나는 문서와 README를 위한 사본을 작성하는 동안과 변수 및 함수 이름 지정을 위한 코드를 작성하는 동안 정기적으로 동의어 사전을 사용합니다.
나는 온라인 동의어 사전, 특히 thesaurus.com을 사용하곤 했지만 그 경험이 싫었습니다. 결과는 유용하고 매우 잘 구성되어 있지만 키보드 친화적이지 않고 탐색 속도가 느립니다. 특히 결과가 여러 페이지로 확장되는 경우 더욱 그렇습니다.
그래서 나는 나만의 동의어 사전을 만들었습니다. 나는 thesaurus.com을 사용한 것보다 훨씬 더 자주 이 사이트를 사용합니다. 기능은 적지만 액세스가 훨씬 빠르고 창작 과정에 지장을 주지 않습니다.
터미널 창에서 th 다음에 단어를 입력합니다. 예를 들어 attention 이라는 단어를 조회하려면 다음을 수행합니다.
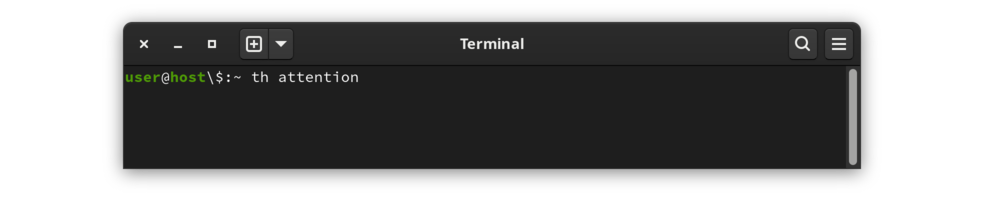 |
|---|
주의를 끌기 th 호출 |
출력은 열로 구성된 관련 단어 및 구문 목록으로, 위와 아래에 컨텍스트 줄이 있고 하단에 탐색 옵션 목록이 있습니다.
 |
|---|
| 주목 할만한 검색결과 |
결과 표시의 맨 아래 줄에는 사용 가능한 작업 목록이 표시됩니다. 작업의 첫 글자를 입력하여 작업을 시작합니다(강조를 위해 화면에 강조 표시됨).
데이터는 동의어 사전 항목으로 구성되며 각 항목에는 관련 단어 및 구문 모음이 포함되어 있습니다. 항목은 트렁크 이고 관련 단어와 문구는 분기 입니다.
기본 보기는 분기 모드입니다. 표시되는 단어는 소스 동의어 사전의 항목 뒤에 나열된 단어와 구문입니다. 트렁크 모드로 전환하면 해당 단어가 포함된 항목이 표시됩니다. 이는 분기가 없는 예에서 가장 명확하게 설명됩니다.
 |
|---|
| Trigger는 항목이 없는 단어입니다. |
Trigger 라는 단어에 대한 동의어 사전 항목이 없습니다. 그러나 트리거라는 단어는 동의어 사전에서 다른 항목의 분기로 사용됩니다. 트리거를 포함하는 항목을 보려면 트렁크 모드로 전환하십시오.
 |
|---|
| 트리거가 관련 단어인 단어 목록 |
이 프로그램은 패키지로 제공되지 않습니다. 소스 코드를 다운로드하고 프로젝트를 빌드해야 합니다. 다음 단계에 따라 작동하는 동의어 사전이 생성됩니다.
git clone https://www.github.com/cjungmann/th.gitcd thmakemake thesaurus.db프로그램을 플레이하여 마음에 드는지 확인하세요. 빌드 디렉토리 외부에서 사용 가능하도록 설치하려면 다음 명령을 호출하십시오.
sudo make install
프로그램이 필요하지 않다고 판단되면 프로그램을 쉽게 제거할 수 있습니다.
프로그램을 설치했다면 먼저 sudo make uninstall 으로 제거하세요.
이렇게 하면 프로그램, 지원 파일 및 지원 파일이 설치된 디렉터리가 제거됩니다.
프로그램이 설치되어 있지 않으면 복제된 디렉터리를 삭제해도 안전합니다.
다음 자료는 개발자라면 누구든지 주로 관심을 가질 것입니다.
이 프로젝트는 구축하기 쉽지만 다른 소프트웨어에 따라 다릅니다. 다음은 종속성 목록이며, 그 중 첫 번째(Berkeley 데이터베이스)에만 약간의 개입이 필요할 수 있습니다. 아래 항목 3과 4는 빌드 디렉터리 아래의 하위 디렉터리에 다운로드되며, 거기에서 발견된 코드는 실행 파일에 정적으로 연결되므로 환경에 영향을 미치지 않습니다.
