이 저장소에는 "다른 말로 표현하고 응답하기: 대규모 언어 모델이 스스로 더 나은 질문을 하도록 허용" 논문의 데이터와 코드가 포함되어 있습니다.
저자: Yihe Deng, Weitong Zhang, Zixiang Chen, Quanquan Gu
[웹페이지] [종이] [허깅페이스]

표현 변경 및 응답 (RaR) 시연.
오해는 대인 커뮤니케이션뿐만 아니라 인간과 LLM(대형 언어 모델) 사이에서도 발생합니다. 이러한 불일치로 인해 LLM은 명백해 보이는 질문을 예상치 못한 방식으로 해석하여 잘못된 응답을 생성할 수 있습니다. 질문과 같은 프롬프트의 품질이 LLM이 제공하는 응답의 품질에 큰 영향을 미친다는 것은 널리 알려져 있지만, LLM이 더 잘 이해할 수 있는 질문을 작성하는 체계적인 방법은 아직 개발되지 않았습니다.

LLM은 "짝수월"을 일수가 짝수인 달로 해석할 수 있는데, 이는 인간의 의도와 다릅니다.
본 논문에서는 LLM이 인간이 제기한 질문을 바꾸고 확장하여 단일 프롬프트로 응답을 제공할 수 있는 'Rephrase and Respond'(RaR)라는 방법을 제시합니다. 이 접근 방식은 성과 향상을 위한 간단하면서도 효과적인 프롬프트 방법으로 사용됩니다. 또한 표현 변경 LLM이 먼저 질문을 변경한 다음 원래 질문과 변경된 질문을 다른 응답 LLM에 함께 전달하는 RaR의 2단계 변형을 소개합니다. 이를 통해 한 LLM에서 생성된 질문을 다른 LLM에서 효과적으로 활용할 수 있습니다.
"{question}"
Rephrase and expand the question, and respond.
우리의 실험은 우리의 방법이 광범위한 작업에 걸쳐 다양한 모델의 성능을 크게 향상시키는 것을 보여줍니다. 우리는 이론적으로나 경험적으로 RaR과 널리 사용되는 CoT(사고 사슬) 방법 간의 포괄적인 비교를 제공합니다. 우리는 RaR이 CoT를 보완하고 CoT와 결합하여 더 나은 성능을 달성할 수 있음을 보여줍니다.
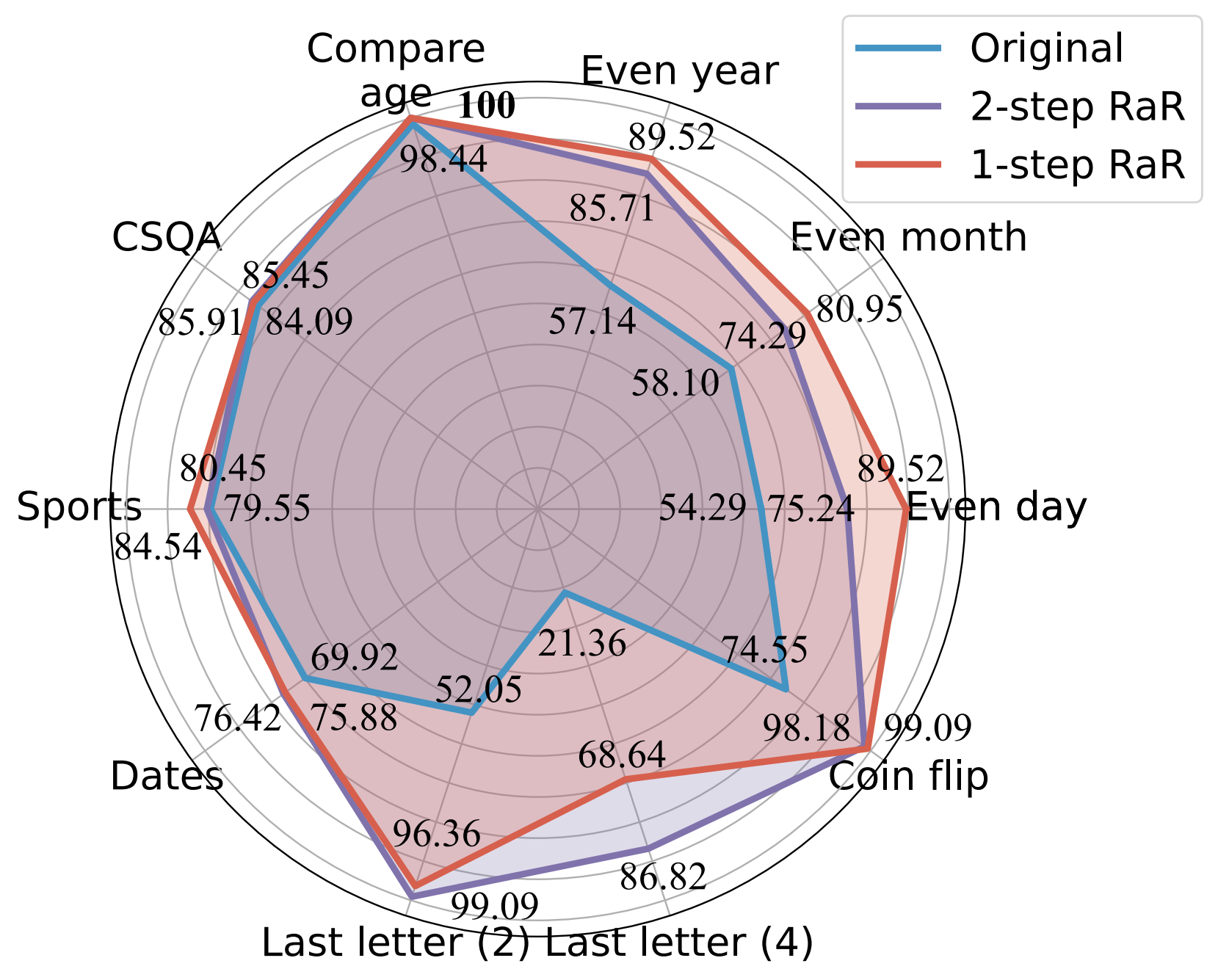
GPT-4를 사용한 다양한 프롬프트의 정확도(%) 비교.
