

마을의 새로운 로봇: SO-100

팔당 $110의 가격으로 더욱 저렴한 로봇을 만드는 방법에 대한 새로운 튜토리얼을 추가했습니다!
노트북만으로 몇 가지 동작을 보여주면서 새로운 기술을 가르쳐 보세요.
그렇다면 직접 만든 로봇이 자율적으로 행동하는 모습을 지켜보시겠습니까?
SO-100에 대한 전체 튜토리얼 링크를 따라가세요.
LeRobot: 실제 로봇 공학을 위한 최첨단 AI
? LeRobot은 PyTorch에서 실제 로봇 공학을 위한 모델, 데이터 세트 및 도구를 제공하는 것을 목표로 합니다. 목표는 로봇공학에 대한 진입 장벽을 낮추어 모든 사람이 데이터 세트와 사전 훈련된 모델을 공유함으로써 기여하고 혜택을 누릴 수 있도록 하는 것입니다.
? LeRobot에는 모방 학습 및 강화 학습에 중점을 두고 현실 세계로 이전되는 것으로 입증된 최첨단 접근 방식이 포함되어 있습니다.
? LeRobot은 이미 로봇을 조립하지 않고도 시작할 수 있도록 사전 훈련된 모델 세트, 사람이 수집한 데모가 포함된 데이터 세트 및 시뮬레이션 환경을 제공합니다. 앞으로 몇 주 안에 가장 저렴하고 성능이 뛰어난 로봇에 실제 로봇 공학에 대한 지원을 점점 더 많이 추가할 계획입니다.
? LeRobot은 Hugging Face 커뮤니티 페이지(huggingface.co/lerobot)에서 사전 훈련된 모델과 데이터 세트를 호스팅합니다.
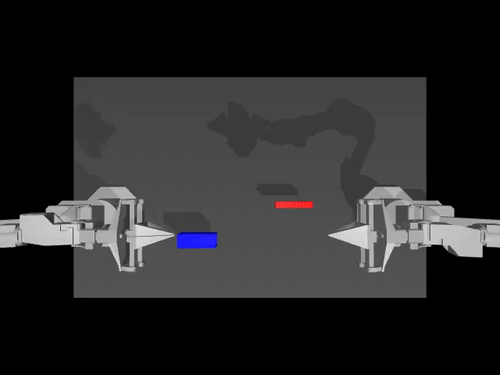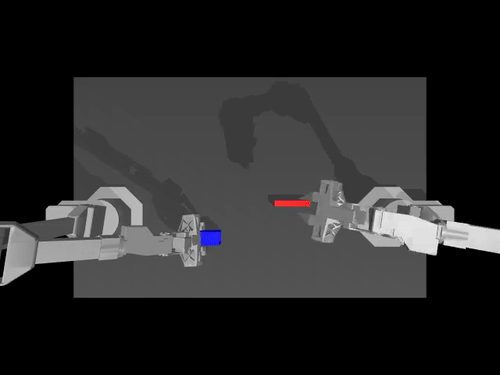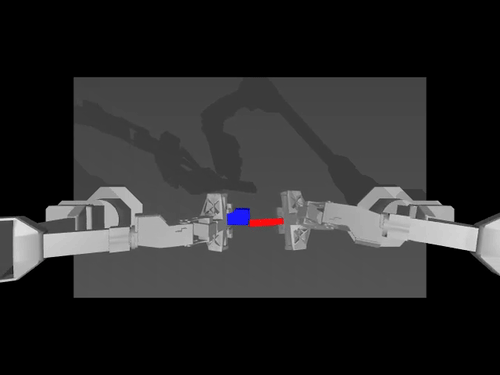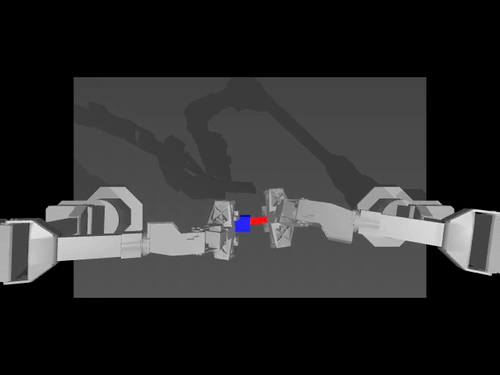 |  |  |
| ALOHA 환경에 대한 ACT 정책 | SimXArm 환경의 TDMPC 정책 | PushT 환경의 확산 정책 |
소스 코드를 다운로드하세요:
git clone https://github.com/huggingface/lerobot.git
cd lerobot Python 3.10으로 가상 환경을 생성하고 활성화합니다(예: miniconda 사용).
