지하철 관리 시스템
SUSTech 2024 봄 강좌 CS307 - Principles of Database System
Shenzhen-Metro
├── Project1 # part 1 of project (database design and data import)
│ ├── ShenzhenMetroDatabaseDesign
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # import script in java
│ │ │ │ ├── resources # data in json
│ │ │ │ └── sql # ddl
│ └── ShenzhenMetroDatabaseDesignPython
│ ├── import_script.py # import script in python
│ └── resources # data in json
├── Project2 # part 2 of project (building an api)
│ ├── DataImport # updated data import
│ │ ├── src
│ │ │ ├── main
│ │ │ │ ├── java # updated import script in java
│ │ │ │ ├── resources # updated data
│ │ │ │ └── sql # updated ddl
│ └── ShenzhenMetro # spring boot project
│ ├── src
│ │ ├── main
│ │ │ ├── java # backend logic
│ │ │ │ └── com/sustech/cs307/project2/shenzhenmetro
│ │ │ │ ├── ShenzhenMetroApplication.java # main application driver
│ │ │ │ ├── controller # api route mapping
│ │ │ │ ├── dto # dto between client and server
│ │ │ │ ├── object # orm between database tables and application code
│ │ │ │ ├── repository # interfaces for data access
│ │ │ │ └── service # service layer containing business logic
│ │ │ └── resources # frontend logic
│ │ │ ├── application.properties # configuration file for spring boot application
│ │ │ ├── static
│ │ │ │ ├── assets
│ │ │ │ │ ├── css
│ │ │ │ │ ├── img
│ │ │ │ │ ├── js
│ │ │ │ │ └── vendor
│ │ │ │ │ ├── aos
│ │ │ │ │ ├── bootstrap
│ │ │ │ │ ├── bootstrap-icons
│ │ │ │ │ ├── glightbox
│ │ │ │ │ └── swiper
│ │ │ │ └── index.html # main html
│ │ │ └── templates
│ │ │ ├── buses
│ │ │ │ ├── create_bus.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_bus.html
│ │ │ ├── landmarks
│ │ │ │ ├── create_landmark.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_landmark.html
│ │ │ ├── lineDetails
│ │ │ │ ├── create_line_detail.html
│ │ │ │ ├── index.html
│ │ │ │ ├── navigate_routes.html
│ │ │ │ └── search_line_detail.html
│ │ │ ├── lines
│ │ │ │ ├── create_line.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_line.html
│ │ │ ├── ongoingRides
│ │ │ │ └── index.html
│ │ │ ├── rides
│ │ │ │ ├── create_ride.html
│ │ │ │ ├── filter_ride.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_ride.html
│ │ │ ├── stations
│ │ │ │ ├── create_station.html
│ │ │ │ ├── index.html
│ │ │ │ └── update_station.html
│ │ │ └── users
│ │ │ ├── card.html
│ │ │ └── passenger.html
└── README.md
프로젝트의 첫 번째 부분은 주로 제공된 데이터의 배경을 기반으로 관계형 데이터베이스의 원리를 만족하는 데이터베이스 스키마를 설계하는 것입니다. 설계 단계가 완료되면 대규모 데이터 세트를 가져오는 스크립트를 작성했습니다. 가져온 데이터의 정확성을 보장하기 위해 방어일에 몇 가지 쿼리문을 수행하고 쿼리 결과를 확인해야 했습니다. 그 외에도 나중에 볼 수 있듯이 놀라운 통찰력을 얻기 위해 데이터로 몇 가지 실험을 수행했습니다.
