

MultiProcessing Is really Easy의 약자인 MPIRE 다중 처리를 위한 Python 패키지입니다. MPIRE 대부분의 시나리오에서 더 빠르고 더 많은 기능을 포함하며 일반적으로 기본 다중 처리 패키지보다 사용자에게 더 친숙합니다. multiprocessing.Pool 기능과 같은 편리한 맵과 multiprocessing.Process 쓰기 시 복사 공유 개체를 사용하는 이점을 사용하기 쉬운 작업자 상태, 작업자 통찰력, 작업자 초기화 및 종료 기능, 시간 초과 및 진행 표시줄 기능.
전체 문서는 https://sybrenjansen.github.io/mpire/에서 확인할 수 있습니다.
map / map_unordered / imap / imap_unordered / apply / apply_async 함수를 사용한 다중 처리fork 에만 사용 가능)rich 및 노트북 위젯이 지원됨)daemon 옵션을 설정할 때 중첩된 작업자 풀이 허용됩니다.MPIRE는 Linux, macOS 및 Windows에서 테스트되었습니다. Windows 및 macOS 사용자의 경우 문제 해결 장에 설명된 몇 가지 사소한 알려진 주의 사항이 있습니다.
pip(PyPi)를 통해:
pip install mpireMPIRE는 conda-forge를 통해서도 사용할 수 있습니다.
conda install -c conda-forge mpire 일부 입력을 받고 그 결과를 반환하는 시간이 많이 걸리는 함수가 있다고 가정해 보겠습니다. 이와 같은 간단한 기능은 당황스러울 정도로 병렬 문제, 즉 병렬 작업으로 전환하는 데 거의 또는 전혀 노력이 필요하지 않은 기능으로 알려져 있습니다. 간단한 함수를 병렬화하는 것은 multiprocessing 가져오고 multiprocessing.Pool 클래스를 사용하는 것만큼 쉬울 수 있습니다.
import time
from multiprocessing import Pool
def time_consuming_function ( x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
with Pool ( processes = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) MPIRE는 거의 multiprocessing 를 즉시 대체할 수 있습니다. mpire.WorkerPool 클래스를 사용하고 사용 가능한 map 함수 중 하나를 호출합니다.
from mpire import WorkerPool
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 )) 코드의 차이는 작습니다. 바닐라 multiprocessing 에 익숙하다면 완전히 새로운 다중 처리 구문을 배울 필요가 없습니다. 그러나 사용 가능한 추가 기능은 MPIRE를 차별화하는 요소입니다.
현재 작업의 상태(완료된 작업 수, 작업 준비까지 얼마나 걸림)를 알고 싶다고 가정해 보겠습니다. progress_bar 매개변수를 True 로 설정하는 것만큼 간단합니다.
with WorkerPool ( n_jobs = 5 ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )그리고 멋진 형식의 tqdm 진행률 표시줄이 출력됩니다.
MPIRE는 추가 종속성을 설치해야 하는 대시보드도 제공합니다. 자세한 내용은 대시보드를 참조하세요.
참고: 쓰기 중 복사 공유 객체는 시작 방법 fork 에만 사용할 수 있습니다. threading 의 경우 개체는 있는 그대로 공유됩니다. 다른 시작 방법의 경우 공유 객체는 각 작업자에 대해 한 번씩 복사됩니다. 이는 작업당 한 번보다 더 나을 수 있습니다.
모든 작업자 간에 공유하려는 개체가 하나 이상 있는 경우 MPIRE의 쓰기 시 복사 shared_objects 옵션을 사용할 수 있습니다. MPIRE는 복사/직렬화 없이 각 작업자에 대해 이러한 개체를 한 번만 전달합니다. 작업자 함수에서 객체를 변경하는 경우에만 해당 작업자에 대해 객체를 복사하기 시작합니다.
def time_consuming_function ( some_object , x ):
time . sleep ( 1 ) # Simulate that this function takes long to complete
return ...
def main ():
some_object = ...
with WorkerPool ( n_jobs = 5 , shared_objects = some_object ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ), progress_bar = True )자세한 내용은 shared_objects를 참조하세요.
