대형언어모델코스
? X에서 나를 팔로우하세요 • ? 포옹하는 얼굴 • 블로그 • ? 실습 GNN
LLM 과정은 세 부분으로 구성됩니다.
- ? LLM 기초는 수학, Python 및 신경망에 대한 필수 지식을 다룹니다.
- ?? LLM 과학자는 최신 기술을 사용하여 최고의 LLM을 구축하는 데 중점을 둡니다.
- ? LLM 엔지니어는 LLM 기반 응용 프로그램을 만들고 배포하는 데 중점을 둡니다.
이 과정의 대화형 버전을 위해 저는 질문에 답하고 개인화된 방식으로 지식을 테스트할 두 명의 LLM 보조자를 만들었습니다.
- ? HuggingChat Assistant : Mixtral-8x7B를 사용하는 무료 버전입니다.
- ? ChatGPT Assistant : 프리미엄 계정이 필요합니다.
노트북
대규모 언어 모델과 관련된 노트북 및 기사 목록입니다.
도구
| 공책 | 설명 | 공책 |
|---|
| ? LLM 자동 평가 | RunPod를 사용하여 LLM을 자동으로 평가합니다. | |
| ? 게으른 병합 키트 | 한 번의 클릭으로 MergeKit을 사용하여 모델을 쉽게 병합할 수 있습니다. | |
| ? 게으른Axolotl | 한 번의 클릭으로 Axolotl을 사용하여 클라우드에서 모델을 미세 조정하세요. | |
| ⚡ 오토퀀트 | 한 번의 클릭으로 GGUF, GPTQ, EXL2, AWQ 및 HQQ 형식의 LLM을 양자화합니다. | |
| ? 모델 가계도 | 병합된 모델의 가계도를 시각화합니다. | |
| 제로스페이스 | 무료 ZeroGPU를 사용하여 Gradio 채팅 인터페이스를 자동으로 생성합니다. | |
미세 조정
| 공책 | 설명 | 기사 | 공책 |
|---|
| QLoRA로 Llama 2를 미세 조정하세요 | Google Colab에서 감독하에 Llama 2를 미세 조정하기 위한 단계별 가이드입니다. | 기사 | |
| Axolotl을 사용하여 CodeLlama 미세 조정 | 미세 조정을 위한 최첨단 도구에 대한 종합적인 가이드입니다. | 기사 | |
| QLoRA로 Mistral-7b 미세 조정 | TRL을 사용하는 무료 Google Colab에서 Mistral-7b의 미세 조정을 감독했습니다. | | |
| DPO로 Mistral-7b 미세 조정 | DPO를 통해 지도 미세 조정 모델의 성능을 향상하세요. | 기사 | |
| ORPO로 Llama 3를 미세 조정하세요 | ORPO를 사용하면 단일 단계에서 더 저렴하고 빠르게 미세 조정할 수 있습니다. | 기사 | |
| Unsloth를 사용하여 Llama 3.1을 미세 조정하세요. | Google Colab의 매우 효율적인 지도형 미세 조정. | 기사 | |
양자화
| 공책 | 설명 | 기사 | 공책 |
|---|
| 양자화 소개 | 8비트 양자화를 사용한 대규모 언어 모델 최적화. | 기사 | |
| GPTQ를 사용한 4비트 양자화 | 자신만의 오픈 소스 LLM을 양자화하여 소비자 하드웨어에서 실행하세요. | 기사 | |
| GGUF 및 llama.cpp를 사용한 양자화 | llama.cpp를 사용하여 Llama 2 모델을 양자화하고 GGUF 버전을 HF Hub에 업로드하세요. | 기사 | |
| ExLlamaV2: LLM을 실행하는 가장 빠른 라이브러리 | EXL2 모델을 양자화 및 실행하고 HF Hub에 업로드합니다. | 기사 | |
다른
| 공책 | 설명 | 기사 | 공책 |
|---|
| 대규모 언어 모델의 디코딩 전략 | 빔 검색부터 핵 샘플링까지 텍스트 생성 가이드 | 기사 | |
| 지식 그래프로 ChatGPT 개선 | 지식 그래프로 ChatGPT의 답변을 강화하세요. | 기사 | |
| MergeKit과 LLM 병합 | GPU가 필요 없이 자신만의 모델을 쉽게 만들어보세요! | 기사 | |
| MergeKit으로 MoE 만들기 | 여러 전문가를 하나의 FrankenMoE로 결합 | 기사 | |
| 삭제를 통해 모든 LLM을 검열 해제합니다. | 재교육 없이 미세 조정 | 기사 | |
? LLM 기초
이 섹션에서는 수학, Python 및 신경망에 대한 필수 지식을 소개합니다. 여기에서 시작하고 싶지 않을 수도 있지만 필요에 따라 참조하세요.
섹션 전환
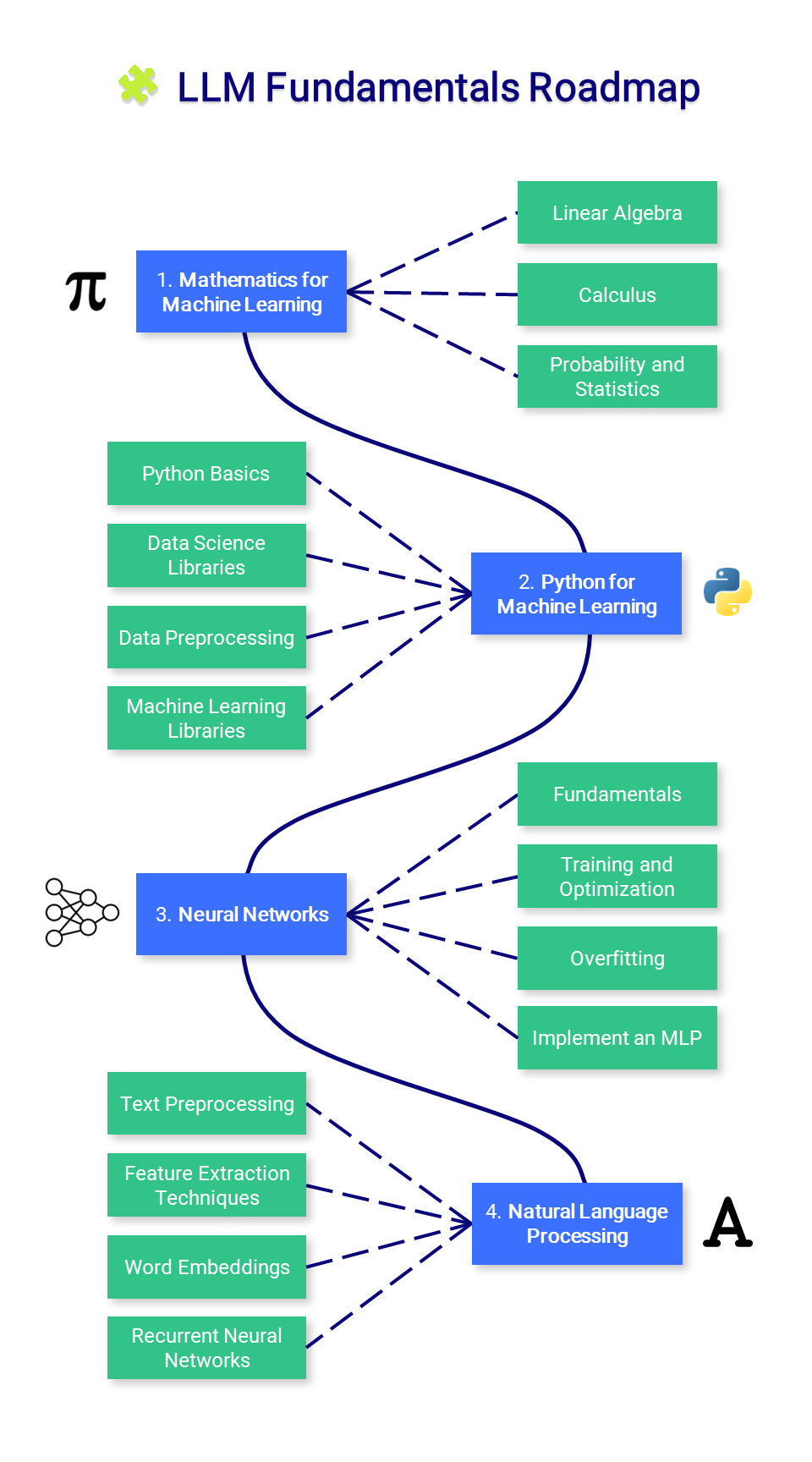
1. 머신러닝을 위한 수학
기계 학습을 마스터하기 전에 이러한 알고리즘을 구동하는 기본 수학적 개념을 이해하는 것이 중요합니다.
