이 저장소에는 LLM의 기본 설정에서 파생된 보상 기능을 사용하여 NetHack에서 AI 에이전트를 교육하는 Motif용 PyTorch 코드가 포함되어 있습니다.
모티브: 인공지능 피드백을 통한 내적 동기 부여
작성자: Martin Klissarov* 및 Pierluca D'Oro*, Shagun Sodhani, Roberta Raileanu, Pierre-Luc Bacon, Pascal Vincent, Amy Zhang 및 Mikael Henaff
Motif는 NetHack에서 수집된 상호 작용 데이터 세트의 캡션 관찰 쌍에 대해 LLM(대형 언어 모델)의 선호도를 이끌어냅니다. 자동으로 LLM의 상식을 강화 학습을 통해 에이전트를 훈련하는 데 사용되는 보상 기능으로 추출합니다.
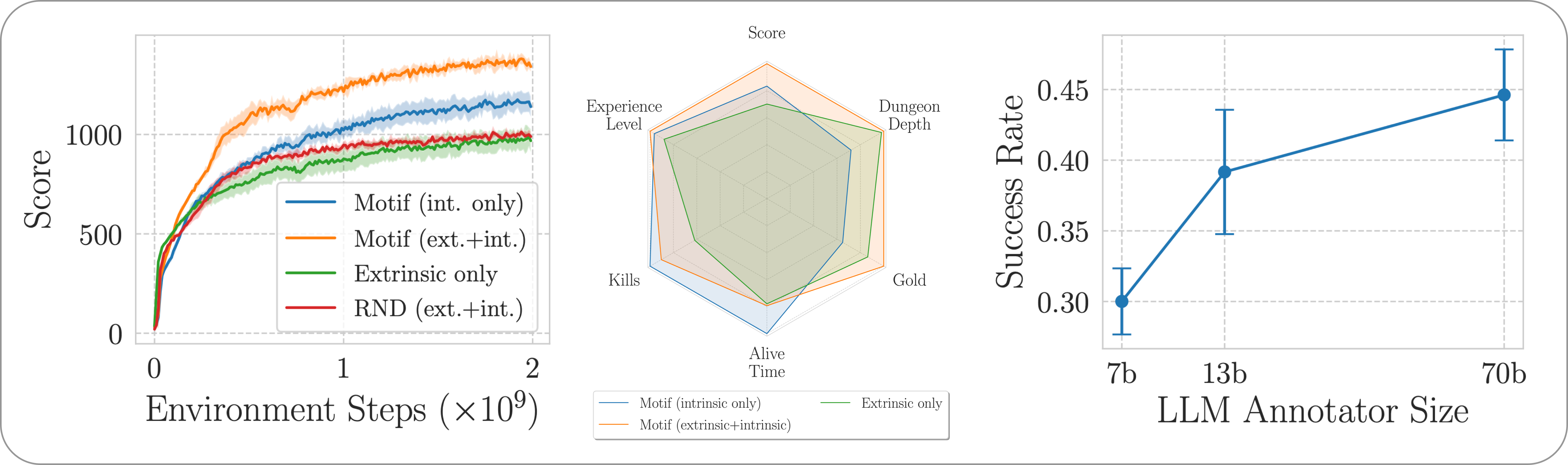
비교를 용이하게 하기 위해 작업이 포함된 사전을 키로 포함하는 피클 파일 motif_results.pkl 에 훈련 곡선을 제공합니다. 각 작업에 대해 여러 시드에 대해 Motif 및 기준선에 대한 시간 단계 및 평균 수익 목록을 제공합니다.
다음 그림에서 볼 수 있듯이 Motif는 세 가지 단계로 구성됩니다.
논문에서 실험을 재현하는 데 필요한 데이터 세트, 명령 및 원시 결과를 제공하여 각 단계를 자세히 설명합니다.