conda create -y -n lerobot python=3.10
conda activate lerobot설치하다 ? 르로봇:
pip install -e .참고: 플랫폼에 따라 이 단계에서 빌드 오류가 발생하면 일부 종속성을 빌드하기 위해
cmake및build-essential설치해야 할 수도 있습니다. Linux:sudo apt-get install cmake build-essential
시뮬레이션의 경우 ? LeRobot은 추가로 설치할 수 있는 체육관 환경을 제공합니다.
예를 들어, 설치하려면? 알로하 및 푸시 기능이 있는 LeRobot은 다음을 사용합니다.
pip install -e " .[aloha, pusht] "실험 추적을 위해 가중치 및 편향을 사용하려면 다음으로 로그인하세요.
wandb login(참고: 구성에서 WandB도 활성화해야 합니다. 아래를 참조하세요.)
.
├── examples # contains demonstration examples, start here to learn about LeRobot
| └── advanced # contains even more examples for those who have mastered the basics
├── lerobot
| ├── configs # contains hydra yaml files with all options that you can override in the command line
| | ├── default.yaml # selected by default, it loads pusht environment and diffusion policy
| | ├── env # various sim environments and their datasets: aloha.yaml, pusht.yaml, xarm.yaml
| | └── policy # various policies: act.yaml, diffusion.yaml, tdmpc.yaml
| ├── common # contains classes and utilities
| | ├── datasets # various datasets of human demonstrations: aloha, pusht, xarm
| | ├── envs # various sim environments: aloha, pusht, xarm
| | ├── policies # various policies: act, diffusion, tdmpc
| | ├── robot_devices # various real devices: dynamixel motors, opencv cameras, koch robots
| | └── utils # various utilities
| └── scripts # contains functions to execute via command line
| ├── eval.py # load policy and evaluate it on an environment
| ├── train.py # train a policy via imitation learning and/or reinforcement learning
| ├── control_robot.py # teleoperate a real robot, record data, run a policy
| ├── push_dataset_to_hub.py # convert your dataset into LeRobot dataset format and upload it to the Hugging Face hub
| └── visualize_dataset.py # load a dataset and render its demonstrations
├── outputs # contains results of scripts execution: logs, videos, model checkpoints
└── tests # contains pytest utilities for continuous integration
Hugging Face 허브에서 자동으로 데이터를 다운로드하는 데이터 세트 클래스를 사용하는 방법을 보여주는 예제 1을 확인하세요.
명령줄에서 스크립트를 실행하여 허브에 있는 데이터 세트의 에피소드를 로컬로 시각화할 수도 있습니다.
python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 또는 루트 DATA_DIR 환경 변수가 있는 로컬 폴더의 데이터 세트에서(다음 경우 데이터 세트는 ./my_local_data_dir/lerobot/pusht 에서 검색됩니다)
DATA_DIR= ' ./my_local_data_dir ' python lerobot/scripts/visualize_dataset.py
--repo-id lerobot/pusht
--episode-index 0 rerun.io 열리고 다음과 같이 카메라 스트림, 로봇 상태 및 동작이 표시됩니다.
우리 스크립트는 멀리 떨어진 서버에 저장된 데이터 세트를 시각화할 수도 있습니다. 자세한 지침은 python lerobot/scripts/visualize_dataset.py --help 참조하세요.