- 선형 대수학 : 이는 많은 알고리즘, 특히 딥러닝에 사용되는 알고리즘을 이해하는 데 중요합니다. 주요 개념에는 벡터, 행렬, 행렬식, 고유값 및 고유벡터, 벡터 공간 및 선형 변환이 포함됩니다.
- 미적분 : 많은 기계 학습 알고리즘에는 도함수, 적분, 극한 및 계열에 대한 이해가 필요한 연속 함수의 최적화가 포함됩니다. 다변수 미적분학 및 기울기 개념도 중요합니다.
- 확률 및 통계 : 모델이 데이터로부터 학습하고 예측하는 방법을 이해하는 데 중요합니다. 주요 개념에는 확률 이론, 확률 변수, 확률 분포, 기대치, 분산, 공분산, 상관 관계, 가설 검정, 신뢰 구간, 최대 우도 추정 및 베이지안 추론이 포함됩니다.
자원:
- 3Blue1Brown - 선형 대수의 본질: 이러한 개념에 기하학적 직관을 제공하는 비디오 시리즈입니다.
- Josh Starmer와 함께하는 StatQuest - 통계 기초: 다양한 통계 개념에 대해 간단하고 명확한 설명을 제공합니다.
- Ms Aerin의 AP 통계 직관: 모든 확률 분포에 대한 직관을 제공하는 매체 기사 목록입니다.
- 몰입형 선형 대수학: 선형 대수학의 또 다른 시각적 해석입니다.
- Khan Academy - 선형 대수학: 개념을 매우 직관적인 방식으로 설명하므로 초보자에게 적합합니다.
- 칸아카데미 - 미적분학: 미적분학의 모든 기초를 다루는 대화형 강좌입니다.
- 칸아카데미 - 확률과 통계: 이해하기 쉬운 형식으로 자료를 제공합니다.
2. 머신러닝을 위한 Python
Python은 가독성, 일관성 및 강력한 데이터 과학 라이브러리 생태계 덕분에 기계 학습에 특히 유용한 강력하고 유연한 프로그래밍 언어입니다.
- Python 기본 사항 : Python 프로그래밍을 위해서는 기본 구문, 데이터 유형, 오류 처리 및 객체 지향 프로그래밍에 대한 올바른 이해가 필요합니다.
- 데이터 과학 라이브러리 : 수치 연산을 위한 NumPy, 데이터 조작 및 분석을 위한 Pandas, 데이터 시각화를 위한 Matplotlib 및 Seaborn에 대한 지식이 포함되어 있습니다.
- 데이터 전처리 : 여기에는 기능 확장 및 정규화, 누락된 데이터 처리, 이상치 감지, 범주형 데이터 인코딩, 데이터를 훈련, 검증 및 테스트 세트로 분할하는 작업이 포함됩니다.
- 기계 학습 라이브러리 : 다양한 지도 및 비지도 학습 알고리즘을 제공하는 라이브러리인 Scikit-learn에 대한 숙련도가 중요합니다. 선형 회귀, 로지스틱 회귀, 의사결정 트리, 랜덤 포레스트, K-NN(k-최근접 이웃) 및 K-평균 클러스터링과 같은 알고리즘을 구현하는 방법을 이해하는 것이 중요합니다. PCA 및 t-SNE와 같은 차원 축소 기술도 고차원 데이터를 시각화하는 데 도움이 됩니다.
자원:
- 실제 Python: 초급 및 고급 Python 개념에 대한 기사와 튜토리얼이 포함된 포괄적인 리소스입니다.
- freeCodeCamp - Python 학습: Python의 모든 핵심 개념을 전체적으로 소개하는 긴 비디오입니다.
- Python 데이터 과학 핸드북: Pandas, NumPy, Matplotlib 및 Seaborn을 학습하는 데 유용한 리소스인 무료 디지털 책입니다.
- freeCodeCamp - 모두를 위한 기계 학습: 초보자를 위한 다양한 기계 학습 알고리즘에 대한 실용적인 소개입니다.
- Udacity - 기계 학습 소개: PCA 및 기타 여러 기계 학습 개념을 다루는 무료 과정입니다.
3. 신경망
신경망은 특히 딥 러닝 영역에서 많은 머신러닝 모델의 기본 부분입니다. 이를 효과적으로 활용하려면 설계와 메커니즘에 대한 포괄적인 이해가 필수적입니다.
- 기초 : 여기에는 레이어, 가중치, 편향 및 활성화 함수(Sigmoid, tanh, ReLU 등)와 같은 신경망의 구조에 대한 이해가 포함됩니다.
- 교육 및 최적화 : 역전파 및 평균 제곱 오차(MSE) 및 교차 엔트로피와 같은 다양한 유형의 손실 함수를 숙지하세요. Gradient Descent, Stochastic Gradient Descent, RMSprop 및 Adam과 같은 다양한 최적화 알고리즘을 이해합니다.
- 과적합 : 과적합(모델이 학습 데이터에서는 잘 수행되지만 보이지 않는 데이터에서는 성능이 좋지 않음)의 개념을 이해하고 이를 방지하기 위한 다양한 정규화 기술(드롭아웃, L1/L2 정규화, 조기 중지, 데이터 증대)을 학습합니다.