worker_init 기능을 사용하여 작업자를 초기화할 수 있습니다. worker_state 와 함께 모델을 로드하거나 데이터베이스 연결 등을 설정할 수 있습니다.
def init ( worker_state ):
# Load a big dataset or model and store it in a worker specific worker_state
worker_state [ 'dataset' ] = ...
worker_state [ 'model' ] = ...
def task ( worker_state , idx ):
# Let the model predict a specific instance of the dataset
return worker_state [ 'model' ]. predict ( worker_state [ 'dataset' ][ idx ])
with WorkerPool ( n_jobs = 5 , use_worker_state = True ) as pool :
results = pool . map ( task , range ( 10 ), worker_init = init ) 마찬가지로, worker_exit 기능을 사용하여 작업자가 종료될 때마다 MPIRE가 함수를 호출하도록 할 수 있습니다. 이 종료 함수가 나중에 얻을 수 있는 결과를 반환하도록 할 수도 있습니다. 자세한 내용은 작업자_init 및 작업자_종료 섹션을 참조하세요.
멀티프로세싱 설정이 원하는 대로 작동하지 않고 원인이 무엇인지 알 수 없는 경우 작업자 인사이트 기능이 있습니다. 이렇게 하면 설정에 대한 통찰력을 얻을 수 있지만 실행 중인 기능을 프로파일링하지는 않습니다(다른 라이브러리가 있음). 대신 작업자 시작 시간, 대기 시간 및 작업 시간을 프로파일링합니다. 작업자 초기화 및 종료 기능이 제공되면 시간도 측정됩니다.
아마도 작업 대기열을 통해 많은 양의 데이터를 전송하고 있어 대기 시간이 길어질 수 있습니다. 어떤 경우이든, 각각 enable_insights 플래그와 mpire.WorkerPool.get_insights 함수를 사용하여 통찰력을 활성화하고 얻을 수 있습니다.
with WorkerPool ( n_jobs = 5 , enable_insights = True ) as pool :
results = pool . map ( time_consuming_function , range ( 10 ))
insights = pool . get_insights ()더 자세한 예와 예상 결과는 작업자 통찰력을 참조하세요.
대상, worker_init 및 worker_exit 함수에 대해 시간 초과를 별도로 설정할 수 있습니다. 제한 시간이 설정되어 도달하면 TimeoutError 발생합니다.
def init ():
...
def exit_ ():
...
# Will raise TimeoutError, provided that the target function takes longer
# than half a second to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), task_timeout = 0.5 )
# Will raise TimeoutError, provided that the worker_init function takes longer
# than 3 seconds to complete or the worker_exit function takes longer than
# 150.5 seconds to complete
with WorkerPool ( n_jobs = 5 ) as pool :
pool . map ( time_consuming_function , range ( 10 ), worker_init = init , worker_exit = exit_ ,
worker_init_timeout = 3.0 , worker_exit_timeout = 150.5 ) threading 시작 방법으로 사용하는 경우 MPIRE는 time.sleep 과 같은 특정 기능을 중단할 수 없습니다.
자세한 내용은 시간 초과를 참조하세요.
