍니다.
이제 훈련된 모델이 있으므로 이를 사용하여 입력 이미지나 비디오를 사용하여 BEV를 예측할 수 있습니다. 우리의 목표는 코스의 최종 데모에서 우리 방법을 구현하는 것이었지만, 유추된 조감도 지도는 불행하게도 충분한 성능을 발휘하지 못했습니다. 아래 그림은 제공된 테스트 영상 중 하나에 대한 추론 결과를 보여줍니다(테스트 영상 참조).

추론에 대한 성능 부족은 다음 매개변수로 인해 발생한다고 생각합니다.
비록
한 가지 옵션은 구현하는 것입니다.
그만큼
또한, 본 논문[2]의 연구에 따르면 CIOU의 회귀 오류는 나머지보다 빠르게 저하되고 다음으로 수렴됩니다.
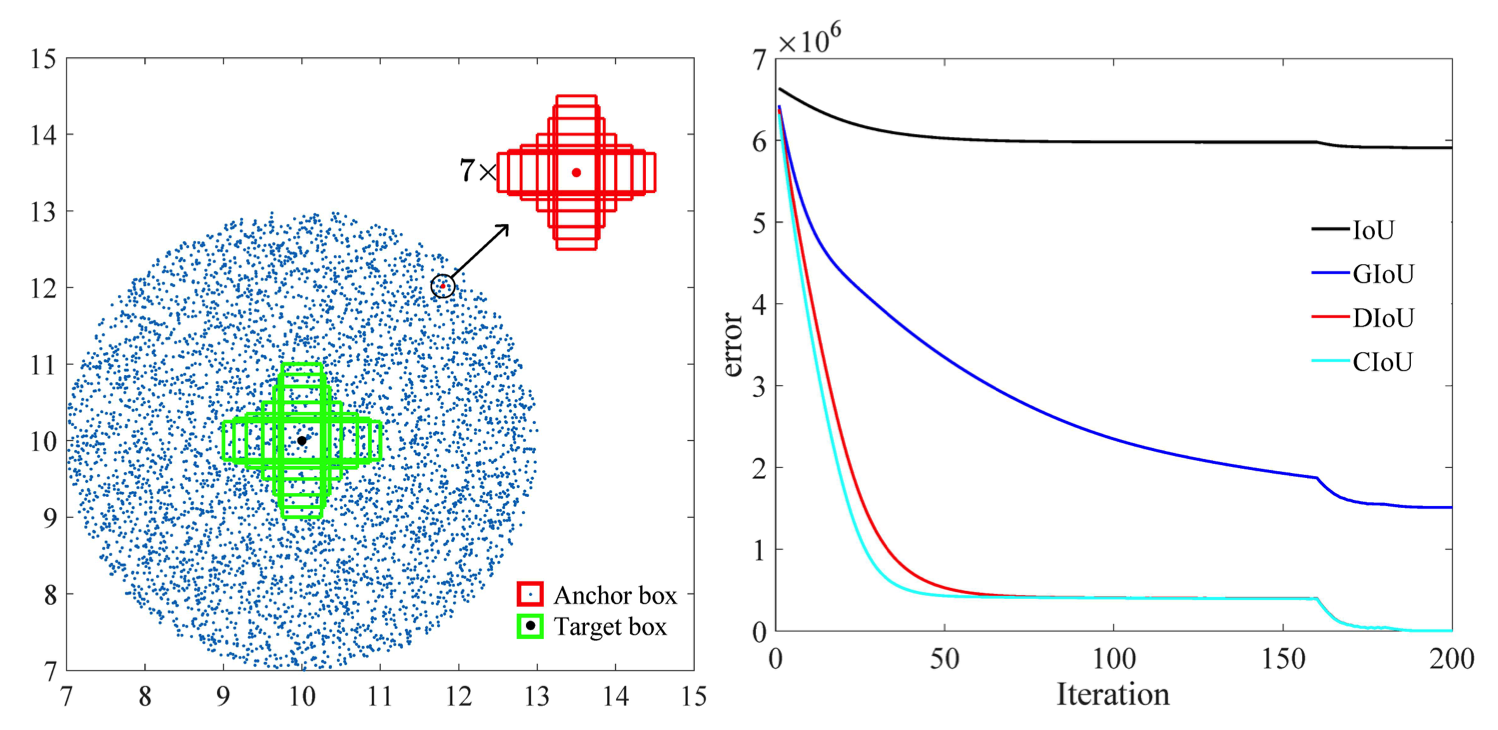
또 다른 옵션은 보행자와 자전거를 더 잘 표현하기 위해 혼잡한 환경이 풍부한 데이터 세트를 훈련하는 것입니다.
마지막으로, 가설을 실제로 검증하기 위해 전체 NuScenes 데이터 세트에 대한 검증 실행을 수행하고 두 모델의 보행자 IoU를 비교할 수 있습니다.
[1] Zhaohui Zheng, Ping Wang, Wei Liu, Jinze Li, Rongguang Ye, Dongwei Ren(2020). 거리 IoU 손실: 경계 상자 회귀를 위한 더 빠르고 더 나은 학습 https://arxiv.org/pdf/1911.08287.pdf
[2] Zhaohui Zheng, Ping Wang, Dongwei Ren, Wei Liu, Rongguang Ye, Qinghua Hu, Wangmeng Zuo(2021). 객체 감지 및 인스턴스 분할을 위한 모델 학습 및 추론의 기하학적 요소 강화 https://arxiv.org/pdf/2005.03572.pdf


