nmt
1.0.0
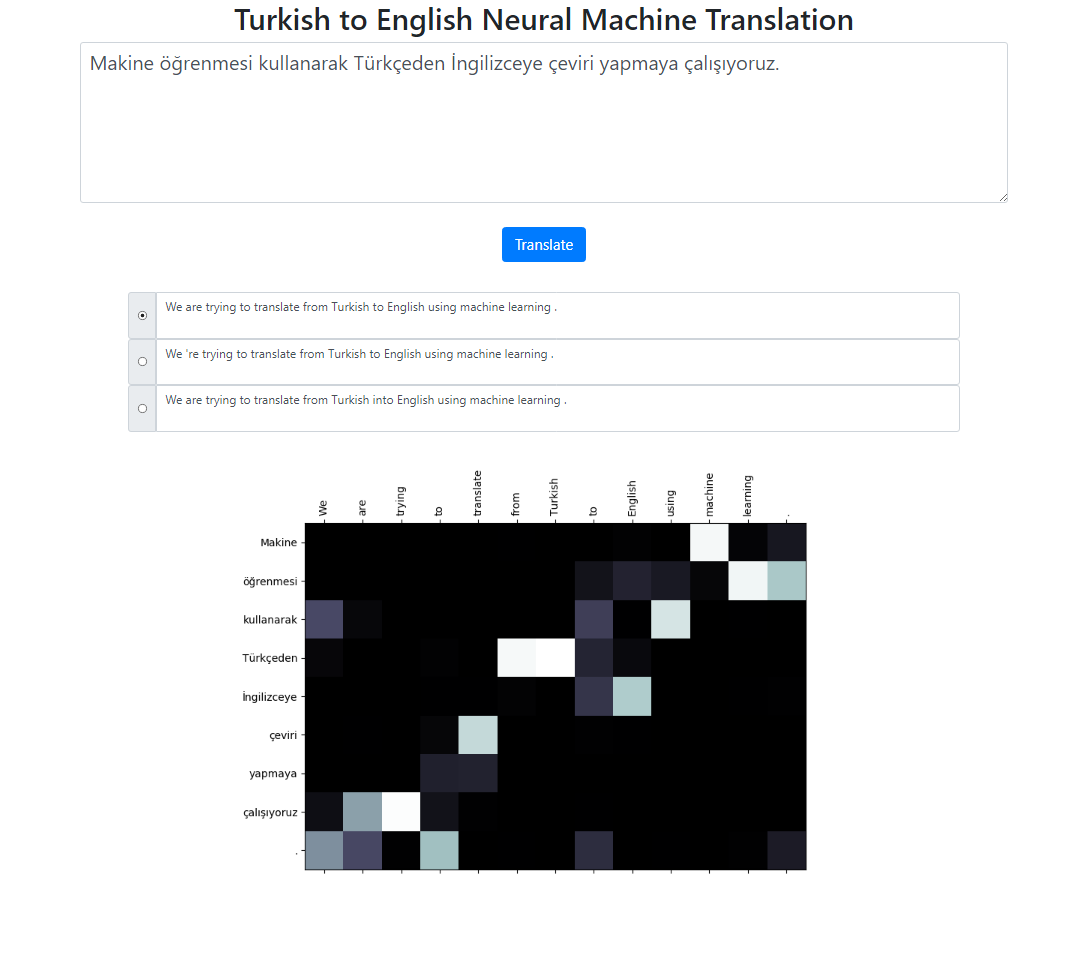
이 저장소는 Seq2Seq + Global Attention 모델을 사용하여 터키어에서 영어로의 신경 기계 번역 시스템을 구현합니다. 로컬로 실행할 수 있는 Flask 애플리케이션도 있습니다. 텍스트를 입력하고 번역하고 결과와 주의 시각화를 검사할 수 있습니다. 백그라운드에서 빔 크기 3을 사용하여 빔 검색을 실행하고 상대 점수를 기준으로 정렬된 가장 가능성 있는 시퀀스를 반환합니다.
이 프로젝트의 데이터세트는 여기에서 가져왔습니다. 저는 Tatoeba 코퍼스를 사용했습니다. 데이터에서 발견된 중복 항목 중 일부를 삭제했습니다. 또한 데이터 세트를 사전 토큰화했습니다. 최종 버전은 데이터 폴더에서 확인하실 수 있습니다.
터키어 문장을 토큰화하기 위해 nltk의 RegexpTokenizer를 사용했습니다.
puncts_just_apostrophe = '!"#$%&()*+,-./:;<=>?@[]^_`{|}~'TOKENIZE_PATTERN = fr"[{puncts_just_apostrophe}]|w+|['w ]+"regex_tokenizer = RegexpTokenizer(pattern=TOKENIZE_PATTERN)text = "타이타닉 15 Nisan pazartesi saat 02:20'de battı."tokenized_text = regex_tokenizer.tokenize(text)print(" ".join(tokenized_text))# 출력: Titanic 15 Nisan pazartesi saat 02 : 20 'de battı .# 이 분할 속성은 "02 : 20"은 영어 토크나이저와 다릅니다.# 그런 상황은 처리할 수 있습니다. 나는 그것을 간단하게 유지하고 # 해당 단어에 대한 관심 분포가 영어 토큰과 일치하는지 확인하고 싶었습니다.# 이 예와 마찬가지로 날짜에도 비슷한 경우가 대부분입니다: 02/09/2019영어 문장을 토큰화하기 위해 spacy의 영어 모델을 사용했습니다.
en_nlp = spacy.load('en_core_web_sm')text = "타이타닉호는 4월 15일 월요일 02:20에 침몰했습니다."tokenized_text = en_nlp.tokenizer(text)print(" ".join([tok.text for tok in tokenized_text ]))# 출력: 타이타닉호는 4월 15일 월요일 02:20에 침몰했습니다.터키어와 영어 문장은 두 개의 서로 다른 파일에 있어야 합니다.
file: train.tr tr_sent_1 tr_sent_2 tr_sent_3 ... file: train.en en_sent_1 en_sent_2 en_sent_3 ...
전체 인수 목록을 보려면 python train.py -h 실행하세요.
Sample usage: python train.py --train_data train.tr train.en --valid_data valid.tr valid.en --n_epochs 30 --batch_size 32 --embedding_dim 256 --hidden_size 256 --num_layers 2 --bidirectional --dropout_p 0.3 --device cuda
코퍼스 레벨 블루 점수를 계산합니다.
usage: test.py [-h] --model_file MODEL_FILE --valid_data VALID_DATA [VALID_DATA ...] Neural Machine Translation Testing optional arguments: -h, --help show this help message and exit --model_file MODEL_FILE Model File --valid_data VALID_DATA [VALID_DATA ...] Validation_data Sample Usage: python test.py --model_file model.bin --validation_data valid.tr valid.en
애플리케이션을 로컬로 실행하려면 다음을 실행하세요.
python app.py
config.py 파일의 모델 경로가 올바르게 정의되었는지 확인하세요.
모델 파일
어휘 파일
하위 단어 단위 사용(터키어 및 영어 모두)
다양한 주의 메커니즘(주의를 위한 다양한 매개변수 학습)
이 프로젝트의 뼈대 코드는 Stanford의 NLP 과정: CS224n에서 가져왔습니다.