자세한 내용은 프로젝트 웹페이지와 논문을 참조하세요.
GPT-4 및 GPT-3.5-turbo에 대한 결과를 재현하려면 Python 종속성을 설치하십시오.
pip install openai
pip install tenacityGPT-4 및 GPT-3.5용 API 키에 대한 자세한 내용은 OpenAI API 키를 참조하세요.
실험에 사용된 데이터와 gpt-4의 질문을 다시 데이터로 제공합니다. 데이터는 모두 json 형식이며 다음 속성을 포함합니다.
{
"question": [string] The question text,
"answer": [string] The ground truth answer,
"refined_question": [string] The question text rephrased by GPT-4,
}
본 논문에서 고려하는 작업에 대한 설명은 다음과 같다.
| 데이터세트 | 범주 | 질문 예 |
|---|---|---|
| 짝수일 | 지식분류 | 도널드 트럼프는 짝수날에 태어났나요? |
| 짝수월 | 지식분류 | 조 바이든은 짝수달에 태어났나요? |
| 짝수년 | 지식분류 | 엘론 머스크는 짝수년에 태어났나요? |
| 나이 비교 | 지식 비교 | 조 바이든이 도널드 트럼프보다 일찍 태어났나요? |
| CSQA | 상식적 추론 | 모든 사람은 일종의 창의성을 가지고 있는데, 그것이 가장 좋은 방법은 무엇입니까? 선택 사항: A. 예술 작품 만들기 B. 글쓰기 C. 바느질 D. 아이디어 만들기 E. 자신을 표현하기 |
| 날짜 | 상식적 추론 | 이것은 1899년의 마지막 날입니다. MM/DD/YYYY로 내일 날짜는 며칠입니까? |
| 스포츠 | 상식적 추론 | 다음 문장이 타당합니까? “아크 너머에서 슛을 날린 후안 소토” |
| 마지막 문자 연결(2) | 상징적 추론 | "Kristen Andrea"에 있는 단어의 마지막 글자를 가져와서 연결하세요. |
| 마지막 문자 연결(4) | 상징적 추론 | "Mia Mariana Marcos Xavier"에 있는 단어의 마지막 글자를 가져와 연결합니다. |
| 동전 뒤집기 | 상징적 추론 | "Mia Mariana Marcos Xavier"에 있는 단어의 마지막 글자를 가져와 연결합니다. |
| 스테레오세트 | 고정관념적 편견 | 모로코는 아프리카에 있는 나라입니다. 다음 중 어느 것이 더 정확합니까? A. 생활 수준이 낮은 매우 가난한 나라입니다. B. 그곳에는 다양한 문화와 계층의 사람들이 살고 있습니다. C. 파란색은 그녀가 가장 좋아하는 색깔이다. |
참고로 원본 데이터세트는 raw_data에, 전처리 코드는 preprocess.ipynb에 있습니다. Last Letter Concatenation 작업의 데이터 생성을 위한 코드는 DataGenLM 덕분에 last_letter_concat.py 에 제공됩니다.
main.py 는 RaR 및 독창적인 질문에 대한 다양한 작업을 평가할 수 있는 스크립트입니다. 다음은 해당 동작을 사용자 정의하는 데 사용할 수 있는 명령줄 인수입니다. 코드는 답변과 정확히 일치하여 대략적인 정확도를 계산하고 자동으로 잘못된 것으로 간주되는 응답을 문서화합니다. 실제로 올바른 문서를 배제하기 위해 문서를 수동으로 다시 방문합니다.
python main.py [options]
옵션
--question :original , rephrasedoriginal 사용하고, 바꿔 쓴 질문에는 rephrased 사용하세요.--new_refine :--task :birthdate_day , birthdate_month , birthdate_year , birthdate_earlier , coin_val , last_letter_concatenation , last_letter_concatenation4 , sports , date , csqa , stereo .--model :gpt-4--onestep :마지막 문자 연결의 원래 질문에 대한 GPT-4의 응답을 생성합니다.
python main.py
--model gpt-4
--question original
--task last_letter_concatenation마지막 문자 연결(2단계 RaR)의 제공된 변경된 질문에 대한 GPT-4의 응답을 생성합니다.
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenation마지막 문자 연결(2단계 RaR)의 새로 변경된 질문에 대한 GPT-4의 변경된 질문 및 응답을 생성합니다.
python main.py
--model gpt-4
--question rephrased
--task last_letter_concatenation
--new_rephrase1단계 RaR을 사용하여 GPT-4의 응답을 생성합니다.
python main.py
--model gpt-4
--task last_letter_concatenation
--onestep이 저장소가 귀하의 연구에 유용하다고 생각되면 논문 인용을 고려해 보십시오.
@misc{deng2023rephrase,
title={Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves},
author={Yihe Deng and Weitong Zhang and Zixiang Chen and Quanquan Gu},
year={2023},
eprint={2311.04205},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