- MLP(다층 퍼셉트론) 구현 : PyTorch를 사용하여 완전히 연결된 네트워크라고도 알려진 MLP를 구축합니다.
자원:
- 3Blue1Brown - 신경망이란 무엇입니까?: 이 비디오는 신경망과 그 내부 작동 방식을 직관적으로 설명합니다.
- freeCodeCamp - 딥 러닝 집중 코스: 이 비디오는 딥 러닝의 가장 중요한 개념을 모두 효율적으로 소개합니다.
- Fast.ai - Practical Deep Learning: 딥러닝을 배우고 싶은 코딩 경험이 있는 사람들을 위해 고안된 무료 강좌입니다.
- Patrick Loeber - PyTorch 튜토리얼: 완전 초보자가 PyTorch에 대해 배울 수 있는 비디오 시리즈입니다.
4. 자연어 처리(NLP)
NLP는 인간의 언어와 기계의 이해 사이의 격차를 해소하는 매력적인 인공 지능 분야입니다. 간단한 텍스트 처리부터 언어적 뉘앙스 이해에 이르기까지 NLP는 번역, 감정 분석, 챗봇 등과 같은 많은 애플리케이션에서 중요한 역할을 합니다.
- 텍스트 전처리 : 토큰화(텍스트를 단어나 문장으로 분할), 형태소 분석(단어를 어근 형태로 축소), 표제어 추출(형태소 분석과 유사하지만 문맥 고려), 중지 단어 제거 등과 같은 다양한 텍스트 전처리 단계를 알아봅니다.
- 특징 추출 기술 : 텍스트 데이터를 기계 학습 알고리즘이 이해할 수 있는 형식으로 변환하는 기술에 익숙해집니다. 주요 방법으로는 BoW(Bag-of-Words), TF-IDF(Term Frequency-Inverse Document Frequency) 및 n-gram이 있습니다.
- 단어 임베딩(Word Embeddings ) : 단어 임베딩은 비슷한 의미를 가진 단어가 비슷한 표현을 가질 수 있도록 하는 단어 표현의 한 유형입니다. 주요 방법으로는 Word2Vec, GloVe 및 FastText가 있습니다.
- 순환 신경망(RNN) : 시퀀스 데이터를 사용하도록 설계된 신경망 유형인 RNN의 작동을 이해합니다. 장기적인 종속성을 학습할 수 있는 두 가지 RNN 변형인 LSTM과 GRU를 살펴보세요.
자원:
- RealPython - Python의 spaCy가 포함된 NLP: Python의 NLP 작업을 위한 spaCy 라이브러리에 대한 철저한 가이드입니다.
- Kaggle - NLP 가이드: Python의 NLP에 대한 실습 설명을 위한 몇 가지 노트북 및 리소스입니다.
- Jay Alammar - 일러스트레이션 Word2Vec: 유명한 Word2Vec 아키텍처를 이해하는 데 유용한 참고 자료입니다.
- Jake Tae - 처음부터 PyTorch RNN: PyTorch에서 RNN, LSTM 및 GRU 모델을 실용적이고 간단하게 구현합니다.
- colah의 블로그 - LSTM 네트워크 이해: LSTM 네트워크에 대한 보다 이론적인 기사입니다.
?? LLM 과학자
이 과정 섹션에서는 최신 기술을 사용하여 가능한 최고의 LLM을 구축하는 방법을 배우는 데 중점을 둡니다.
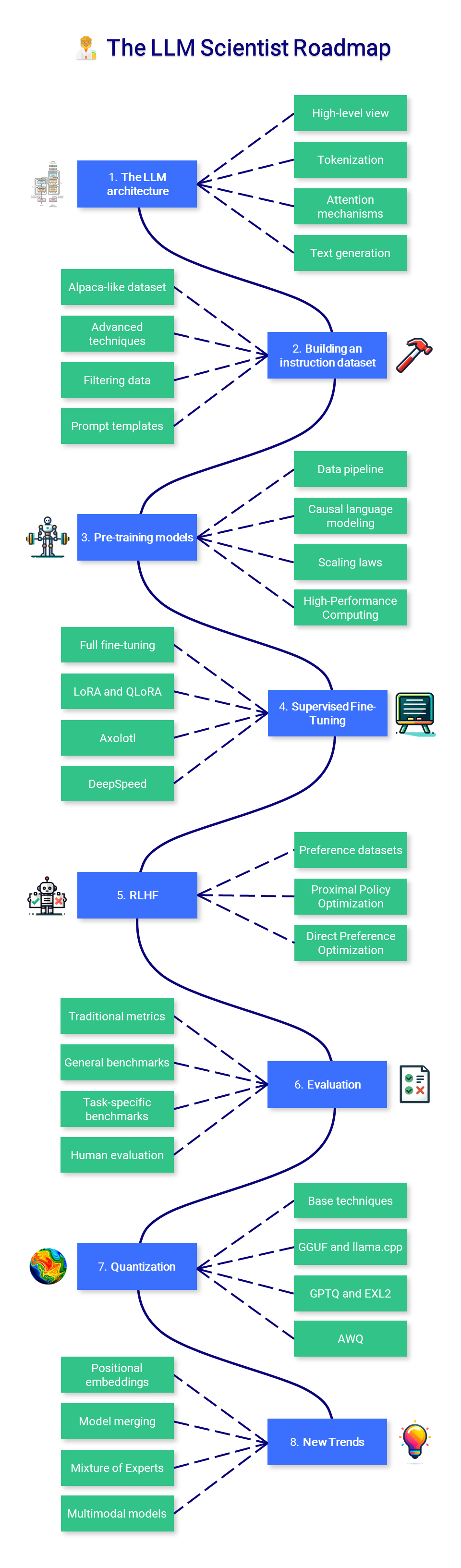
1. LLM 아키텍처
Transformer 아키텍처에 대한 심층적인 지식은 필요하지 않지만 입력(토큰)과 출력(로짓)을 잘 이해하는 것이 중요합니다. 바닐라 주의 메커니즘은 나중에 개선된 버전이 도입되므로 마스터해야 할 또 다른 중요한 구성 요소입니다.
- 높은 수준의 보기 : 인코더-디코더 Transformer 아키텍처, 특히 모든 최신 LLM에서 사용되는 디코더 전용 GPT 아키텍처를 다시 살펴보세요.
- 토큰화 : 원시 텍스트 데이터를 모델이 이해할 수 있는 형식으로 변환하는 방법을 이해합니다. 여기에는 텍스트를 토큰(일반적으로 단어 또는 하위 단어)으로 분할하는 작업이 포함됩니다.
- 어텐션 메커니즘 : 모델이 출력을 생성할 때 입력의 다양한 부분에 집중할 수 있도록 하는 self-attention 및 스케일링된 내적 주의를 포함한 어텐션 메커니즘 뒤에 있는 이론을 파악합니다.
