tiny cuda nn
Version 1.6
이는 신경망을 훈련하고 쿼리하기 위한 작고 독립적인 프레임워크입니다. 가장 주목할 만한 점은 매우 빠른 "완전 융합" 다층 퍼셉트론(기술 문서), 다용도 다중 해상도 해시 인코딩(기술 문서)은 물론 다양한 기타 입력 인코딩, 손실 및 최적화 프로그램에 대한 지원이 포함되어 있다는 것입니다.
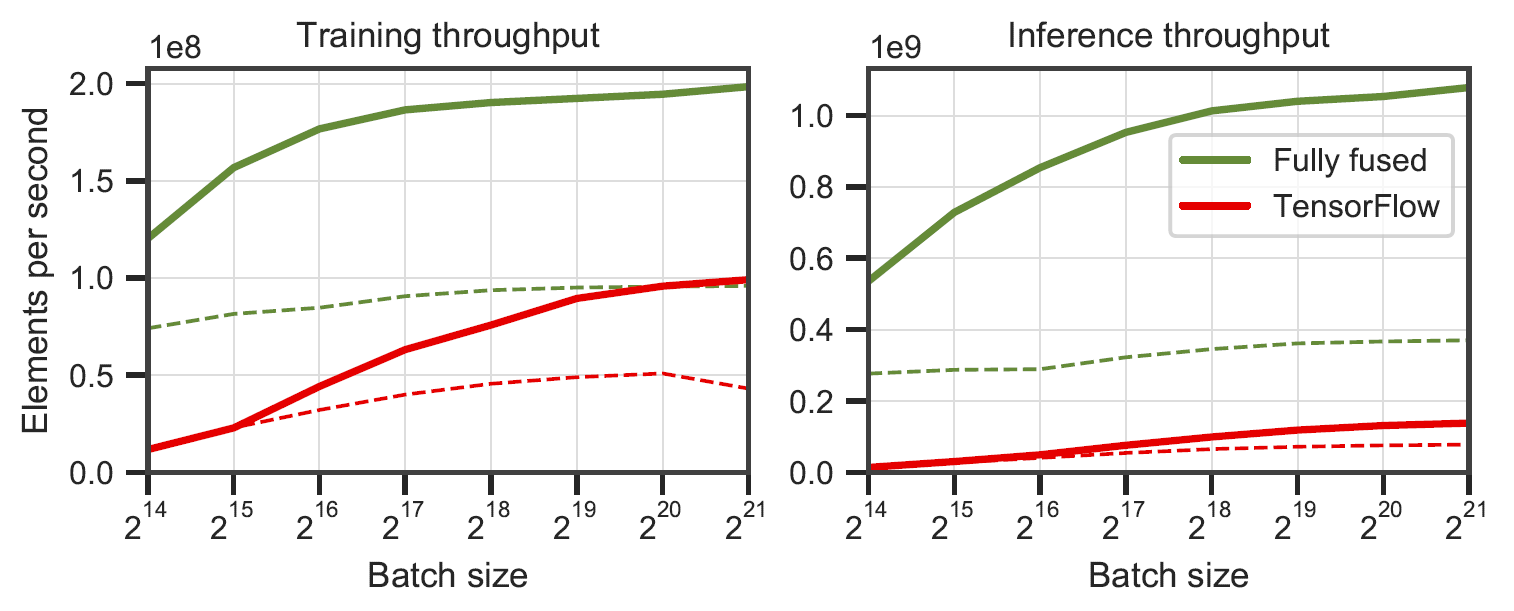 완전히 융합된 네트워크와 XLA가 포함된 TensorFlow v2.5.0. RTX 3090의 64개(실선) 및 128개(점선) 뉴런 전체 다층 퍼셉트론에서 측정되었습니다
완전히 융합된 네트워크와 XLA가 포함된 TensorFlow v2.5.0. RTX 3090의 64개(실선) 및 128개(점선) 뉴런 전체 다층 퍼셉트론에서 측정되었습니다 benchmarks/bench_ours.cu 및 benchmarks/bench_tensorflow.py 에서 data/config_oneblob.json 사용하여 생성되었습니다.
작은 CUDA 신경망에는 간단한 C++/CUDA API가 있습니다.