LeRobotDataset 형식 LeRobotDataset 형식의 데이터 세트는 사용이 매우 간단합니다. Hugging Face 허브의 저장소나 로컬 폴더에서 간단히 dataset = LeRobotDataset("lerobot/aloha_static_coffee") 사용하여 로드할 수 있으며 Hugging Face 및 PyTorch 데이터세트처럼 인덱싱할 수 있습니다. 예를 들어, dataset[0] 관측값과 모델에 제공할 준비가 된 PyTorch 텐서로서의 동작을 포함하는 데이터세트에서 단일 시간 프레임을 검색합니다.
LeRobotDataset 의 특징은 인덱스로 단일 프레임을 검색하는 대신 delta_timestamps 인덱스 프레임에 대한 상대 시간 목록으로 설정하여 인덱스 프레임과의 시간적 관계를 기반으로 여러 프레임을 검색할 수 있다는 것입니다. 예를 들어 delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} 사용하면 주어진 인덱스에 대해 4개의 프레임(1초, 0.5초 및 3개의 "이전" 프레임)을 검색할 수 있습니다. 인덱스 프레임 전 0.2초 및 인덱스 프레임 자체(0 항목에 해당) delta_timestamps 에 대한 자세한 내용은 예제 1_load_lerobot_dataset.py를 참조하세요.
내부적으로 LeRobotDataset 형식은 데이터를 직렬화하는 여러 가지 방법을 사용하며, 이는 이 형식을 더 자세히 사용하려는 경우 이해하는 데 유용할 수 있습니다. 우리는 카메라와 로봇 상태에 중점을 두고 강화 학습과 로봇 공학, 시뮬레이션 및 실제 세계에 존재하는 대부분의 기능과 특성을 포괄하는 유연하면서도 간단한 데이터 세트 형식을 만들려고 노력했지만 다른 유형의 감각으로 쉽게 확장할 수 있었습니다. 텐서로 표현될 수 있는 한 입력입니다.
다음은 dataset = LeRobotDataset("lerobot/aloha_static_coffee") 로 인스턴스화된 일반적인 LeRobotDataset 의 중요한 세부 정보와 내부 구조 구성입니다. 정확한 기능은 데이터 세트마다 변경되지만 주요 측면은 변경되지 않습니다.
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of en episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
LeRobotDataset 은 각 부분에 대해 여러 가지 널리 사용되는 파일 형식을 사용하여 직렬화됩니다.
safetensor 텐서 직렬화 형식을 사용하여 저장된 Episode_data_indexsafetensor 텐서 직렬화 형식을 사용하여 저장된 통계 HuggingFace 허브에서 데이터세트를 원활하게 업로드/다운로드할 수 있습니다. 로컬 데이터세트에서 작업하려면 데이터세트 시각화에 대한 위 섹션에 설명된 대로 DATA_DIR 환경 변수를 루트 데이터세트 폴더로 설정할 수 있습니다.
Hugging Face 허브에서 사전 학습된 정책을 다운로드하고 해당 환경에서 평가를 실행하는 방법을 보여주는 예제 2를 확인하세요.
또한 동일한 롤아웃 중에 여러 환경에 대한 평가를 병렬화할 수 있는 보다 유능한 스크립트를 제공합니다. 다음은 lerobot/diffusion_pusht에 호스팅된 사전 학습된 모델의 예입니다.
python lerobot/scripts/eval.py
-p lerobot/diffusion_pusht
eval.n_episodes=10
eval.batch_size=10참고: 자체 정책을 교육한 후 다음을 사용하여 체크포인트를 재평가할 수 있습니다.
python lerobot/scripts/eval.py -p {OUTPUT_DIR}/checkpoints/last/pretrained_model 자세한 지침은 python lerobot/scripts/eval.py --help 참조하세요.
Python에서 핵심 라이브러리를 사용하여 모델을 훈련하는 방법을 보여주는 예제 3과 명령줄에서 훈련 스크립트를 사용하는 방법을 보여주는 예제 4를 확인하세요.