- 텍스트 생성 : 모델이 출력 시퀀스를 생성할 수 있는 다양한 방법에 대해 알아봅니다. 일반적인 전략에는 그리디 디코딩, 빔 검색, top-k 샘플링, 핵 샘플링이 포함됩니다.
참고자료 :
- Jay Alammar의 Illustrated Transformer: Transformer 모델에 대한 시각적이고 직관적인 설명입니다.
- Jay Alammar의 그림 GPT-2: 이전 기사보다 훨씬 더 중요한 점은 Llama와 매우 유사한 GPT 아키텍처에 초점을 맞추고 있다는 점입니다.
- 3Blue1Brown의 Transformers 시각적 소개: Transformers에 대한 간단하고 이해하기 쉬운 시각적 소개
- Brendan Bycroft의 LLM 시각화: LLM 내부에서 일어나는 일에 대한 놀라운 3D 시각화입니다.
- Andrej Karpathy의 nanoGPT: GPT를 처음부터 다시 구현하는 2시간 길이의 YouTube 동영상(프로그래머용).
- 주목? 주목! 작성자: Lilian Weng: 보다 공식적인 방식으로 관심의 필요성을 소개합니다.
- LLM의 디코딩 전략: 텍스트를 생성하기 위한 다양한 디코딩 전략에 대한 코드와 시각적 소개를 제공합니다.
2. 명령어 데이터 세트 구축
Wikipedia 및 기타 웹사이트에서 원시 데이터를 찾는 것은 쉽지만, 실제로 지침과 답변 쌍을 수집하는 것은 어렵습니다. 기존 기계 학습과 마찬가지로 데이터 세트의 품질은 모델의 품질에 직접적인 영향을 미치므로 미세 조정 프로세스에서 가장 중요한 구성 요소일 수 있습니다.
- 알파카 유사 데이터 세트 : OpenAI API(GPT)를 사용하여 처음부터 합성 데이터를 생성합니다. 시드와 시스템 프롬프트를 지정하여 다양한 데이터세트를 생성할 수 있습니다.
- 고급 기술 : Evol-Instruct를 사용하여 기존 데이터 세트를 개선하는 방법, Orca 및 phi-1 논문과 같은 고품질 합성 데이터를 생성하는 방법을 알아보세요.
- 데이터 필터링 : 정규식과 관련된 전통적인 기술, 거의 중복된 항목 제거, 토큰 수가 많은 답변에 집중 등
- 프롬프트 템플릿 : 지침과 답변의 형식을 지정하는 진정한 표준 방법이 없으므로 ChatML, Alpaca 등과 같은 다양한 채팅 템플릿에 대해 아는 것이 중요합니다.
참고자료 :
- Thomas Capelle의 명령어 조정을 위한 데이터 세트 준비: Alpaca 및 Alpaca-GPT4 데이터 세트 탐색 및 형식 지정 방법.
- Solano Todeschini의 임상 지침 데이터 세트 생성: GPT-4를 사용하여 합성 지침 데이터 세트를 생성하는 방법에 대한 튜토리얼입니다.
- Kshitiz Sahay의 뉴스 분류를 위한 GPT 3.5: GPT 3.5를 사용하여 뉴스 분류를 위해 Llama 2를 미세 조정하는 지침 데이터 세트를 만듭니다.
- LLM 미세 조정을 위한 데이터 세트 생성: 데이터 세트를 필터링하고 결과를 업로드하는 몇 가지 기술이 포함된 노트북입니다.
- Matthew Carrigan의 채팅 템플릿: 프롬프트 템플릿에 대한 Hugging Face 페이지
3. 사전 훈련 모델
사전 훈련은 매우 길고 비용이 많이 드는 과정이므로 이것이 이 과정의 초점이 아닙니다. 사전 훈련 중에 어떤 일이 일어나는지 어느 정도 이해하고 있는 것이 좋지만 실습 경험이 필요하지는 않습니다.
- 데이터 파이프라인 : 사전 훈련에는 필터링, 토큰화 및 사전 정의된 어휘와 대조되어야 하는 대규모 데이터세트(예: Llama 2는 2조 토큰에 대해 훈련됨)가 필요합니다.
- 인과 언어 모델링 : 인과 언어 모델링과 마스크드 언어 모델링의 차이점과 이 경우에 사용된 손실 함수에 대해 알아봅니다. 효율적인 사전 훈련을 위해 Megatron-LM 또는 gpt-neox에 대해 자세히 알아보세요.
- 확장 법칙 : 확장 법칙은 모델 크기, 데이터 세트 크기 및 훈련에 사용되는 컴퓨팅 양을 기반으로 예상되는 모델 성능을 설명합니다.
- 고성능 컴퓨팅 : 여기서는 범위를 벗어나지만 처음부터 자체 LLM(하드웨어, 분산 워크로드 등)을 만들 계획이라면 HPC에 대한 더 많은 지식이 기본입니다.
참고자료 :
- Junhao Zhao의 LLMDataHub: 사전 훈련, 미세 조정 및 RLHF를 위한 선별된 데이터 세트 목록입니다.
- Hugging Face를 통해 인과 언어 모델을 처음부터 훈련: 변환기 라이브러리를 사용하여 처음부터 GPT-2 모델을 사전 훈련합니다.
- TinyLlama(Zhang et al.): Llama 모델이 처음부터 훈련되는 방법을 잘 이해하려면 이 프로젝트를 확인하세요.
- Hugging Face를 통한 인과 언어 모델링: 인과 언어 모델링과 마스크된 언어 모델링의 차이점을 설명하고 DistilGPT-2 모델을 신속하게 미세 조정하는 방법을 설명합니다.
- 향수를 불러일으키는 친칠라의 거친 의미: 확장 법칙에 대해 토론하고 일반적으로 LLM에 대한 의미를 설명합니다.
- BLOOM by BigScience: 엔지니어링 부분과 발생한 문제에 대한 많은 유용한 정보를 포함하여 BLOOM 모델이 어떻게 구축되었는지 설명하는 개념 페이지입니다.
- 메타별 OPT-175 로그북: 무엇이 잘못되었고 무엇이 올바르게 되었는지 보여주는 연구 로그입니다. 매우 큰 언어 모델(이 경우 175B 매개변수)을 사전 훈련하려는 경우 유용합니다.
- LLM 360: 교육 및 데이터 준비 코드, 데이터, 지표 및 모델을 갖춘 오픈 소스 LLM용 프레임워크입니다.
4. 감독된 미세 조정
사전 훈련된 모델은 다음 토큰 예측 작업에 대해서만 훈련되므로 도움이 되지 않습니다. SFT를 사용하면 지침에 응답하도록 조정할 수 있습니다. 또한 모든 데이터(비공개, GPT-4에서 볼 수 없는 데이터 등)에 대해 모델을 미세 조정하고 OpenAI와 같은 API 비용을 지불하지 않고도 사용할 수 있습니다.
