레이블 전파 방법을 사용하는 동의어 사전 확장용 도구입니다. 텍스트 코퍼스와 기존 동의어 사전에서 기존 동의어 세트를 확장하기 위한 제안을 생성합니다. 이 도구는 뮌헨 기술대학교(TUM)의 "비즈니스 정보 시스템을 위한 소프트웨어 엔지니어링(sebis)" 학과장의 석사 논문 " 세법 유의어 사전 확장을 위한 라벨 전파 " 중에 개발되었습니다.
논문 초록. 디지털화가 진행됨에 따라 정보 검색은 점점 증가하는 디지털 콘텐츠 양에 대처해야 합니다. 법률 콘텐츠 제공업체는 상당히 많은 수의 관련 문서를 검색하기 위해 동의어 사전과 같은 도메인별 온톨로지를 구축하는 데 많은 돈을 투자합니다. 2002년 이후 그래프에서 유사한 노드 그룹을 식별하기 위해 많은 레이블 전파 방법이 개발되었습니다. 레이블 전파는 그래프 기반 반지도 기계 학습 알고리즘 계열입니다. 본 논문에서는 세법 영역에서 동의어 사전을 확장하기 위한 라벨 전파 방법의 적합성을 테스트합니다. 레이블 전파가 작동하는 그래프는 단어 임베딩으로 구성된 유사성 그래프입니다. 우리는 프로세스를 처음부터 끝까지 다루며 특정 하이퍼 매개변수가 전체 성능에 미치는 영향을 이해하기 위해 여러 매개변수 연구를 수행합니다. 그런 다음 수동 연구를 통해 결과를 평가하고 기본 접근 방식과 비교합니다.
이 도구는 다음 파이프 및 필터 아키텍처를 사용하여 구현되었습니다.
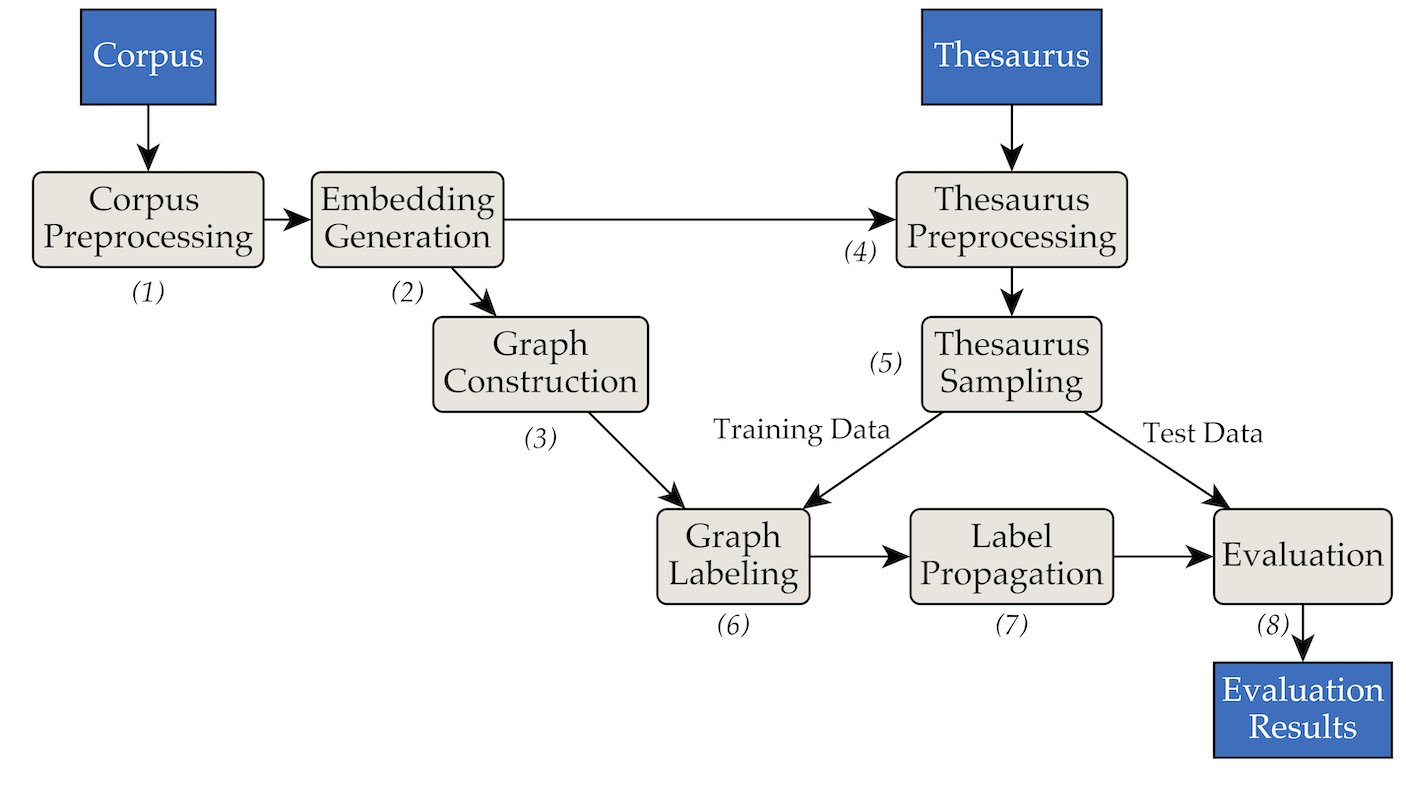
pipenv 설치합니다(설치 안내서).pipenv install 사용하여 프로젝트의 요구 사항을 설치합니다. data/RW40jsons 에 텍스트 말뭉치 파일 세트가 있고 data/german_relat_pretty-20180605.json 에 동의어 사전이 필요합니다. 예상되는 파일 형식에 대한 자세한 내용은 Phase1.py 및 Phase4.py를 참조하세요.output/<PHASE_FOLDER>/<DATE> 에 저장됩니다. 가장 중요한 것은 08_propagation_evaluation 및 XX_runs 입니다. 08_propagation_evaluation 에서 평가 통계는 예측, 학습 및 테스트 세트( df_evaluation 으로 가장 자주 참조되는 다른 스크립트에서는 main.txt )가 포함된 테이블과 함께 stats.json 으로 저장됩니다. XX_runs 에는 실행 로그가 저장됩니다. multi_runs.py(각각 다른 훈련/테스트 세트 포함)를 통해 여러 실행이 트리거된 경우 모든 개별 실행의 결합된 통계도 all_stats.json 으로 저장됩니다. purew2v_parameter_studies.py를 통해 논문에서 소개한 synset 벡터 기준선을 실행할 수 있습니다. 일련의 단어 임베딩과 하나 이상의 동의어 사전 훈련/테스트 분할이 필요합니다. 예제는 Sample_commands.md를 참조하세요.
ipynbs 에서는 (a) 통계, (b) 다이어그램 및 (c) 수동 평가를 위한 Excel 파일을 생성하는 데 사용된 몇 가지 예시적인 Jupyter 노트북을 제공했습니다. pipenv shell 실행한 다음 jupyter notebook 으로 Jupyter를 시작하여 탐색할 수 있습니다.
main.py 또는 multi_run.py 호출할 때 매개변수로 지정해야 합니다.