프로젝트의 B-Tree 데이터베이스에는 db 버전 5 (Berkeley Database)가 필요합니다. git 을 사용하고 있다면 이미 db 의 이전 버전만 포함하고 있는 FreeBSD 에도 이 기능이 있어야 합니다. Make는 적절한 db를 찾을 수 없으면 메시지와 함께 즉시 종료됩니다. 이 경우 패키지 관리자를 사용하여 db를 설치하거나 소스에서 빌드하는 것은 사용자에게 달려 있습니다.
git은 일부 종속성을 다운로드하는 데 사용됩니다. 프로젝트 종속성은 git 없이 직접 다운로드할 수 있지만 그렇게 하려면 소스 파일에 대한 문서화되지 않은 지식이 필요하며 make가 git을 사용하여 종속성을 다운로드할 때 피할 수 있는 문제입니다.
readargs는 명령줄 인수를 처리하는 프로젝트 중 하나입니다. 이 프로젝트는 th 에서 계속 사용되지만 th 가 작동하기 위해 더 이상 이 라이브러리를 설치할 필요가 없습니다. 이제 Makefile 은 readargs 프로젝트를 하위 디렉터리에 다운로드하고 이를 빌드한 후 대신 정적 라이브러리를 사용합니다.
c_patterns는 라이브러리 없이 재사용 가능한 코드를 관리하는 실험인 또 다른 프로젝트입니다. Makefile은 git을 사용하여 프로젝트를 다운로드한 다음 src 디렉터리에 있는 일부 c_patterns 모듈에 대한 링크를 만들어 번째 빌드에 포함시킵니다.
이 프로젝트는 (적어도 나에게는) 유용하지만 실험이기도 합니다. 내 목표 중 하나는 makefile 작성 기술을 향상시키는 것입니다. 제가 내린 빌드 및 설치 결정 중 일부는 모범 사례가 아닐 수도 있고 경험이 많은 개발자라면 눈살을 찌푸릴 수도 있습니다. th 설치하면 시스템에 어떤 일이 일어날지 걱정된다면 다음 내용을 참고하여 결정하시기 바랍니다.
예상대로 make는 번째 애플리케이션을 컴파일합니다. 일반적으로 make는 시간이 좀 걸릴 수 있는 다른 작업을 수행할 수도 있습니다.
내 C 모듈 저장소를 다운로드하고 src 디렉토리에 링크를 만들어 그 중 여러 개를 사용합니다.
종속성을 확인하기 위해 configure 사용하는 대신 makefile은 누락된 종속성을 감지하면 유용한 메시지를 식별하고 즉시 종료합니다.
구텐베르그 프로젝트에서 공개 도메인 moby 동의어 사전을 다운로드하고 가져오세요. 그러면 응용 프로그램의 단어 데이터베이스가 채워집니다.
포기됨 단어 개수 데이터베이스를 다운로드하고 가져옵니다. 아이디어는 더 긴 목록에서 단어를 더 쉽게 찾을 수 있도록 대체 정렬 순서를 제공하는 것입니다. 지금은 작동하지 않습니다. 알파벳순 목록을 읽는 것의 이점이 일반적으로 사용되는 단어를 먼저 배치하는 것의 모호한 이점보다 훨씬 크기 때문에 이 문제를 다시 다룰지 잘 모르겠습니다. 그 이유는 긴 단어 목록에 무작위로 흩어져 있지 않으면 고려 중인 단어를 추적하는 것이 훨씬 쉽기 때문입니다.
출력을 구성하는 데 도움이 될 수 있는 Moby 품사 목록 리소스가 있다는 것을 방금 확인했습니다. 흥미롭긴 하지만 알파벳순 정렬이 출력 사용에 얼마나 도움이 되는지에 따라 도움이 될지 확신할 수 없습니다. 두고 보자.
이 프로젝트를 시작할 때 나는 몇 가지 목표를 가지고 있었습니다.
저는 Berkeley Database 에 대해 더 많은 경험을 갖고 싶었습니다. 이 키 저장소 데이터베이스는 git 및 sqlite를 포함한 다른 많은 애플리케이션을 뒷받침합니다.
저는 c_patterns 프로젝트 모듈 중 일부를 사용하여 연습하고 싶었습니다. 실제 프로젝트에서 이러한 모듈을 사용하면 설계 결함과 누락된 기능을 이해하는 데 도움이 됩니다. 나는 사용한다
columnize.c를 사용하여 열 형식 출력을 생성합니다.
출력 하단의 최소 옵션 메뉴에 대한 Prompter.c ,
에코되지 않은 키 누르기를 위한 get_keypress.c . 주로 Prompter.c 에서 사용됩니다.
저는 Gnu Linux와 BSD 모두에서 작동하는 빌드 프로세스 설계를 연습하고 싶었습니다. 여기에는 누락된 모듈(특히 BSD에 너무 오래된 라이브러리가 포함된 db ) 식별 및 재설계된 조건부 처리가 포함됩니다.