- 전체 미세 조정(Full Fine- tuning) : 전체 미세 조정은 모델의 모든 매개변수를 학습하는 것을 의미합니다. 효율적인 기술은 아니지만 약간 더 나은 결과를 얻을 수 있습니다.
- LoRA : 낮은 순위 어댑터를 기반으로 하는 PEFT(매개변수 효율적 기술)입니다. 모든 매개변수를 훈련하는 대신 이러한 어댑터만 훈련합니다.
- QLoRA : LoRA를 기반으로 하는 또 다른 PEFT로, 모델의 가중치를 4비트로 양자화하고 페이징 최적화 프로그램을 도입하여 메모리 스파이크를 관리합니다. Unsloth와 결합하여 무료 Colab 노트북에서 효율적으로 실행하세요.
- Axolotl : 수많은 최첨단 오픈 소스 모델에 사용되는 사용자 친화적이고 강력한 미세 조정 도구입니다.
- DeepSpeed : 다중 GPU 및 다중 노드 설정을 위한 LLM의 효율적인 사전 훈련 및 미세 조정(Axolotl에서 구현됨)
참고자료 :
- Alpin의 초보자를 위한 LLM 교육 가이드: LLM을 미세 조정할 때 고려해야 할 주요 개념 및 매개변수에 대한 개요입니다.
- Sebastian Raschka의 LoRA 통찰력: LoRA에 대한 실용적인 통찰력과 최상의 매개변수를 선택하는 방법.
- 나만의 Llama 2 모델 미세 조정: Hugging Face 라이브러리를 사용하여 Llama 2 모델을 미세 조정하는 방법에 대한 실습 튜토리얼입니다.
- Benjamin Marie의 대규모 언어 모델 패딩: 인과적 LLM에 대한 교육 예제를 패딩하는 모범 사례
- LLM 미세 조정을 위한 초보자 가이드: Axolotl을 사용하여 CodeLlama 모델을 미세 조정하는 방법에 대한 자습서입니다.
5. 선호 정렬
감독된 미세 조정 후 RLHF는 LLM의 답변을 인간의 기대에 맞추는 데 사용되는 단계입니다. 아이디어는 편견을 줄이고 모델을 검열하거나 보다 유용한 방식으로 작동하도록 만드는 데 사용할 수 있는 인간(또는 인공) 피드백으로부터 선호도를 학습하는 것입니다. SFT보다 더 복잡하며 종종 선택 사항으로 간주됩니다.
- 선호 데이터세트 : 이러한 데이터세트에는 일반적으로 일종의 순위가 지정된 여러 답변이 포함되어 있어 지침 데이터세트보다 생성하기가 더 어렵습니다.
- 근접 정책 최적화 : 이 알고리즘은 주어진 텍스트가 인간에 의해 높은 순위로 평가되는지 예측하는 보상 모델을 활용합니다. 그런 다음 이 예측은 KL 발산을 기반으로 한 페널티를 사용하여 SFT 모델을 최적화하는 데 사용됩니다.
- 직접 선호 최적화 : DPO는 이를 분류 문제로 재구성하여 프로세스를 단순화합니다. 보상 모델(교육 필요 없음) 대신 참조 모델을 사용하고 하나의 하이퍼파라미터만 필요하므로 더욱 안정적이고 효율적입니다.
참고자료 :
- Argilla의 Distilabel: 자신만의 데이터 세트를 생성하는 데 탁월한 도구입니다. 이는 선호도 데이터 세트를 위해 특별히 설계되었지만 SFT도 수행할 수 있습니다.
- Ayush Thakur의 RLHF를 사용한 LLM 교육 소개: LLM에서 편견을 줄이고 성과를 높이는 데 RLHF가 바람직한 이유를 설명합니다.
- Hugging Face의 일러스트레이션 RLHF: 보상 모델 훈련 및 강화 학습을 통한 미세 조정을 통한 RLHF 소개.
- 포옹 얼굴을 통한 선호도 조정 LLM: 선호도 정렬을 수행하기 위한 DPO, IPO 및 KTO 알고리즘 비교.
- LLM 교육: Sebastian Rashcka의 RLHF 및 대안: RLHF 프로세스 개요 및 RLAIF와 같은 대안.
- DPO를 사용하여 Mistral-7b 미세 조정: DPO를 사용하여 Mistral-7b 모델을 미세 조정하고 NeuralHermes-2.5를 재현하는 튜토리얼입니다.
6. 평가
LLM을 평가하는 것은 시간이 많이 걸리고 어느 정도 신뢰성이 있는 파이프라인에서 과소평가된 부분입니다. 다운스트림 작업은 무엇을 평가할지 결정해야 하지만 항상 Goodhart의 법칙을 기억하세요. "측정값이 목표가 되면 더 이상 좋은 측정값이 아닙니다."
- 기존 측정항목 : Perplexity 및 BLEU 점수와 같은 측정항목은 대부분의 상황에서 결함이 있기 때문에 예전만큼 인기가 없습니다. 그것들을 이해하고 언제 적용할 수 있는지를 이해하는 것은 여전히 중요합니다.
- 일반 벤치마크 : 언어 모델 평가 하네스를 기반으로 하는 Open LLM 리더보드는 ChatGPT와 같은 범용 LLM의 주요 벤치마크입니다. BigBench, MT-Bench 등과 같은 다른 인기 있는 벤치마크도 있습니다.
- 작업별 벤치마크 : 요약, 번역, 질문 답변과 같은 작업에는 전용 벤치마크, 지표는 물론 생물의학 질문 답변을 위한 PubMedQA와 같은 하위 도메인(의료, 금융 등)도 있습니다.
- 사람의 평가 : 가장 신뢰할 수 있는 평가는 사용자의 수용률이나 사람의 비교입니다. 채팅 추적(예: LangSmith 사용)과 함께 사용자 피드백을 기록하면 잠재적인 개선 영역을 식별하는 데 도움이 됩니다.
참고자료 :
- Hugging Face에 의한 고정 길이 모델의 Perplexity: 변환기 라이브러리로 구현하기 위한 코드의 Perplexity 개요입니다.
- Rachael Tatman의 BLEU 위험 부담: BLEU 점수 개요 및 예시와 관련된 다양한 문제.
- Chang 외의 LLM 평가에 관한 설문조사: 무엇을 평가할지, 어디에서 평가할지, 어떻게 평가할지에 대한 종합적인 논문입니다.
- lmsys의 Chatbot Arena Leaderboard: 사람이 비교한 내용을 바탕으로 한 범용 LLM의 Elo 등급입니다.
7. 양자화
양자화는 낮은 정밀도를 사용하여 모델의 가중치(및 활성화)를 변환하는 프로세스입니다. 예를 들어, 16비트를 사용하여 저장된 가중치는 4비트 표현으로 변환될 수 있습니다. 이 기술은 LLM과 관련된 계산 및 메모리 비용을 줄이기 위해 점점 더 중요해지고 있습니다.
- 기본 기술 : 다양한 수준의 정밀도(FP32, FP16, INT8 등)와 absmax 및 영점 기술을 사용하여 순진한 양자화를 수행하는 방법을 알아보세요.