[상세 요구사항 읽어보기]
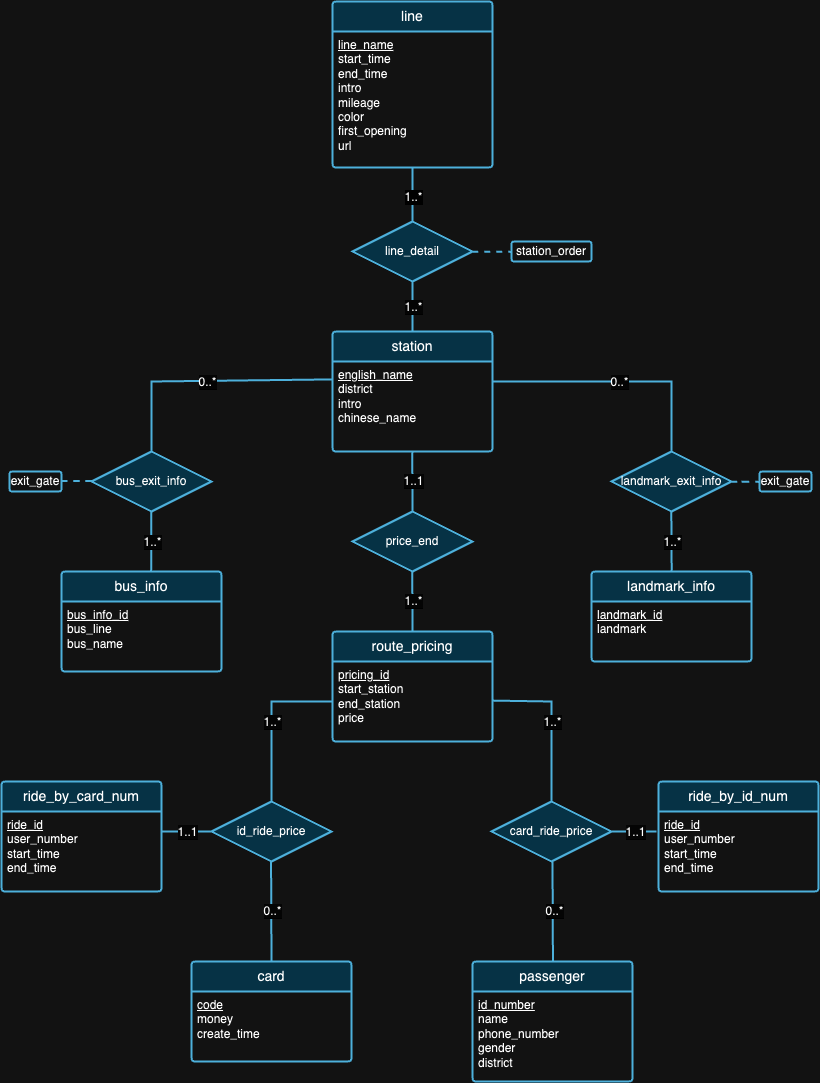
우리는 데이터베이스 디자인이 완벽할 수는 없다고 믿습니다. 실제로 위의 ER 다이어그램에서 우리가 제안한 설계에는 결함이 있습니다. 데이터세트와 각 데이터세트의 배경을 살펴본 후 스스로 디자인 결함을 찾아낼 수 있기를 바랍니다. :)
참고 : 그림 해석을 위해서는
| ID | 운영체제 | 칩 | 메모리 | SSD | 도구 |
|---|---|---|---|---|---|
| 1 | macOS 소노마 14.4.1 | 애플 M3 프로 | 18GB | 1TB | IDEA 2024.1(CE), PyCharm 2023.3.4(CE), Datagrip 2024.1 |
| 2 | 윈도우 11 홈 23H2 | 12세대 인텔(R) 코어(TM) i9-12900H | 32GB | 1TB | IDEA 2024.1(CE), 데이터그립 2024.1 |
| 3 | 우분투 22.04.4(VM) | 애플 M1 프로 | 16GB | 512GB | IDEA 2024.1(CE), 데이터그립 2024.1 |
Experiment 1: Different Import Methods 방법 1(원본 스크립트): 이 방법은 java.sql 라이브러리를 활용합니다. 먼저 PostgreSQL 서버에 대한 연결을 설정했습니다. 그런 다음 JSON 파일에서 모든 데이터를 읽습니다. 다음으로 각 데이터를 반복하고 각 삽입 문에 대해 PreparedStatement 만들었습니다. 마지막으로 각 명령문을 개별적으로 실행하기 위해 executeUpdate() 메서드를 호출했습니다.
방법 2(최적화된 스크립트): 이 방법도 java.sql 라이브러리를 활용하고 방법 1과 동일한 데이터 읽기 알고리즘을 사용합니다. 차이점은 이제 executeBatch() 메서드를 사용한다는 것입니다. 그래서 우리는 전체 데이터를 반복하고, PreparedStatement 사용하여 각 삽입 문을 생성하고, 배치 실행을 위해 배치에 각 PreparedStatement 추가했습니다.