# include < tiny-cuda-nn/common.h >
// Configure the model
nlohmann::json config = {
{ " loss " , {
{ " otype " , " L2 " }
}},
{ " optimizer " , {
{ " otype " , " Adam " },
{ " learning_rate " , 1e-3 },
}},
{ " encoding " , {
{ " otype " , " HashGrid " },
{ " n_levels " , 16 },
{ " n_features_per_level " , 2 },
{ " log2_hashmap_size " , 19 },
{ " base_resolution " , 16 },
{ " per_level_scale " , 2.0 },
}},
{ " network " , {
{ " otype " , " FullyFusedMLP " },
{ " activation " , " ReLU " },
{ " output_activation " , " None " },
{ " n_neurons " , 64 },
{ " n_hidden_layers " , 2 },
}},
};
using namespace tcnn ;
auto model = create_from_config(n_input_dims, n_output_dims, config);
// Train the model (batch_size must be a multiple of tcnn::BATCH_SIZE_GRANULARITY)
GPUMatrix< float > training_batch_inputs (n_input_dims, batch_size);
GPUMatrix< float > training_batch_targets (n_output_dims, batch_size);
for ( int i = 0 ; i < n_training_steps; ++i) {
generate_training_batch (&training_batch_inputs, &training_batch_targets); // <-- your code
float loss;
model. trainer -> training_step (training_batch_inputs, training_batch_targets, &loss);
std::cout << " iteration= " << i << " loss= " << loss << std::endl;
}
// Use the model
GPUMatrix< float > inference_inputs (n_input_dims, batch_size);
generate_inputs (&inference_inputs); // <-- your code
GPUMatrix< float > inference_outputs (n_output_dims, batch_size);
model.network-> inference (inference_inputs, inference_outputs);우리는 이미지 함수 (x,y) -> (R,G,B) 를 학습하는 샘플 애플리케이션을 제공합니다. 다음을 통해 실행할 수 있습니다.
tiny-cuda-nn$ ./build/mlp_learning_an_image data/images/albert.jpg data/config_hash.json두 번의 훈련 단계마다 이미지를 생성합니다. RTX 4090의 기본 구성을 사용하면 각 1000단계에 1초가 조금 넘게 걸립니다.
| 10단계 | 100걸음 | 1000걸음 | 참고 이미지 |
|---|---|---|---|
 |  |  |  |
n_neurons 매개변수를 줄이거나 대신 CutlassMLP (호환성이 높지만 속도가 느림)를 사용해야 합니다.Linux를 사용하는 경우 다음 패키지를 설치하십시오.
sudo apt-get install build-essential git 또한 /usr/local/ 에 CUDA를 설치하고 PATH에 CUDA 설치를 추가하는 것이 좋습니다. 예를 들어, CUDA 11.4를 사용하는 경우 ~/.bashrc 에 다음을 추가하세요.
export PATH= " /usr/local/cuda-11.4/bin: $PATH "
export LD_LIBRARY_PATH= " /usr/local/cuda-11.4/lib64: $LD_LIBRARY_PATH " 다음 명령을 사용하여 이 저장소와 모든 하위 모듈을 복제하는 것으로 시작합니다.
$ git clone --recursive https://github.com/nvlabs/tiny-cuda-nn
$ cd tiny-cuda-nn그런 다음 CMake를 사용하여 프로젝트를 빌드합니다. (Windows에서는 개발자 명령 프롬프트에 있어야 합니다.)
tiny-cuda-nn$ cmake . -B build -DCMAKE_BUILD_TYPE=RelWithDebInfo
tiny-cuda-nn$ cmake --build build --config RelWithDebInfo -j 설명할 수 없는 이유로 컴파일이 실패하거나 1시간 이상 걸리는 경우 메모리가 부족할 수 있습니다. 이 경우 -j 없이 위 명령을 실행해 보세요.
tiny-cuda-nn 에는 Python 컨텍스트 내에서 빠른 MLP 및 입력 인코딩을 사용할 수 있는 PyTorch 확장이 함께 제공됩니다. 이러한 바인딩은 전체 Python 구현보다 훨씬 더 빠를 수 있습니다. 특히 다중 해상도 해시 인코딩의 경우.
그럼에도 불구하고 Python/PyTorch의 오버헤드는 배치 크기가 작은 경우 광범위할 수 있습니다. 예를 들어 배치 크기가 64k인 경우 번들
mlp_learning_an_image예제는 PyTorch를 통해 기본 CUDA보다 ~2배 느립니다 . 배치 크기가 256k 이상(기본값)이면 성능이 훨씬 더 비슷해집니다.
최신 CUDA 지원 버전의 PyTorch를 사용하여 Python 3.X 환경을 설정하는 것부터 시작하세요. 그런 다음 호출
pip install git+https://github.com/NVlabs/tiny-cuda-nn/ # subdirectory=bindings/torch또는 tiny-cuda-nn 의 로컬 복제본에서 설치하려면 다음을 호출하십시오.
tiny-cuda-nn$ cd bindings/torch
tiny-cuda-nn/bindings/torch$ python setup.py install성공하면 다음 예와 같이 tiny-cuda-nn 모델을 사용할 수 있습니다.
import commentjson as json
import tinycudann as tcnn
import torch
with open ( "data/config_hash.json" ) as f :
config = json . load ( f )
# Option 1: efficient Encoding+Network combo.
model = tcnn . NetworkWithInputEncoding (
n_input_dims , n_output_dims ,
config [ "encoding" ], config [ "network" ]
)
# Option 2: separate modules. Slower but more flexible.
encoding = tcnn . Encoding ( n_input_dims , config [ "encoding" ])
network = tcnn . Network ( encoding . n_output_dims , n_output_dims , config [ "network" ])
model = torch . nn . Sequential ( encoding , network ) 예제는 samples/mlp_learning_an_image_pytorch.py 참조하세요.
