Yang Zou, 정종헌, Latha Pemula, Dongqing Zhang, Onkar Dabeer.
이 리포지토리에는 ECCV-2022 논문 "이상 탐지 및 세분화를 위한 SPot-the-Difference 자가 지도 사전 훈련"에 대한 리소스가 포함되어 있습니다. 현재 우리는 VisA(Visual Anomaly) 데이터세트를 출시하고 있습니다.
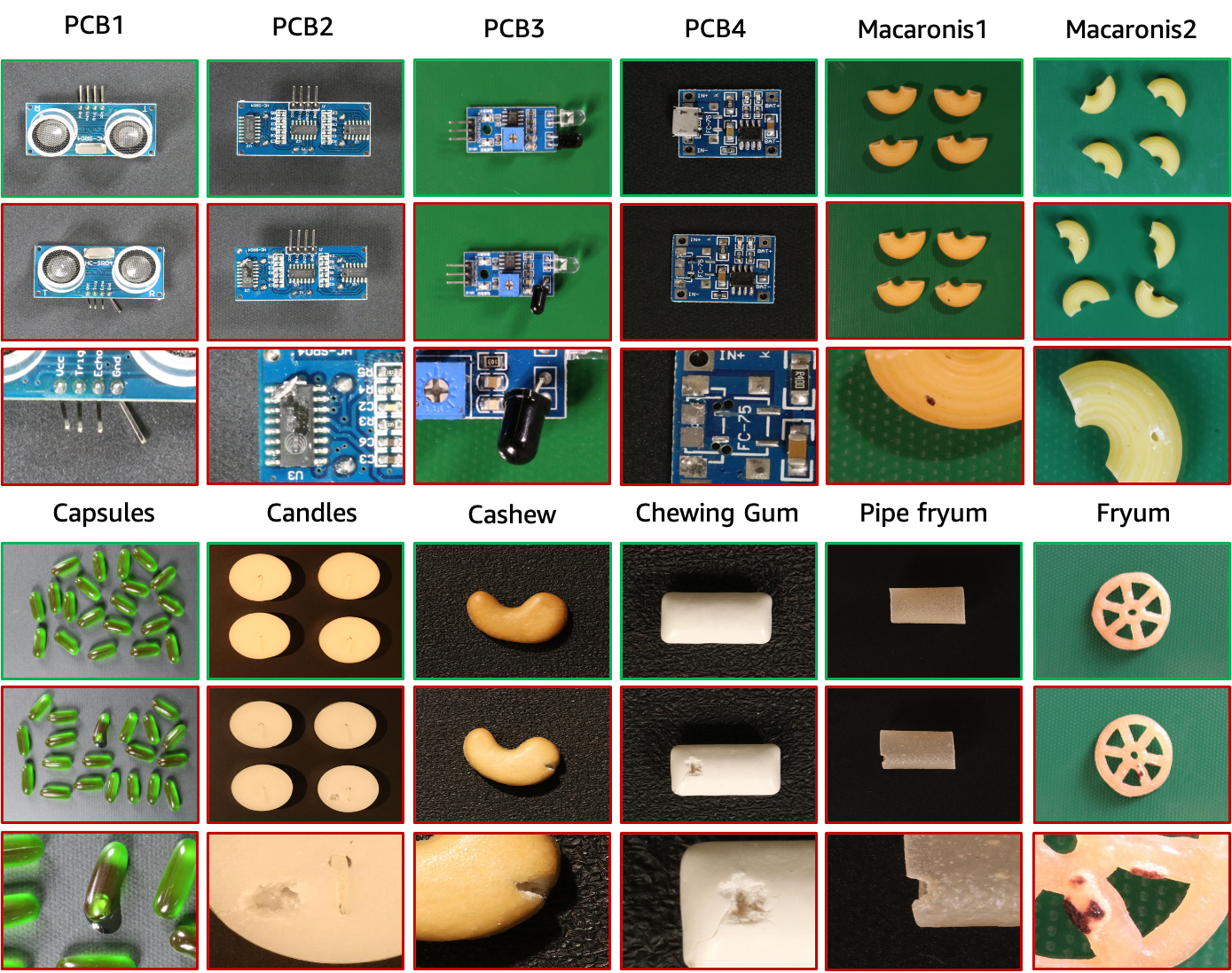
VisA 데이터 세트에는 위 그림과 같이 12개의 서로 다른 개체에 해당하는 12개의 하위 집합이 포함되어 있습니다. 9,621개의 정상 샘플과 1,200개의 비정상 샘플이 포함된 10,821개의 이미지가 있습니다. 4개의 하위 집합은 트랜지스터, 커패시터, 칩 등을 포함하는 상대적으로 복잡한 구조를 가진 다양한 유형의 인쇄 회로 기판(PCB)입니다. 뷰에 여러 인스턴스가 있는 경우 캡슐, 양초, Macaroni1 및 Macaroni2의 4개 하위 집합을 수집합니다. Capsules와 Macaroni2의 인스턴스는 위치와 포즈가 크게 다릅니다. 또한 개체가 대략적으로 정렬된 캐슈, 츄잉껌, Fryum 및 파이프 프라이움을 포함한 4개의 하위 집합을 수집합니다. 변칙영상에는 긁힘, 찌그러짐, 색반점, 균열 등의 표면 결함과 잘못된 위치, 부품 누락 등의 구조적 결함 등 다양한 결함이 포함되어 있습니다.