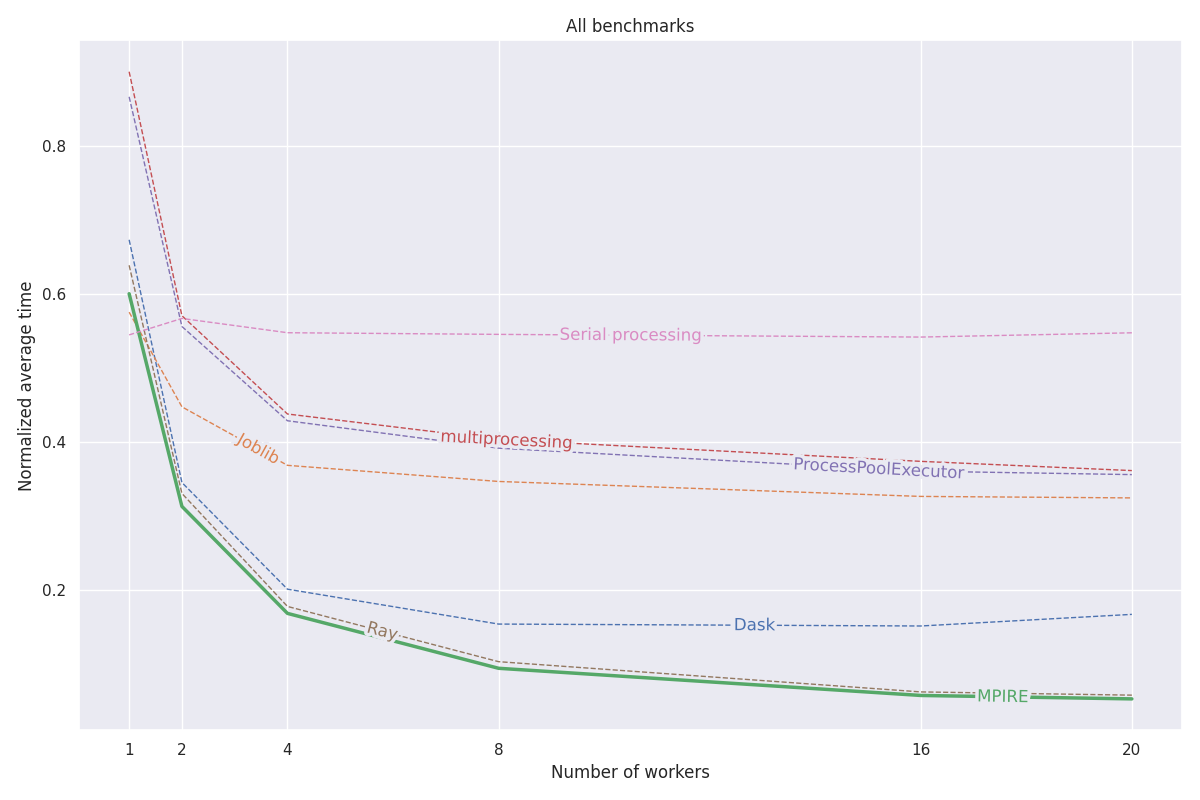
MPIRE는 수치 계산, 상태 저장 계산, 비용이 많이 드는 초기화라는 세 가지 벤치마크에서 벤치마킹되었습니다. 이러한 벤치마크에 대한 자세한 내용은 이 블로그 게시물에서 확인할 수 있습니다. 이러한 벤치마크의 모든 코드는 이 프로젝트에서 찾을 수 있습니다.
즉, MPIRE가 더 빠른 주요 이유는 다음과 같습니다.
fork 사용할 수 있으면 쓰기 중 복사 공유 객체를 사용할 수 있으므로 하위 프로세스에서 공유해야 하는 객체를 복사할 필요성이 줄어듭니다.다음 그래프는 세 가지 벤치마크 모두의 평균 정규화 결과를 보여줍니다. 개별 벤치마크 결과는 블로그 게시물에서 확인할 수 있습니다. 벤치마크는 20개 코어, 비활성화된 하이퍼스레딩 및 200GB RAM을 갖춘 Linux 시스템에서 실행되었습니다. 각 작업에 대해 다양한 수의 프로세스/작업자를 사용하여 실험을 실행했으며 결과는 평균 5번 실행되었습니다.
MPIRE의 다른 모든 기능에 대한 자세한 내용은 https://sybrenjansen.github.io/mpire/에서 전체 설명서를 참조하세요.
문서를 직접 작성하려면 다음을 실행하여 문서 종속성을 설치하십시오.
pip install mpire[docs]또는
pip install .[docs]그런 다음 Python <= 3.9를 사용하고 다음을 실행하여 문서를 작성할 수 있습니다.
python setup.py build_docs 문서는 docs 폴더에서 직접 작성할 수도 있습니다. 이 경우 현재 작업 환경에서 MPIRE 설치하고 사용할 수 있어야 합니다. 그런 다음 다음을 실행합니다.
make html docs 폴더에 있습니다.