다음은 이 프레임워크의 구성 요소를 요약한 것입니다. JSON 문서에는 구성 옵션이 나열되어 있습니다.
| 네트워크 | ||
|---|---|---|
| 완전히 융합된 MLP | src/fully_fused_mlp.cu | 작은 다층 퍼셉트론(MLP)을 매우 빠르게 구현합니다. |
| 커틀라스 MLP | src/cutlass_mlp.cu | CUTLASS의 GEMM 루틴을 기반으로 한 MLP입니다. 완전히 융합된 것보다 느리지만 더 큰 네트워크를 처리하고 여전히 상당히 빠릅니다. |
| 입력 인코딩 | ||
|---|---|---|
| 합성물 | include/tiny-cuda-nn/encodings/composite.h | 여러 인코딩을 구성할 수 있습니다. 예를 들어 Neural Radiance Caching 인코딩 [Müller et al. 2021]. |
| 빈도 | include/tiny-cuda-nn/encodings/frequency.h | NeRF의 [Mildenhall et al. 2020] 위치 인코딩은 모든 차원에 동일하게 적용됩니다. |
| 그리드 | include/tiny-cuda-nn/encodings/grid.h | 훈련 가능한 다중 해상도 그리드를 기반으로 한 인코딩. 즉각적인 신경 그래픽 프리미티브에 사용됨 [Müller et al. 2022]. 그리드는 해시테이블, 고밀도 스토리지 또는 타일형 스토리지로 뒷받침될 수 있습니다. |
| 신원 | include/tiny-cuda-nn/encodings/identity.h | 값을 그대로 유지합니다. |
| 원블롭 | include/tiny-cuda-nn/encodings/oneblob.h | 신경 중요도 샘플링 [Müller et al. 2019] 및 신경 제어 변형 [Müller et al. 2020]. |
| 구형고조파 | include/tiny-cuda-nn/encodings/spherical_harmonics.h | 구성 요소별 인코딩보다 방향 벡터에 더 적합한 주파수 공간 인코딩입니다. |
| 트라이앵글웨이브 | include/tiny-cuda-nn/encodings/triangle_wave.h | NeRF 인코딩에 대한 저렴한 대안입니다. 신경 복사 캐싱에 사용됨 [Müller et al. 2021]. |
| 사상자 수 | ||
|---|---|---|
| L1 | include/tiny-cuda-nn/losses/l1.h | 표준 L1 손실. |
| 상대 L1 | include/tiny-cuda-nn/losses/l1.h | 네트워크 예측으로 정규화된 상대 L1 손실입니다. |
| 마페 | include/tiny-cuda-nn/losses/mape.h | 평균 절대 백분율 오차(MAPE)입니다. 상대 L1과 동일하지만 대상에 의해 정규화됩니다. |
| 스마페 | include/tiny-cuda-nn/losses/smape.h | 대칭 평균 절대 백분율 오류(SMape). 상대 L1과 동일하지만 예측 평균과 목표로 정규화됩니다. |
| L2 | include/tiny-cuda-nn/losses/l2.h | 표준 L2 손실. |
| 상대 L2 | include/tiny-cuda-nn/losses/relative_l2.h | 네트워크 예측으로 정규화된 상대 L2 손실 [Lehtinen et al. 2018]. |
| 상대 L2 휘도 | include/tiny-cuda-nn/losses/relative_l2_luminance.h | 위와 동일하지만 네트워크 예측의 휘도로 정규화됩니다. 네트워크 예측이 RGB인 경우에만 적용 가능합니다. 신경 복사 캐싱에 사용됨 [Müller et al. 2021]. |
| 교차 엔트로피 | include/tiny-cuda-nn/losses/cross_entropy.h | 표준 교차 엔트로피 손실. 네트워크 예측이 PDF인 경우에만 적용 가능합니다. |
| 변화 | include/tiny-cuda-nn/losses/variance_is.h | 표준 분산 손실. 네트워크 예측이 PDF인 경우에만 적용 가능합니다. |
| 옵티마이저 | ||
|---|---|---|
| 아담 | include/tiny-cuda-nn/optimizers/adam.h | AdaBound로 일반화된 Adam 구현 [Kingma and Ba 2014] [Luo et al. 2019]. |
| 노보그라드 | include/tiny-cuda-nn/optimizers/lookahead.h | Novograd 구현 [Ginsburg et al. 2019]. |