- GGUF 및 llama.cpp : 원래 CPU에서 실행되도록 설계된 llama.cpp 및 GGUF 형식은 소비자급 하드웨어에서 LLM을 실행하는 데 가장 널리 사용되는 도구가 되었습니다.
- GPTQ 및 EXL2 : GPTQ, 특히 EXL2 형식은 놀라운 속도를 제공하지만 GPU에서만 실행될 수 있습니다. 모델을 양자화하는 데도 오랜 시간이 걸립니다.
- AWQ : 이 새로운 형식은 GPTQ(낮은 복잡도)보다 정확하지만 더 많은 VRAM을 사용하므로 반드시 더 빠르지는 않습니다.
참고자료 :
- 양자화 소개: 양자화 개요, absmax 및 영점 양자화, 코드가 포함된 LLM.int8().
- llama.cpp를 사용하여 Llama 모델 양자화: llama.cpp 및 GGUF 형식을 사용하여 Llama 2 모델을 양자화하는 방법에 대한 자습서입니다.
- GPTQ를 사용한 4비트 LLM 양자화: AutoGPTQ와 함께 GPTQ 알고리즘을 사용하여 LLM을 양자화하는 방법에 대한 자습서입니다.
- ExLlamaV2: LLM을 실행하는 가장 빠른 라이브러리: EXL2 형식을 사용하여 Mistral 모델을 양자화하고 ExLlamaV2 라이브러리로 실행하는 방법에 대한 가이드입니다.
- FriendliAI의 활성화 인식 가중치 양자화 이해: AWQ 기술 및 그 이점 개요.
8. 새로운 트렌드
- 위치 임베딩 : LLM이 위치, 특히 RoPE와 같은 상대 위치 인코딩 체계를 인코딩하는 방법을 알아보세요. YaRN(주의 매트릭스에 온도 요인을 곱함) 또는 ALiBi(토큰 거리에 따른 주의 페널티)를 구현하여 컨텍스트 길이를 연장합니다.
- 모델 병합 : 훈련된 모델을 병합하는 것은 미세 조정 없이 성능이 뛰어난 모델을 만드는 인기 있는 방법이 되었습니다. 널리 사용되는 mergekit 라이브러리는 SLERP, DARE 및 TIES와 같은 가장 널리 사용되는 병합 방법을 구현합니다.
- 전문가의 혼합 : Mixtral은 뛰어난 성능 덕분에 MoE 아키텍처를 다시 대중화했습니다. 동시에, 더 저렴하고 성능이 뛰어난 옵션인 Phixtral과 같은 모델을 병합하여 OSS 커뮤니티에서 일종의 FrankenMoE가 등장했습니다.
- 다중 모달 모델 : 이러한 모델(예: CLIP, Stable Diffusion 또는 LLaVA)은 통합 임베딩 공간을 사용하여 여러 유형의 입력(텍스트, 이미지, 오디오 등)을 처리하여 텍스트-이미지와 같은 강력한 애플리케이션을 잠금 해제합니다.
참고자료 :
- EleutherAI의 RoPE 확장: 다양한 위치 인코딩 기술을 요약한 기사입니다.
- Rajat Chawla의 YaRN 이해: YaRN 소개.
- mergekit을 사용하여 LLM 병합: mergekit을 사용한 모델 병합에 대한 자습서입니다.
- Hugging Face를 통해 설명되는 전문가의 혼합: MoE 및 작동 방식에 대한 철저한 가이드입니다.
- Chip Huyen의 대형 다중 모드 모델: 다중 모드 시스템 개요 및 이 분야의 최근 역사.
? LLM 엔지니어
과정의 이 섹션에서는 모델을 강화하고 배포하는 데 중점을 두고 프로덕션에서 사용할 수 있는 LLM 기반 애플리케이션을 구축하는 방법을 배우는 데 중점을 둡니다.
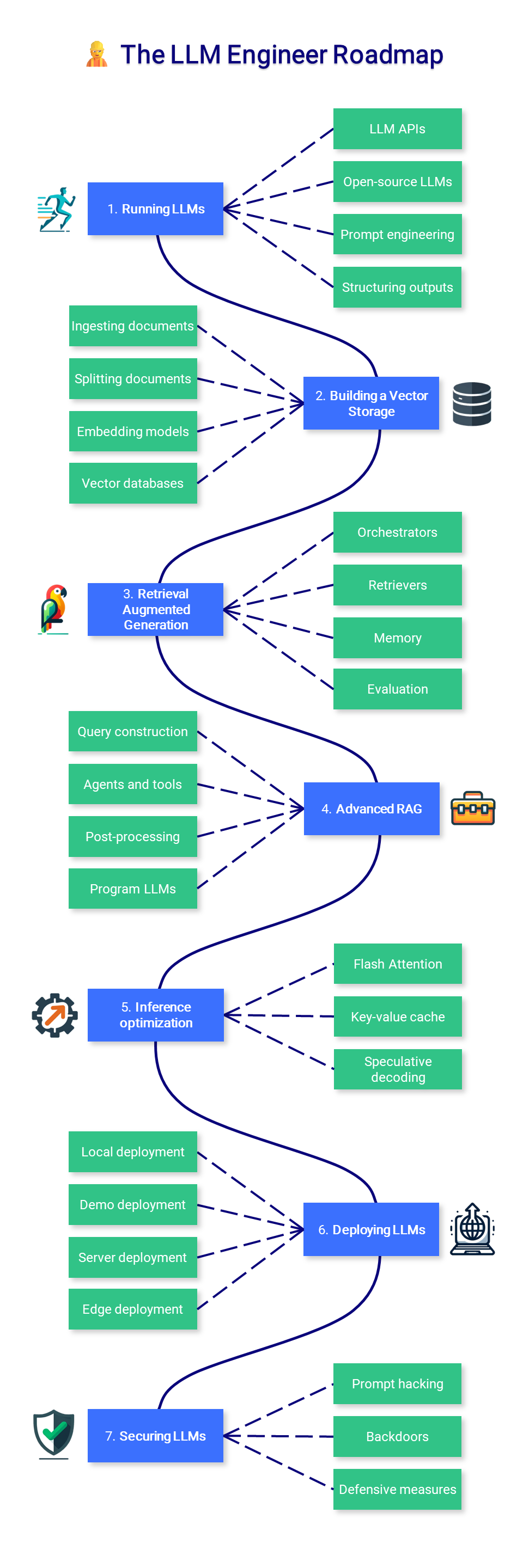
1. LLM 실행
높은 하드웨어 요구 사항으로 인해 LLM을 실행하는 것이 어려울 수 있습니다. 사용 사례에 따라 단순히 API(예: GPT-4)를 통해 모델을 사용하거나 로컬에서 실행할 수도 있습니다. 어떤 경우든 추가 프롬프트 및 안내 기술을 사용하면 애플리케이션의 출력을 개선하고 제한할 수 있습니다.
