DALLE2 pytorch
1.15.6
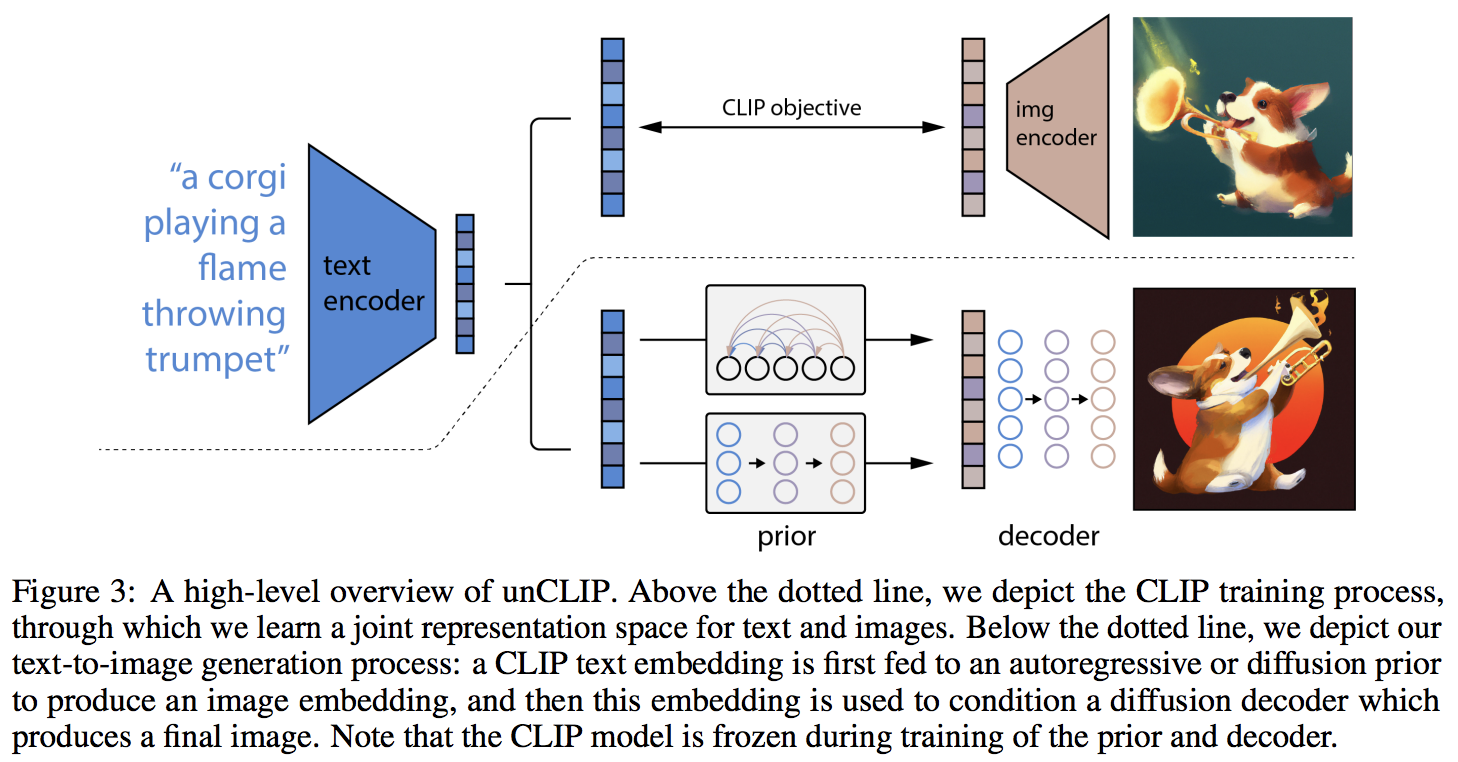
OpenAI의 업데이트된 텍스트-이미지 합성 신경망인 DALL-E 2를 Pytorch에서 구현합니다.