| SGD | include/tiny-cuda-nn/optimizers/sgd.h | 표준 확률적 경사하강법(SGD). |
| 샴푸 | include/tiny-cuda-nn/optimizers/shampoo.h | 2차 샴푸 최적화 구현 [Gupta et al. 2018] 자체 최적화와 Anil et al. [2020]. |
| 평균 | include/tiny-cuda-nn/optimizers/average.h | 다른 최적화 프로그램을 래핑하고 마지막 N 반복에 대한 가중치의 선형 평균을 계산합니다. 평균은 추론에만 사용됩니다(훈련에 피드백되지 않음). |
| 일괄 처리 | include/tiny-cuda-nn/optimizers/batched.h | 평균 그라데이션에서 N 단계마다 중첩된 최적화 프로그램을 호출하여 다른 최적화 프로그램을 래핑합니다. 배치 크기를 늘리는 것과 동일한 효과가 있지만 일정한 양의 메모리만 필요합니다. |
| 합성물 | include/tiny-cuda-nn/optimizers/composite.h | 다양한 매개변수에 대해 여러 최적화 프로그램을 사용할 수 있습니다. |
| EMA | include/tiny-cuda-nn/optimizers/average.h | 다른 최적화 프로그램을 래핑하고 가중치의 지수 이동 평균을 계산합니다. 평균은 추론에만 사용됩니다(훈련에 피드백되지 않음). |
| 지수적 붕괴 | include/tiny-cuda-nn/optimizers/exponential_decay.h | 다른 최적화 프로그램을 래핑하고 조각별로 일정한 지수 학습 속도 감소를 수행합니다. |
| 미리보기 | include/tiny-cuda-nn/optimizers/lookahead.h | 예견 알고리즘을 구현하는 또 다른 최적화 프로그램을 래핑합니다 [Zhang et al. 2019]. |
이 프레임워크는 BSD 3절 라이선스에 따라 라이선스가 부여됩니다. 자세한 내용은 LICENSE.txt 참조하세요.
연구에 활용하실 경우 다음을 통해 인용해 주시면 감사하겠습니다.
@software { tiny-cuda-nn ,
author = { M"uller, Thomas } ,
license = { BSD-3-Clause } ,
month = { 4 } ,
title = { {tiny-cuda-nn} } ,
url = { https://github.com/NVlabs/tiny-cuda-nn } ,
version = { 1.7 } ,
year = { 2021 }
}비즈니스 문의 사항이 있는 경우 당사 웹사이트를 방문하여 NVIDIA 연구 라이선스 양식을 제출해 주세요.
무엇보다도 이 프레임워크는 다음 출판물을 지원합니다.
다중 해상도 해시 인코딩을 사용한 즉각적인 신경 그래픽 프리미티브
토마스 뮐러, 알렉스 에반스, 크리스토프 쉬드, 알렉산더 켈러
ACM 그래픽 트랜잭션( SIGGRAPH ), 2022년 7월
웹사이트 / 종이 / 코드 / 비디오 / BibTeX
이미지에서 삼각형 3D 모델, 재료, 조명 추출
Jacob Munkberg, Jon Hasselgren, Tianchang Shen, Jun Gao, Wenzheng Chen, Alex Evans, Thomas Müller, Sanja Fidler
CVPR(구두) , 2022년 6월
웹사이트 / 종이 / 비디오 / BibTeX
경로 추적을 위한 실시간 신경 복사 캐싱
토마스 뮐러, 파브리스 루셀, 얀 노박, 알렉산더 켈러
ACM 그래픽 트랜잭션( SIGGRAPH ), 2021년 8월
종이 / GTC 토크 / 비디오 / 인터랙티브 결과 뷰어 / BibTeX
또한 다음 소프트웨어도 포함됩니다.
NerfAcc: 일반적인 NeRF 가속 도구 상자
루이롱 리, 매튜 탄식, 가나자와 앙주
https://github.com/KAIR-BAIR/nerfacc
Nerfstudio: 신경 방사 필드 개발을 위한 프레임워크
Matthew Tancik*, Ethan Weber*, Evonne Ng*, Ruilong Li, Brent Yi, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, Angjoo Kanazawa
https://github.com/nerfstudio-project/nerfstudio
귀하의 출판물이나 소프트웨어가 목록에 없으면 언제든지 풀 요청을 해주세요.
유용한 토론을 해준 NRC 작성자와 이 프레임워크의 인프라 일부를 제공하고 CUDA 내에서 TensorCores를 활용하는 데 도움을 준 Nikolaus Binder에게 특별히 감사드립니다.