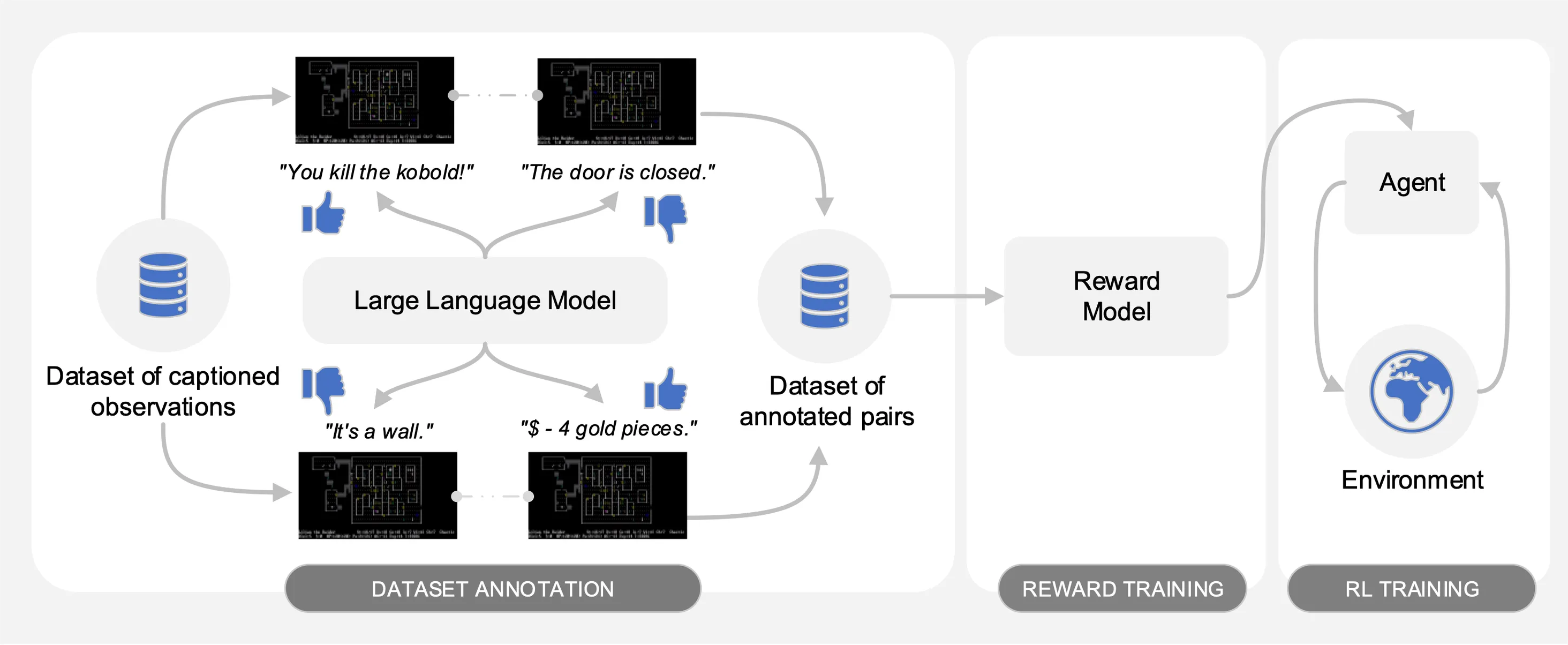
우리는 NetHack 학습 환경을 통해 도전적이고 개방적이며 절차적으로 생성된 NetHack 게임에서 Motif의 성능을 평가합니다. 우리는 Motif가 어떻게 즉각적인 수정과 확장 속성을 통해 쉽게 조종할 수 있는 직관적인 인간 중심 행동을 생성하는지 조사합니다.

전체 파이프라인에 필요한 종속성을 설치하려면 pip install -r requirements.txt 실행하면 됩니다.