야닉 킬처(Yannic Kilcher) 요약 | AssemblyAI 설명자
주요 참신함은 CLIP의 텍스트 임베딩을 기반으로 이미지 임베딩을 예측하는 이전 네트워크(자동 회귀 변환기이든 확산 네트워크이든)에 대한 추가 간접 계층인 것 같습니다. 특히, 이 저장소는 가장 성능이 좋은 변형인 확산 사전 네트워크만 구축합니다(그러나 노이즈 제거 네트워크로 인과 변환기를 포함합니까?).
현재 이 모델은 text-to-image를 위한 SOTA입니다.
LAION 커뮤니티와 함께 복제에 도움을 주고 싶으신 분은 참여해 주세요 | 야닉 인터뷰
22년 5월 23일부터 더 이상 SOTA가 아닙니다. SOTA가 여기에 있을 것입니다. Jax 버전과 텍스트-비디오 프로젝트는 훨씬 더 간단하기 때문에 Imagen 아키텍처로 전환될 것입니다.
연구 그룹은 이 저장소의 코드를 사용하여 CLIP 세대에 앞서 기능적 확산을 훈련했습니다. 프리프린트가 출시되면 작업을 공유할 예정입니다. 이것과 Katherine의 자체 실험은 추가 이전이 세대의 다양성을 증가시킨다는 OpenAI의 발견을 검증합니다.
이제 옥스포드 꽃에 대한 실험 설정에서 디코더가 무조건 생성에 대해 작동하는 것이 확인되었습니다. 2명의 연구원도 Decoder가 자신들을 위해 작동하고 있음을 확인했습니다.

21,000걸음 진행 중
Justin Pinkney는 자신의 CLIP to Stylegan2 텍스트-이미지 애플리케이션을 위해 저장소에서 이전에 확산을 성공적으로 교육했습니다.
Romain은 아무런 문제 없이 사용 가능한 스크립트를 사용하여 훈련을 800개의 GPU로 확장했습니다.
이 라이브러리는 다음의 도움 없이는 이 작업 상태에 도달하지 못했을 것입니다.
...그리고 다른 많은 것들. 감사합니다!
$ pip install dalle2-pytorchDALLE-2를 교육하는 것은 3단계 프로세스이며 CLIP 교육이 가장 중요합니다.
CLIP을 교육하려면 x-clip 패키지를 사용하거나 이미 많은 복제 노력이 진행 중인 LAION 디스코드에 참여할 수 있습니다.
이 저장소는 초보자를 위한 x-clip 과의 통합을 보여줍니다.
import torch
from dalle2_pytorch import CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
use_all_token_embeds = True , # whether to use fine-grained contrastive learning (FILIP)
decoupled_contrastive_learning = True , # use decoupled contrastive learning (DCL) objective function, removing positive pairs from the denominator of the InfoNCE loss (CLOOB + DCL)
extra_latent_projection = True , # whether to use separate projections for text-to-image vs image-to-text comparisons (CLOOB)
use_visual_ssl = True , # whether to do self supervised learning on images
visual_ssl_type = 'simclr' , # can be either 'simclr' or 'simsiam', depending on using DeCLIP or SLIP
use_mlm = False , # use masked language learning (MLM) on text (DeCLIP)
text_ssl_loss_weight = 0.05 , # weight for text MLM loss
image_ssl_loss_weight = 0.05 # weight for image self-supervised learning loss
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True # needs to be set to True to return contrastive loss
)
loss . backward ()
# do the above with as many texts and images as possible in a loop그런 다음 위의 훈련된 CLIP에서 나오는 이미지 임베딩을 기반으로 이미지를 생성하는 방법을 배우는 디코더를 훈련해야 합니다.
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 1 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 1 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# unet for the decoder
unet = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
# decoder, which contains the unet and clip
decoder = Decoder (
unet = unet ,
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed images into decoder
loss = decoder ( images )
loss . backward ()
# do the above for many many many many steps
# then it will learn to generate images based on the CLIP image embeddings마지막으로 논문의 주요 기여입니다. 저장소는 확산 사전 네트워크를 제공합니다. CLIP 텍스트 임베딩을 가져와서 CLIP 이미지 임베딩을 생성하려고 시도합니다. 다시 말하지만, 첫 번째 단계부터 훈련된 CLIP이 필요합니다.