방법 3(.sql 파일 실행): 우리는 Java 프로그램을 사용하여 SQL 삽입 문을 생성하고 위에서 언급한 것과 동일한 데이터 읽기 알고리즘을 사용하여 이를 .sql 파일에 썼습니다. 그런 다음 DataGrip에서 파일을 실행합니다.
세 가지 방법 모두에서 동일한 데이터 읽기 알고리즘을 사용하므로 후속 테스트에서는 평균 런타임을 사용합니다. 우리는 처음에 504ms, 546ms, 552ms의 세 가지 런타임을 수집하여 534ms의 평균 런타임을 계산했습니다.
| 테스트 환경 | 방법 | 평균 읽기 시간(ms) | 쓰기 시간(ms) | 총 시간(밀리초) | 처리량(문/초) |
|---|---|---|---|---|---|
| 1 | 1 | 534 | 206396 | 206930 | 8636.91 |
| 1 | 2 | 534 | 2114 | 2648 | 97632.92 |
| 1 | 3 | 534 | 13581 | 14115 | 15197.41 |
표 2는 다양한 방법에 따른 다양한 성능 지표를 보여줍니다. 방법 2는 가장 높은 처리량을 나타내고 방법 1은 가장 느린 총 시간을 나타냅니다. 이로 인해 방법 2가 향후 실험의 표준 테스트 방법이 됩니다.
Experiment 2: Data Import with Different Data Volumes다양한 볼륨의 데이터를 관리하고 가져오는 것은 데이터베이스 시스템의 성능, 확장성 및 안정성을 보장하는 데 있어 중요한 측면입니다.
가져오기 프로세스 전에 '탑승' 데이터의 양이 다른 데이터에 비해 눈에 띄게 크다는 것을 확인했습니다. 이 아이디어를 바탕으로 우리는 ride.json 에서만 다양한 볼륨으로 데이터 가져오기를 테스트하기로 결정했습니다. 데이터의 가중치가 일정하지 않기 때문에 다른 테이블에 대해 더 적은 양을 가져오면 테이블 간의 연결성으로 인해 심각한 문제가 발생할 수 있습니다.
처음에는 디자인의 일관성을 보장하기 위해 rides_by_id_num 및 rides_by_card_num 테이블을 제외한 다른 모든 테이블의 전체 데이터(100% 볼륨)를 가져오는 것부터 시작했습니다. 이를 효과적으로 관리하기 위해 우리는 20,000개의 기록에 해당하는 데이터의 20% 하위 집합부터 시작하여 ride 데이터에 대한 단계적 가져오기 전략을 채택했습니다. 이 초기 단계를 통해 우리는 시스템 성능에 미치는 영향을 평가하고 데이터베이스 안정성을 손상시키지 않고 가져오기 프로세스에 필요한 조정을 수행할 수 있었습니다. 검증과 성능 튜닝에 성공한 후 데이터의 50% 가져오기를 진행했고, 마지막으로 나머지 부분을 가져와 100% 데이터 가져오기를 완료했습니다. 가장 빠른 방법이므로 모든 가져오기에 방법 2를 사용했습니다.
| 테스트 환경 | 방법 | 용량 | 읽기 시간(ms) | 쓰기 시간(ms) | 총 시간(밀리초) | 명세서 수 | 처리량(문/초) |
|---|---|---|---|---|---|---|---|
| 1 | 2 | 20% | 507 | 808 | 1315 | 80165 | 99214.11 |
| 1 | 2 | 50% | 521 | 1338 | 1859년 | 130849 | 97794.47 |
| 1 | 2 | 100% | 534 | 2114 | 2648 | 203502 | 96263.95 |
표 3에서 볼 수 있듯이 데이터 볼륨이 증가하면(20%에서 50%, 100%로) 읽기 및 쓰기 시간이 모두 증가하는 경향이 있어 총 작업 시간이 길어집니다. 그러나 수입량이 다르기 때문에 이러한 수치는 통찰력 있는 의미를 제공하지 않습니다. 대신 처리량 수를 살펴보면 데이터 양이 증가함에 따라 처리량(명령문/초)이 점차 감소하는데, 이는 워크로드가 증가함에 따라 시스템의 명령문 처리 효율성이 떨어지는 것을 나타냅니다.
Experiment 3: Data Import on Different Operating Systems다양한 OS에서 데이터를 가져오는 프로세스를 테스트할 때 가장 빠른 가져오기 방법인 방법 2를 사용하여 가져오기 볼륨을 100%로 사용했습니다.