| 물체 | # 일반 샘플 | # 이상 샘플 | # 이상 클래스 | 객체 유형 |
|---|---|---|---|---|
| PCB1 | 1,004 | 100 | 4 | 복잡한 구조 |
| PCB2 | 1,001 | 100 | 4 | 복잡한 구조 |
| PCB3 | 1,006 | 100 | 4 | 복잡한 구조 |
| PCB4 | 1,005 | 100 | 7 | 복잡한 구조 |
| 캡슐 | 602 | 100 | 5 | 다중 인스턴스 |
| 양초 | 1,000 | 100 | 8 | 다중 인스턴스 |
| 마카로니스1 | 1,000 | 100 | 7 | 다중 인스턴스 |
| 마카로니스2 | 1,000 | 100 | 7 | 다중 인스턴스 |
| 캐슈 | 500 | 100 | 9 | 단일 인스턴스 |
| 껌 | 503 | 100 | 6 | 단일 인스턴스 |
| 프리움 | 500 | 100 | 8 | 단일 인스턴스 |
| 파이프 프라이엄 | 500 | 100 | 9 | 단일 인스턴스 |
우리는 AWS S3에서 VisA 데이터 세트를 호스팅하고 있으며 이 URL을 통해 다운로드할 수 있습니다.
다운로드한 데이터의 데이터 트리는 다음과 같습니다.
VisA
| -- candle
| ----- | --- Data
| ----- | ----- | ----- Images
| ----- | ----- | -------- | ------ Anomaly
| ----- | ----- | -------- | ------ Normal
| ----- | ----- | ----- Masks
| ----- | ----- | -------- | ------ Anomaly
| ----- | --- image_anno.csv
| -- capsules
| ----- | ----- ...image_annot.csv는 각 이미지에 대해 이미지 수준 레이블과 픽셀 수준 주석 마스크를 제공합니다. 다중 클래스 마스크에 대한 id2class 맵 함수는 ./utils/id2class.py에서 찾을 수 있습니다. 여기서 일반 이미지에 대한 마스크는 공간을 절약하기 위해 저장되지 않습니다.
원본 논문에 설명된 1-class, 2-class-highshot, 2-class-fewshot 설정을 준비하기 위해 ./utils/prepare_data.py를 사용하여 "./split_csv/"의 데이터 분할 파일에 따라 데이터를 재구성합니다. . 1-클래스 설정 준비를 위한 샘플 명령줄은 다음과 같습니다.
python ./utils/prepare_data.py --split-type 1cls --data-folder ./VisA --save-folder ./VisA_pytorch --split-file ./split_csv/1cls.csv
개편된 1등급 설정의 데이터 트리는 다음과 같습니다.
VisA_pytorch
| -- 1cls
| ----- | --- candle
| ----- | ----- | ----- ground_truth
| ----- | ----- | ----- test
| ----- | ----- | ------- | ------- good
| ----- | ----- | ------- | ------- bad
| ----- | ----- | ----- train
| ----- | ----- | ------- | ------- good
| ----- | --- capsules
| ----- | --- ...구체적으로 1클래스 설정을 위해 재구성된 데이터는 MVTec-AD의 데이터 트리를 따릅니다. 각 개체에 대한 데이터에는 세 개의 폴더가 있습니다.
원본 데이터세트의 다중 클래스 실측 분할 마스크는 이진 마스크로 다시 인덱싱됩니다. 여기서 0은 정상을 나타내고 255는 이상을 나타냅니다.
또한 prepare_data.py의 인수를 변경하여 비슷한 방법으로 2클래스 설정을 준비할 수 있습니다.
분류 및 세분화 지표를 계산하려면 ./utils/metrics.py를 참조하세요. 현지화 측정항목을 계산할 때 일반 샘플을 고려합니다. 이는 현지화에서 일반적인 샘플을 무시한 일부 다른 작업과 다릅니다.
이 데이터세트가 프로젝트에 도움이 된다면 다음 논문을 인용해 주세요.
@article { zou2022spot ,
title = { SPot-the-Difference Self-Supervised Pre-training for Anomaly Detection and Segmentation } ,
author = { Zou, Yang and Jeong, Jongheon and Pemula, Latha and Zhang, Dongqing and Dabeer, Onkar } ,
journal = { arXiv preprint arXiv:2207.14315 } ,
year = { 2022 }
}데이터는 CC BY 4.0 라이센스에 따라 공개됩니다.