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior ( text , images )
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings논문에서 그들은 실제로 고해상도 이미지 합성을 위해 Jonathan Ho(DALL-E v2에서 사용되는 핵심 기술인 DDPM의 원저자)가 최근 발견한 기술을 사용했습니다.
이는 이 프레임워크 내에서 쉽게 사용할 수 있습니다.
import torch
from dalle2_pytorch import Unet , Decoder , CLIP
# trained clip from step 1
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# 2 unets for the decoder (a la cascading DDPM)
unet1 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 )
). cuda ()
unet2 = Unet (
dim = 32 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
# decoder, which contains the unet(s) and clip
decoder = Decoder (
clip = clip ,
unet = ( unet1 , unet2 ), # insert both unets in order of low resolution to highest resolution (you can have as many stages as you want here)
image_sizes = ( 256 , 512 ), # resolutions, 256 for first unet, 512 for second. these must be unique and in ascending order (matches with the unets passed in)
timesteps = 1000 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
# mock images (get a lot of this)
images = torch . randn ( 4 , 3 , 512 , 512 ). cuda ()
# feed images into decoder, specifying which unet you want to train
# each unet can be trained separately, which is one of the benefits of the cascading DDPM scheme
loss = decoder ( images , unet_number = 1 )
loss . backward ()
loss = decoder ( images , unet_number = 2 )
loss . backward ()
# do the above for many steps for both unets 마지막으로 텍스트에서 DALL-E2 이미지를 생성합니다. 학습된 DiffusionPrior 와 Decoder ( CLIP , 인과 변환기 및 unet을 래핑함)를 삽입합니다.
from dalle2_pytorch import DALLE2
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
# send the text as a string if you want to use the simple tokenizer from DALLE v1
# or you can do it as token ids, if you have your own tokenizer
texts = [ 'glistening morning dew on a flower petal' ]
images = dalle2 ( texts ) # (1, 3, 256, 256)그게 다야!
아래에서 전체 스크립트를 살펴보겠습니다.
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , CLIP
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# train
loss = clip (
text ,
images ,
return_loss = True
)
loss . backward ()
# do above for many steps ...
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 1000 ,
sample_timesteps = 64 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
text_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 100 ,
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'cute puppy chasing after a squirrel' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)이 추가 정보의 모든 내용은 오류 없이 실행되어야 합니다.
CLIP이 훈련된 크기(예: 512x512)(256x256)보다 큰 이미지에 대해 디코더를 훈련할 수도 있습니다. 이미지 임베딩을 위해 이미지 크기가 CLIP 이미지 해상도로 조정됩니다.
일반인의 경우 걱정하지 마세요. 최소한 소규모 교육의 경우 교육이 모두 CLI 도구로 자동화됩니다.
확장할 때 이전 네트워크를 교육하기 전에 먼저 이미지와 텍스트를 해당 임베딩으로 사전 처리할 가능성이 높습니다. image_embed , text_embed 및 선택적으로 text_encodings 전달하면 쉽게 수행할 수 있습니다.
아래의 작업 예
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior , CLIP
# get trained CLIP from step one
clip = CLIP (
dim_text = 512 ,
dim_image = 512 ,
dim_latent = 512 ,
num_text_tokens = 49408 ,
text_enc_depth = 6 ,
text_seq_len = 256 ,
text_heads = 8 ,
visual_enc_depth = 6 ,
visual_image_size = 256 ,
visual_patch_size = 32 ,
visual_heads = 8 ,
). cuda ()
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = diffusion_prior . clip . embed_image ( images ). image_embed
clip_text_embeds = diffusion_prior . clip . embed_text ( text ). text_embed
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings CLIP 사용하지 않고 완전히 전환할 수도 있습니다. 이 경우 초기화 시 image_embed_dim DiffusionPrior 에 전달해야 합니다.