첫 번째 단계에서는 게임 점수를 최대화하기 위해 강화 학습으로 훈련된 에이전트가 수집한 캡션(예: 게임의 메시지)이 포함된 관찰 쌍의 데이터 세트를 사용합니다. 우리는 이 저장소에 데이터세트를 제공합니다. 우리는 다음 명령을 사용하여 압축을 풀 수 있는 motif_dataset_zipped 디렉터리에 다양한 부분을 저장합니다.
cat motif_dataset_zipped/motif_dataset_part_* > motif_dataset.zip; unzip motif_dataset.zip; rm motif_dataset.zip
우리가 제공하는 데이터 세트는 논문에 설명된 다양한 프롬프트를 사용하여 preference/ 디렉토리에 포함된 Llama 2 모델이 제공한 기본 설정 세트를 제공합니다. 주석이 포함된 .npy 파일의 이름은 llama{size}b_msg_{instruction}_{version} 템플릿을 따릅니다. 여기서 size {7,13,70} 세트의 LLM 크기이고, instruction 은 {defaultgoal, zeroknowledge, combat, gold, stairs} 세트에서 LLM에 제공되는 프롬프트, version {default, reworded} 세트에서 사용할 프롬프트 템플릿의 버전입니다. 다음은 사용 가능한 주석에 대한 요약을 제공합니다.
| 주석 | 논문의 사용 사례 |
|---|---|
llama70b_msg_defaultgoal_default | 주요 실험 |
llama70b_msg_combat_default | Monster Slayer 행동을 향한 방향 |
llama70b_msg_gold_default | 금 수집가 행동을 향한 방향 |
llama70b_msg_stairs_default | 디센더 행동을 향한 방향 |
llama7b_msg_defaultgoal_default | 확장 실험 |
llama13b_msg_defaultgoal_default | 확장 실험 |
llama70b_msg_zeroknowledge_default | 영지식 프롬프트 실험 |
llama70b_msg_defaultgoal_reworded | 신속한 단어 바꾸기 실험 |
주석을 생성하기 위해 우리는 vLLM과 Llama 2의 채팅 버전을 사용합니다. Llama 2로 자신만의 주석을 생성하거나 주석 프로세스를 재현하려면 공식 지침에 따라 모델을 다운로드할 수 있는지 확인하십시오. 모델 가중치에 액세스하는 데 며칠이 걸립니다.)
주석 스크립트는 n-annotation-chunks 인수를 사용하여 데이터 세트가 다른 청크로 주석을 달 것이라고 가정합니다. 이를 통해 리소스 가용성에 따라 병렬화할 수 있고 재시작/선점에 강력한 프로세스가 가능합니다. 단일 청크로 실행하고(즉, 전체 데이터세트를 처리하기 위해) 기본 프롬프트 템플릿과 작업 사양으로 주석을 추가하려면 다음 명령을 실행합니다.
python -m scripts.annotate_pairs_dataset --directory motif_dataset
--prompt-version default --goal-key defaultgoal
--n-annotation-chunks 1 --chunk-number 0
--llm-size 70 --num-gpus 8
--ignore-existing 플래그로 달리 지정하지 않는 한 기본 동작은 구성을 지정하는 파일에 주석을 추가하여 주석 프로세스를 재개합니다. 주석을 위해 생성된 '.npy' 파일의 이름은 --custom-annotator-string 플래그를 사용하여 수동으로 선택할 수도 있습니다. 32GB 메모리를 갖춘 단일 GPU를 사용하여 --llm-size 7 및 --llm-size 13 사용하여 주석을 달 수 있습니다. 8-GPU 노드에서 --llm-size 70 사용하여 주석을 달 수 있습니다. 여기서는 100,000개 쌍의 데이터 세트에 대해 NVIDIA V100s 32G GPU를 사용한 대략적인 주석 시간 추정치를 제공합니다. 이는 대부분의 결과(500,000개 쌍으로 얻은)를 대략적으로 재현할 수 있어야 합니다.
| 모델 | 주석을 달 수 있는 리소스 |
|---|---|
| 라마 2 7b | ~32 GPU 시간 |
| 라마 2 13b | ~40 GPU 시간 |
| 라마 2 70b | ~72 GPU 시간 |
두 번째 단계에서는 교차 엔트로피를 통해 LLM의 선호도를 보상 함수로 추출합니다. 기본 하이퍼파라미터를 사용하여 보상 훈련을 시작하려면 다음 명령을 사용하십시오.
python -m scripts.train_reward --batch_size 1024 --num_workers 40
--reward_lr 1e-5 --num_epochs 10 --seed 777
--dataset_dir motif_dataset --annotator llama70b_msg_defaultgoal_default
--experiment standard_reward --train_dir train_dir/reward_saving_dir
보상 함수는 --dataset_dir 에 있는 annotator 주석을 통해 학습됩니다. 결과 함수는 하위 폴더 --experiment 아래의 train_dir 에 저장됩니다.