- LLM API : API는 LLM을 배포하는 편리한 방법입니다. 이 공간은 프라이빗 LLM(OpenAI, Google, Anthropic, Cohere 등)과 오픈 소스 LLM(OpenRouter, Hugging Face, Together AI 등)으로 구분됩니다.
- 오픈 소스 LLM : Hugging Face Hub는 LLM을 찾기에 좋은 장소입니다. Hugging Face Spaces에서 일부를 직접 실행하거나 LM Studio와 같은 앱에서 로컬로 다운로드하여 실행하거나 llama.cpp 또는 Ollama를 사용하는 CLI를 통해 실행할 수 있습니다.
- 프롬프트 엔지니어링 : 일반적인 기술에는 제로샷 프롬프트, 퓨샷 프롬프트, 사고 체인 및 ReAct가 포함됩니다. 더 큰 모델에서 더 잘 작동하지만 더 작은 모델에도 적용할 수 있습니다.
- 출력 구조화 : 많은 작업에는 엄격한 템플릿이나 JSON 형식과 같은 구조화된 출력이 필요합니다. LMQL, 개요, 지침 등과 같은 라이브러리를 사용하여 생성을 안내하고 주어진 구조를 존중할 수 있습니다.
참고자료 :
- Nisha Arya의 LM Studio를 사용하여 로컬에서 LLM 실행: LM Studio 사용 방법에 대한 간략한 가이드입니다.
- DAIR.AI의 프롬프트 엔지니어링 가이드: 예제가 포함된 프롬프트 기술의 전체 목록
- 아웃라인 - 빠른 시작: 아웃라인을 통해 지원되는 생성 기술 안내 목록입니다.
- LMQL - 개요: LMQL 언어 소개.
2. 벡터 저장소 구축
벡터 스토리지 생성은 RAG(Retrieval Augmented Generation) 파이프라인을 구축하기 위한 첫 번째 단계입니다. 문서가 로드되고 분할되며 관련 청크가 추론 중에 향후 사용을 위해 저장되는 벡터 표현(임베딩)을 생성하는 데 사용됩니다.
- 문서 수집 : 문서 로더는 PDF, JSON, HTML, Markdown 등 다양한 형식을 처리할 수 있는 편리한 래퍼입니다. 또한 일부 데이터베이스 및 API(GitHub, Reddit, Google Drive 등)에서 데이터를 직접 검색할 수도 있습니다.
- 문서 분할 : 텍스트 분할기는 문서를 더 작고 의미상 의미 있는 덩어리로 나눕니다. n 문자 이후에 텍스트를 분할하는 대신 일부 추가 메타데이터를 사용하여 헤더로 분할하거나 재귀적으로 분할하는 것이 더 나은 경우가 많습니다.
- 임베딩 모델 : 임베딩 모델은 텍스트를 벡터 표현으로 변환합니다. 이는 의미론적 검색을 수행하는 데 필수적인 언어에 대한 더 깊고 미묘한 이해를 가능하게 합니다.
- 벡터 데이터베이스 : 벡터 데이터베이스(Chroma, Pinecone, Milvus, FAISS, Annoy 등)는 임베딩 벡터를 저장하도록 설계되었습니다. 벡터 유사성을 기반으로 한 쿼리와 '가장 유사한' 데이터를 효율적으로 검색할 수 있습니다.
참고자료 :
- LangChain - 텍스트 분할기: LangChain에 구현된 다양한 텍스트 분할기 목록입니다.
- Sentence Transformers 라이브러리: 임베딩 모델에 널리 사용되는 라이브러리입니다.
- MTEB 리더보드: 모델 삽입을 위한 리더보드입니다.
- Moez Ali의 상위 5개 벡터 데이터베이스: 최고의 벡터 데이터베이스와 가장 인기 있는 벡터 데이터베이스를 비교합니다.
3. 검색 증강 생성
RAG를 통해 LLM은 데이터베이스에서 상황별 문서를 검색하여 답변의 정확성을 향상시킵니다. RAG는 미세 조정 없이 모델의 지식을 확대하는 널리 사용되는 방법입니다.
- 오케스트레이터 : 오케스트레이터(예: LangChain, LlamaIndex, FastRAG 등)는 LLM을 도구, 데이터베이스, 메모리 등과 연결하고 기능을 강화하는 데 널리 사용되는 프레임워크입니다.
- 검색기 : 사용자 지침은 검색에 최적화되어 있지 않습니다. 다양한 기술(예: 다중 쿼리 검색기, HyDE 등)을 적용하여 구문을 변경/확장하고 성능을 향상시킬 수 있습니다.
- 메모리 : 이전 지침과 답변을 기억하기 위해 ChatGPT와 같은 LLM 및 챗봇은 이 기록을 컨텍스트 창에 추가합니다. 이 버퍼는 요약(예: 더 작은 LLM 사용), 벡터 저장소 + RAG 등을 통해 개선될 수 있습니다.
- 평가 : 문서 검색(컨텍스트 정확성 및 회상)과 생성 단계(신뢰성 및 답변 관련성)를 모두 평가해야 합니다. Ragas 및 DeepEval 도구를 사용하여 단순화할 수 있습니다.
참고자료 :
- Llamaindex - 상위 수준 개념: RAG 파이프라인을 구축할 때 알아야 할 주요 개념입니다.
- 솔방울 - 검색 확대: 검색 확대 프로세스의 개요입니다.
- LangChain - RAG와의 Q&A: 일반적인 RAG 파이프라인을 구축하기 위한 단계별 튜토리얼입니다.
- LangChain - 메모리 유형: 관련 용도가 있는 다양한 유형의 메모리 목록입니다.
- RAG 파이프라인 - 지표: RAG 파이프라인을 평가하는 데 사용되는 주요 지표의 개요입니다.
4. 고급 RAG
실제 애플리케이션에는 SQL 또는 그래프 데이터베이스를 포함한 복잡한 파이프라인은 물론 관련 도구 및 API 자동 선택이 필요할 수 있습니다. 이러한 고급 기술은 기본 솔루션을 개선하고 추가 기능을 제공할 수 있습니다.
- 쿼리 구성 : 기존 데이터베이스에 저장된 구조화된 데이터에는 SQL, Cypher, 메타데이터 등과 같은 특정 쿼리 언어가 필요합니다. 쿼리 구성을 통해 사용자 명령을 쿼리로 직접 변환하여 데이터에 액세스할 수 있습니다.
- 에이전트 및 도구 : 에이전트는 답변을 제공하기 위해 가장 관련성이 높은 도구를 자동으로 선택하여 LLM을 강화합니다. 이러한 도구는 Google 또는 Wikipedia를 사용하는 것처럼 간단할 수도 있고 Python 인터프리터 또는 Jira와 같이 더 복잡할 수도 있습니다.
- 사후 처리 : LLM에 공급되는 입력을 처리하는 마지막 단계입니다. Re-Ranking, RAG-fusion, Classification을 통해 검색된 문서의 관련성과 다양성을 향상시킵니다.