import torch
from dalle2_pytorch import DiffusionPriorNetwork , DiffusionPrior
# setup prior network, which contains an autoregressive transformer
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
# diffusion prior network, which contains the CLIP and network (with transformer) above
diffusion_prior = DiffusionPrior (
net = prior_network ,
image_embed_dim = 512 , # this needs to be set
timesteps = 100 ,
cond_drop_prob = 0.2 ,
condition_on_text_encodings = False # this probably should be true, but just to get Laion started
). cuda ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# precompute the text and image embeddings
# here using the diffusion prior class, but could be done with CLIP alone
clip_image_embeds = torch . randn ( 4 , 512 ). cuda ()
clip_text_embeds = torch . randn ( 4 , 512 ). cuda ()
# feed text and images into diffusion prior network
loss = diffusion_prior (
text_embed = clip_text_embeds ,
image_embed = clip_image_embeds
)
loss . backward ()
# do the above for many many many steps
# now the diffusion prior can generate image embeddings from the text embeddings 아직 출시되지 않은 더 강력한 CLIP을 사용할 가능성이 있지만 처음부터 자체 CLIP을 교육하고 싶지 않다면 출시된 CLIP 중 하나를 사용할 수 있습니다. 이를 통해 커뮤니티는 논문의 결론을 보다 신속하게 검증할 수 있습니다.
사전 학습된 OpenAI CLIP을 사용하려면 OpenAIClipAdapter 가져와서 DiffusionPrior 또는 Decoder 에 전달하면 됩니다.
import torch
from dalle2_pytorch import DALLE2 , DiffusionPriorNetwork , DiffusionPrior , Unet , Decoder , OpenAIClipAdapter
# openai pretrained clip - defaults to ViT-B/32
clip = OpenAIClipAdapter ()
# mock data
text = torch . randint ( 0 , 49408 , ( 4 , 256 )). cuda ()
images = torch . randn ( 4 , 3 , 256 , 256 ). cuda ()
# prior networks (with transformer)
prior_network = DiffusionPriorNetwork (
dim = 512 ,
depth = 6 ,
dim_head = 64 ,
heads = 8
). cuda ()
diffusion_prior = DiffusionPrior (
net = prior_network ,
clip = clip ,
timesteps = 100 ,
cond_drop_prob = 0.2
). cuda ()
loss = diffusion_prior ( text , images )
loss . backward ()
# do above for many steps ...
# decoder (with unet)
unet1 = Unet (
dim = 128 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
text_embed_dim = 512 ,
cond_on_text_encodings = True # set to True for any unets that need to be conditioned on text encodings (ex. first unet in cascade)
). cuda ()
unet2 = Unet (
dim = 16 ,
image_embed_dim = 512 ,
cond_dim = 128 ,
channels = 3 ,
dim_mults = ( 1 , 2 , 4 , 8 , 16 )
). cuda ()
decoder = Decoder (
unet = ( unet1 , unet2 ),
image_sizes = ( 128 , 256 ),
clip = clip ,
timesteps = 1000 ,
sample_timesteps = ( 250 , 27 ),
image_cond_drop_prob = 0.1 ,
text_cond_drop_prob = 0.5
). cuda ()
for unet_number in ( 1 , 2 ):
loss = decoder ( images , text = text , unet_number = unet_number ) # this can optionally be decoder(images, text) if you wish to condition on the text encodings as well, though it was hinted in the paper it didn't do much
loss . backward ()
# do above for many steps
dalle2 = DALLE2 (
prior = diffusion_prior ,
decoder = decoder
)
images = dalle2 (
[ 'a butterfly trying to escape a tornado' ],
cond_scale = 2. # classifier free guidance strength (> 1 would strengthen the condition)
)
# save your image (in this example, of size 256x256)또는 Open Clip을 사용할 수도 있습니다.
$ pip install open-clip-torch전. Romain이 훈련한 SOTA Open Clip 모델 사용