마지막으로 강화 학습을 통해 결과적인 보상 기능으로 에이전트를 교육합니다. 내재적 보상과 외재적 보상을 결합하는 실험에 사용되는 기본 하이퍼파라미터를 사용하여 NetHackScore-v1 작업에 대해 에이전트를 교육하려면 다음 명령을 사용할 수 있습니다.
python -m scripts.main --algo APPO --env nle_fixed_eat_action --num_workers 24
--num_envs_per_worker 20 --batch_size 4096 --reward_scale 0.1 --obs_scale 255.0
--train_for_env_steps 2_000_000_000 --save_every_steps 10_000_000
--keep_checkpoints 5 --stats_avg 1000 --seed 777 --reward_dir train_dir/reward_saving_dir/standard_reward/
--experiment standard_motif --train_dir train_dir/rl_saving_dir
--extrinsic_reward 0.1 --llm_reward 0.1 --reward_encoder nle_torchbeast_encoder
--root_env NetHackScore-v1 --beta_count_exponent 3 --eps_threshold_quantile 0.5
작업을 변경하려면 --root_env 인수를 수정하면 됩니다. 다음 표에는 논문에 제시된 실험과 일치시키는 데 필요한 값이 명시적으로 나와 있습니다. NetHackScore-v1 작업은 에이전트가 목표에 도달하도록 장려하기 위해 extrinsic_reward 값이 0.1 인 반면 다른 모든 작업은 10.0 값을 사용하여 학습됩니다.
| 환경 | root_env |
|---|---|
| 점수 | NetHackScore-v1 |
| 계단 | NetHackStaircase-v1 |
| 계단(3층) | NetHackStaircaseLvl3-v1 |
| 계단(4층) | NetHackStaircaseLvl4-v1 |
| 신탁 | NetHackOracle-v1 |
| 신탁이 냉정한 | NetHackOracleSober-v1 |
또한 LLM에서 제공되는 내재적 보상만 사용하고 환경에서 제공되는 보상은 사용하지 않고 에이전트를 교육하려면 --extrinsic_reward 0.0 설정하면 됩니다. 본질적인 보상 전용 실험에서는 에이전트가 목표에 도달했을 때가 아니라 에이전트가 죽을 경우에만 에피소드를 종료합니다. 이러한 수정된 환경은 다음 표에 나열되어 있습니다.
| 환경 | root_env |
|---|---|
| 계단(레벨 3) - 내장 전용 | NetHackStaircaseLvl3Continual-v1 |
| 계단(레벨 4) - 내장 전용 | NetHackStaircaseLvl4Continual-v1 |
훈련된 RL 에이전트를 시각화하기 위한 스크립트도 추가로 제공합니다. 이는 행동에 대한 중요한 통찰력을 제공할 수 있을 뿐만 아니라 각 에피소드에 대한 주요 메시지를 생성하여 최적화하려는 대상을 이해하는 데 도움이 될 수 있습니다. 다음 명령을 실행하기만 하면 됩니다.
python -m scripts.visualize --train_dir train_dir/rl_saving_dir --experiment standard_motif
우리 작업을 기반으로 하거나 유용하다고 생각되면 다음 bibtex를 사용하여 인용해 주세요.
@article{klissarovdoro2023motif,
title={Motif: Intrinsic Motivation From Artificial Intelligence Feedback},
author={Klissarov, Martin and D’Oro, Pierluca and Sodhani, Shagun and Raileanu, Roberta and Bacon, Pierre-Luc and Vincent, Pascal and Zhang, Amy and Henaff, Mikael},
year={2023},
month={9},
journal={arXiv preprint arXiv:2310.00166}
}
Motif의 대부분은 CC-BY-NC에 따라 라이센스가 부여되지만 프로젝트의 일부는 별도의 라이센스 조건에 따라 사용 가능합니다. 샘플 팩토리는 MIT 라이센스에 따라 라이센스가 부여됩니다.