- 프로그램 LLM : DSPy와 같은 프레임워크를 사용하면 프로그래밍 방식으로 자동화된 평가를 기반으로 프롬프트와 가중치를 최적화할 수 있습니다.
참고자료 :
- LangChain - 쿼리 구성: 다양한 유형의 쿼리 구성에 대한 블로그 게시물입니다.
- LangChain - SQL: Text-to-SQL 및 선택적 SQL 에이전트와 관련된 LLM을 사용하여 SQL 데이터베이스와 상호 작용하는 방법에 대한 자습서입니다.
- Pinecone - LLM 에이전트: 다양한 유형의 에이전트 및 도구 소개.
- Lilian Weng의 LLM Powered Autonomous Agents: LLM 에이전트에 대한 더 많은 이론적 기사.
- LangChain - OpenAI의 RAG: 후처리를 포함하여 OpenAI에서 사용하는 RAG 전략 개요입니다.
- 8단계 DSPy: 모듈, 서명 및 최적화 프로그램을 소개하는 DSPy에 대한 범용 가이드입니다.
5. 추론 최적화
텍스트 생성은 고가의 하드웨어가 필요한 비용이 많이 드는 프로세스입니다. 양자화 외에도 처리량을 최대화하고 추론 비용을 줄이기 위한 다양한 기술이 제안되었습니다.
- Flash Attention : 복잡성을 2차에서 선형으로 변환하여 훈련과 추론 속도를 높이는 주의 메커니즘 최적화입니다.
- 키-값 캐시 : 키-값 캐시와 MQA(Multi-Query Attention) 및 GQA(Grouped-Query Attention)에 도입된 개선 사항을 이해합니다.
- 추측적 디코딩 : 작은 모델을 사용하여 초안을 생성한 다음 더 큰 모델에서 검토하여 텍스트 생성 속도를 높입니다.
참고자료 :
- 포옹 얼굴을 통한 GPU 추론: GPU에서 추론을 최적화하는 방법을 설명합니다.
- Databricks의 LLM 추론: 프로덕션에서 LLM 추론을 최적화하는 방법에 대한 모범 사례입니다.
- 포옹 얼굴을 통한 속도 및 메모리용 LLM 최적화: 속도와 메모리를 최적화하는 세 가지 주요 기술, 즉 양자화, Flash Attention 및 아키텍처 혁신을 설명합니다.
- Assisted Generation by Hugging Face: HF의 추론적 디코딩 버전으로 이를 구현하기 위해 코드와 어떻게 작동하는지에 대한 흥미로운 블로그 게시물입니다.
6. LLM 배포
대규모로 LLM을 배포하는 것은 여러 개의 GPU 클러스터가 필요할 수 있는 엔지니어링 위업입니다. 다른 시나리오에서는 훨씬 낮은 복잡성으로 데모 및 로컬 앱을 달성할 수 있습니다.
- 로컬 배포 : 개인 정보 보호는 오픈 소스 LLM이 개인 LLM에 비해 갖는 중요한 이점입니다. 로컬 LLM 서버(LM Studio, Ollama, oobabooga, kobold.cpp 등)는 이러한 이점을 활용하여 로컬 앱을 강화합니다.
- 데모 배포 : Gradio 및 Streamlit과 같은 프레임워크는 애플리케이션 프로토타입을 작성하고 데모를 공유하는 데 유용합니다. 예를 들어 포옹 페이스 공간을 사용하는 등 온라인으로 쉽게 호스팅 할 수 있습니다.
- 서버 배포 : 스케일에서 LLM을 배포하여 클라우드 (SkyPilot 참조) 또는 온 프렘 인프라가 필요하며 종종 TGI, VLLM 등과 같은 최적화 된 텍스트 생성 프레임 워크를 활용합니다.
- 에지 배포 : 제한된 환경에서 MLC LLM 및 MNN-LLM과 같은 고성능 프레임 워크는 웹 브라우저, Android 및 iOS에 LLM을 배포 할 수 있습니다.
참고자료 :
- sleamlit- 기본 LLM 앱 빌드 : 튜토리얼을 사용하여 기본 chatgpt와 같은 앱을 만들기위한 튜토리얼.
- HF LLM 추론 컨테이너 : Hugging Face의 추론 컨테이너를 사용하여 Amazon Sagemaker에 LLM을 배치하십시오.
- Philipp Schmid의 Philschmid 블로그 : Amazon Sagemaker를 사용한 LLM 배포에 관한 고품질 기사 모음.
- Hamel Husain에 의한 LATENCE 최적화 : 처리량 및 대기 시간 측면에서 TGI, VLLM, CTRANSLATE2 및 MLC의 비교.
7. LLMS 확보
소프트웨어와 관련된 전통적인 보안 문제 외에도 LLM은 훈련 및 프롬프트 방식으로 인해 고유 한 약점이 있습니다.
- 프롬프트 해킹 : 신속한 엔지니어링과 관련된 다양한 기술 (프롬프트 주입) (모델의 답변을 가로 채기위한 추가 명령), 데이터/프롬프트 누출 (원래 데이터/프롬프트 검색) 및 탈옥 (안전 기능을 우회하기위한 공예 프롬프트).
- 백도어 : 공격 벡터는 훈련 데이터를 중독 시키거나 (예 : 허위 정보) 백도어를 생성함으로써 훈련 데이터 자체를 타겟팅 할 수 있습니다 (추론 중에 모델의 동작을 변경하기위한 비밀 트리거).
- 방어 조치 : LLM 애플리케이션을 보호하는 가장 좋은 방법은 이러한 취약점 (예 : 빨간색 팀링 및 Garak과 같은 점검)에 대해 테스트하고 (Langfuse와 같은 프레임 워크)를 관찰하는 것입니다.
참고자료 :
- Hego Wiki의 Owasp LLM Top 10 : LLM 응용 프로그램에서 볼 수있는 10 가지 비평가 취약점 목록.
- Joseph Thacker의 프롬프트 주입 프라이머 : 엔지니어를위한 프롬프트 주입 전용 짧은 가이드.
- @LLM_SEC의 LLM 보안 : LLM 보안과 관련된 광범위한 리소스 목록.
- Microsoft의 Red Teaming LLMS : LLM으로 빨간 팀을 수행하는 방법에 대한 안내.
감사의 말
이 로드맵은 Milan Milanović와 Romano Roth의 훌륭한 Devops 로드맵에서 영감을 얻었습니다.
특별히 감사드립니다:
- 로드맵을 만들도록 동기를 부여한 Thomas Thelen
- 그의 입력 및 첫 번째 초안 검토에 대한 André Frade
- LLM 보안에 대한 리소스를 제공하는 Dino Dunn
- "인간 평가"부분을 개선 한 Magdalena Kuhn
- 변압기에 대한 3Blue1Brown의 비디오를 제안하기위한 OdoverDose
면책 조항 : 나는 여기에 나열된 출처와 제휴하지 않습니다.