일반적으로 교육 스크립트를 사용하여 모든 정책을 쉽게 교육할 수 있습니다. 다음은 삽입 작업을 위해 Aloha 시뮬레이션 환경에서 인간이 수집한 궤적에 대한 ACT 정책을 훈련하는 예입니다.
python lerobot/scripts/train.py
policy=act
env=aloha
env.task=AlohaInsertion-v0
dataset_repo_id=lerobot/aloha_sim_insertion_human 실험 디렉터리가 자동으로 생성되고 터미널에 노란색으로 표시됩니다. 이는 outputs/train/2024-05-05/20-21-12_aloha_act_default 처럼 보입니다. train.py python 명령에 다음 인수를 추가하여 실험 디렉터리를 수동으로 지정할 수 있습니다.
hydra.run.dir=your/new/experiment/dir 실험 디렉터리에는 다음과 같은 구조를 갖는 checkpoints 라는 폴더가 있습니다.
checkpoints
├── 000250 # checkpoint_dir for training step 250
│ ├── pretrained_model # Hugging Face pretrained model dir
│ │ ├── config.json # Hugging Face pretrained model config
│ │ ├── config.yaml # consolidated Hydra config
│ │ ├── model.safetensors # model weights
│ │ └── README.md # Hugging Face model card
│ └── training_state.pth # optimizer/scheduler/rng state and training step 체크포인트에서 훈련을 재개하려면 train.py python 명령에 다음을 추가할 수 있습니다.
hydra.run.dir=your/original/experiment/dir resume=true훈련을 위해 사전 훈련된 모델, 최적화 프로그램 및 스케줄러 상태를 로드합니다. 자세한 내용은 여기에서 훈련 재개에 대한 튜토리얼을 참조하세요.
훈련 및 평가 곡선 로깅에 wandb를 사용하려면 wandb login 일회성 설정 단계로 실행했는지 확인하세요. 그런 다음 위의 훈련 명령을 실행할 때 다음을 추가하여 구성에서 WandB를 활성화합니다.
wandb.enable=true실행을 위한 wandb 로그에 대한 링크도 터미널에 노란색으로 표시됩니다. 다음은 브라우저에서 어떻게 보이는지에 대한 예입니다. 로그에서 일반적으로 사용되는 일부 측정항목에 대한 설명도 여기에서 확인하세요.

참고: 효율성을 위해 훈련 중에 모든 체크포인트는 적은 수의 에피소드에서 평가됩니다. eval.n_episodes=500 사용하면 기본값보다 더 많은 에피소드를 평가할 수 있습니다. 또는 훈련 후에 더 많은 에피소드에서 가장 좋은 체크포인트를 재평가하거나 평가 설정을 변경할 수도 있습니다. 자세한 지침은 python lerobot/scripts/eval.py --help 참조하세요.
우리는 구성 파일( lerobot/configs 아래에 있음)을 구성하여 해당 원본 작업에서 특정 모델 변형의 SOTA 결과를 재현했습니다. 간단히 실행하면 다음과 같습니다.
python lerobot/scripts/train.py policy=diffusion env=pushtPushT 작업의 확산 정책에 대한 SOTA 결과를 재현합니다.
재생산 세부 정보와 함께 사전 훈련된 정책은 https://huggingface.co/lerobot의 "모델" 섹션에서 찾을 수 있습니다.
에 기여하고 싶다면? 르로봇님, 기여 가이드를 확인해 주세요.
허브에 데이터 세트를 추가하려면 Hugging Face 설정에서 생성할 수 있는 쓰기 액세스 토큰을 사용하여 로그인해야 합니다.
huggingface-cli login --token ${HUGGINGFACE_TOKEN} --add-to-git-credential 그런 다음 원시 데이터세트 폴더(예: data/aloha_static_pingpong_test_raw )를 가리키고 다음을 사용하여 데이터세트를 허브에 푸시합니다.
python lerobot/scripts/push_dataset_to_hub.py
--raw-dir data/aloha_static_pingpong_test_raw
--out-dir data
--repo-id lerobot/aloha_static_pingpong_test
--raw-format aloha_hdf5 자세한 지침은 python lerobot/scripts/push_dataset_to_hub.py --help 참조하세요.