Windows는 BSD보다 Linux에서 더 많이 다르기 때문에 Windows를 대상으로 하지 않으며 많은 Windows 사용자가 명령줄 응용 프로그램을 사용하는 것이 편할 것이라고 기대하지 않습니다.
Berkeley Database( bdb )는 흥미로운 데이터베이스 제품인 것 같습니다. 낮은 수준의 C 라이브러리 접근 방식은 제가 1990년대 후반에 사용했던 FairCom DB 엔진과 유사해 보입니다.
Berkeley 데이터베이스는 Linux 및 BSD 배포판의 일부이고 설치 공간이 작기 때문에 매력적입니다. 이는 데이터의 세부 계획에 대한 보상이며 내 C 언어 아이디어 중 일부를 탐색하는 변명입니다.
이 프로젝트는 명령줄 동의어 사전 및 사전을 의미하는 mywords 프로젝트의 다시 시작입니다. 그 프로젝트는 제가 처음으로 bdb 를 사용한 프로젝트였기 때문에 제가 한 작업 중 일부는 약간 서투릅니다. bdb 코드를 처음부터 다시 디자인하고 싶습니다. 여기에 적용할 단어 프로젝트의 텍스트 구문 분석 코드 중 일부를 복사하겠습니다.
동의어 사전과 사전이라는 대규모 데이터 세트를 사용하여 Queue와 Recno 데이터 액세스 방법 간의 성능 차이도 테스트하고 싶습니다. 고정 길이 레코드의 시작과 끝을 계산할 수 있으므로 Queue가 더 빨라질 것으로 기대합니다. 특정 가변 길이 레코드의 레코드 번호로 액세스하려면 파일 위치를 검색해야 합니다. 가변 길이 레코드의 저장 효율성과 그 이점을 비교하기 위해 성능 차이를 측정하고 싶습니다.
동의어 사전에는 두 가지 공개 도메인 소스가 있습니다.
Moby 동의어 사전을 사용하는 이유는 조직이 훨씬 간단하고 분석하기 쉽기 때문입니다. 문제는 동의어가 많고 구성이 부족하여 적절한 동의어를 검색할 때 스캔하기가 훨씬 어렵다는 것입니다.
많은 단어에 대한 수백 개의 동의어가 있으므로 목록을 검색하여 적절한 단어를 찾는 것이 매우 어렵습니다. 나는 더 쉽게 사용할 수 있도록 목록에 몇 가지 순서를 부여하려고 노력할 것입니다. 한동안 이 도구를 사용한 후 알파벳 순서가 가장 좋다는 결론을 내렸습니다. 알파벳 목록의 단어로 돌아가는 것이 훨씬 쉽습니다. 다른 단어 순서를 선택하는 옵션을 제거했습니다.
가장 사용하기 쉬운 분류는 단어 사용 빈도입니다. 가장 많이 사용되는 단어부터 가장 적게 사용되는 단어까지 나열할 계획입니다. 아마도 더 인기 있는 단어가 최선의 선택일 수 있는 반면, 덜 인기 있는 단어는 쓸모가 없을 수도 있습니다.
단어 빈도의 출처는 여러 가지가 있습니다. 내가 사용하는 것은 Google ngram을 기반으로 합니다.
자연어 코퍼스 데이터: 아름다운 데이터
나는 Norvig 소스를 실제로 연구하지 않았기 때문에 말도 안되는 내용이 많을 가능성이 있습니다. 좀 더 정리된 목록이 있는 또 다른 소스인 hackerb9/gwordlist가 있습니다. Norvig에 문제가 있는 경우 이를 대체할 수 있는 대체 목록을 기억하고 싶습니다.
이 부분은 더 이상 시도되지 않습니다. 사전의 고유 표기법을 인식하고 유니코드 문자로 변환해야 하므로 원본 데이터를 해석하는 것은 복잡합니다. 이러한 문제 중 많은 부분을 해결했지만 여전히 많은 문제가 남아 있습니다. Makefile에는 여전히 이 정보를 다운로드하기 위한 지침이 포함되어 있으며 저장소에는 내가 다시 방문하고 싶은 경우를 대비해 일부 변환 스크립트가 보관되어 있습니다.
품사(예: 명사, 동사, 형용사 등)별로 동의어를 그룹화하는 것도 유용할 수 있습니다. 첫 번째 문제는 각 단어가 나타내는 품사를 식별하는 것입니다. 두 번째 문제는 표현에 있습니다. 사용자가 단어를 표시하기 전에 품사를 선택하도록 하는 인터페이스를 갖는 것이 더 좋지만 프로그래밍하기가 더 어렵습니다.
전자, 공개 도메인 사전
나의 첫 번째 시도는 GNU Collaborative International Dictionary of English (GCIDE)를 사용하는 것입니다. 이것은 Webster의 오래된 버전(1914년)을 기반으로 하며 최신 편집자들이 일부 단어를 추가했습니다.