데이터 세트 형식이 지원되지 않는 경우 pusht_zarr, umi_zarr, aloha_hdf5 또는 xarm_pkl과 같은 예제를 복사하여 lerobot/common/datasets/push_dataset_to_hub/${raw_format}_format.py 에서 자체 형식을 구현하세요.
정책을 교육한 후에는 ${hf_user}/${repo_name} (예: lerobot/diffusion_pusht)과 같은 허브 ID를 사용하여 Hugging Face 허브에 업로드할 수 있습니다.
먼저 실험 디렉터리 내에 있는 체크포인트 폴더를 찾아야 합니다(예: outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500 ). 그 안에는 다음을 포함해야 하는 pretrained_model 디렉터리가 있습니다.
config.json : 정책 구성의 직렬화된 버전입니다(정책의 데이터 클래스 구성에 따름).model.safetensors : Hugging Face Safetensors 형식으로 저장된 torch.nn.Module 매개변수 세트입니다.config.yaml : 정책, 환경 및 데이터 세트 구성을 포함하는 통합 Hydra 교육 구성입니다. 정책 구성은 config.json 과 정확히 일치해야 합니다. 환경 구성은 정책을 평가하려는 모든 사람에게 유용합니다. 데이터 세트 구성은 재현성을 위한 종이 추적 역할만 합니다.이를 허브에 업로드하려면 다음을 실행합니다.
huggingface-cli upload ${hf_user} / ${repo_name} path/to/pretrained_model다른 사람들이 귀하의 정책을 어떻게 사용할 수 있는지에 대한 예는 eval.py를 참조하세요.
정책 평가를 프로파일링하는 코드 조각의 예:
from torch . profiler import profile , record_function , ProfilerActivity
def trace_handler ( prof ):
prof . export_chrome_trace ( f"tmp/trace_schedule_ { prof . step_num } .json" )
with profile (
activities = [ ProfilerActivity . CPU , ProfilerActivity . CUDA ],
schedule = torch . profiler . schedule (
wait = 2 ,
warmup = 2 ,
active = 3 ,
),
on_trace_ready = trace_handler
) as prof :
with record_function ( "eval_policy" ):
for i in range ( num_episodes ):
prof . step ()
# insert code to profile, potentially whole body of eval_policy function 원한다면 다음과 같이 이 저작물을 인용할 수 있습니다.
@misc { cadene2024lerobot ,
author = { Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Wolf, Thomas } ,
title = { LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch } ,
howpublished = " url{https://github.com/huggingface/lerobot} " ,
year = { 2024 }
}또한 특정 정책 아키텍처, 사전 훈련된 모델 또는 데이터 세트를 사용하는 경우 아래와 같이 해당 작업의 원저자를 인용하는 것이 좋습니다.
@article { chi2024diffusionpolicy ,
author = { Cheng Chi and Zhenjia Xu and Siyuan Feng and Eric Cousineau and Yilun Du and Benjamin Burchfiel and Russ Tedrake and Shuran Song } ,
title = { Diffusion Policy: Visuomotor Policy Learning via Action Diffusion } ,
journal = { The International Journal of Robotics Research } ,
year = { 2024 } ,
} @article { zhao2023learning ,
title = { Learning fine-grained bimanual manipulation with low-cost hardware } ,
author = { Zhao, Tony Z and Kumar, Vikash and Levine, Sergey and Finn, Chelsea } ,
journal = { arXiv preprint arXiv:2304.13705 } ,
year = { 2023 }
} @inproceedings { Hansen2022tdmpc ,
title = { Temporal Difference Learning for Model Predictive Control } ,
author = { Nicklas Hansen and Xiaolong Wang and Hao Su } ,
booktitle = { ICML } ,
year = { 2022 }
} @article { lee2024behavior ,
title = { Behavior generation with latent actions } ,
author = { Lee, Seungjae and Wang, Yibin and Etukuru, Haritheja and Kim, H Jin and Shafiullah, Nur Muhammad Mahi and Pinto, Lerrel } ,
journal = { arXiv preprint arXiv:2403.03181 } ,
year = { 2024 }
}