가상 머신을 통해 Linux에서 Java 가져오기 스크립트를 실행할 때 가상화로 인해 오버헤드가 발생하고 시스템 효율성에 영향을 미칠 수 있으므로 성능 및 리소스 할당에 대한 불공평한 단점을 고려하는 것이 중요합니다.
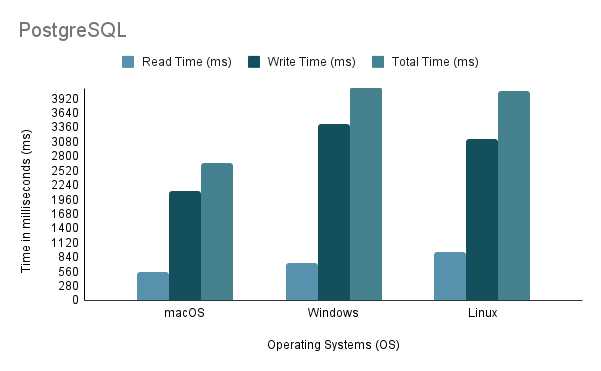
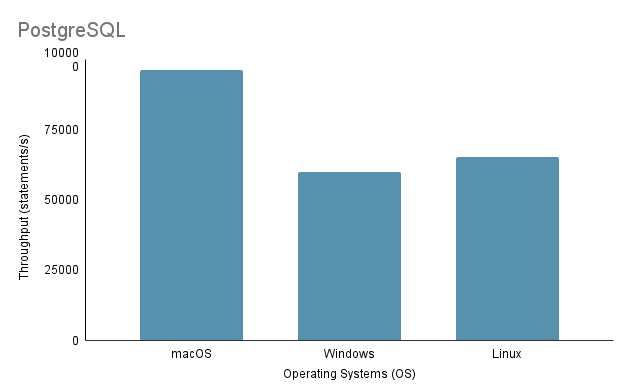
위의 분석을 바탕으로 환경 1(macOS)이 2648ms의 가장 짧은 총 시간과 97,632.92 문/초의 가장 높은 처리량으로 최고의 성능을 나타내는 것이 분명합니다. 이와 대조적으로 환경 2(Windows)는 총 시간이 4117ms로 가장 느리고 처리량이 60,669.02 문/초로 가장 낮습니다. Linux Ubuntu가 VM으로 실행되는 동안 여전히 베어 메탈 Windows보다 성능이 뛰어나다는 점은 주목할 가치가 있습니다.
Experiment 4: Data Import with Various Programming Languages본 실험에서는 Java 코드에 대해 위에서 언급한 방법 2가 가장 빠르기 때문에 사용했습니다. 한편 Python의 경우 Psycopg2를 사용하여 PostgreSQL 데이터베이스 서버와 통신하는 가져오기 메서드를 작성했습니다.
| 테스트 환경 | 프로그래밍 언어 | 읽기 시간(ms) | 쓰기 시간(ms) | 총 시간(밀리초) | 처리량(문/초) |
|---|---|---|---|---|---|
| 1 | 자바 | 534 | 2114 | 2648 | 96263.95 |
| 1 | 파이썬 | 390 | 7237 | 7627 | 28119.66 |
표 4의 데이터는 Java가 속도와 처리량 모두에서 Python보다 뛰어난 성능을 보여 읽기-쓰기 작업의 효율성이 우수함을 나타냅니다.
Experiment 5: Data Import on Different Databases우리는 PostgreSQL과 MySQL 모두에 대해 세 가지 다른 가져오기 방법을 개발했지만 데이터 가져오기를 위해 개발자가 선택하는 방법 2에 대해서만 실험을 실행했습니다. PostgreSQL과 MySQL은 모두 유사한 데이터베이스 구현 디자인(DDL 방식)과 유사한 가져오기 코드 디자인을 가지고 있습니다.
| 테스트 환경 | 방법 | 데이터 베이스 | 읽기 시간(ms) | 쓰기 시간(ms) | 총 시간(밀리초) | 처리량(문/초) |
|---|---|---|---|---|---|---|
| 1 | 2 | 포스트그레SQL | 534 | 2114 | 2648 | 96263.95 |
| 1 | 2 | MySQL | 534 | 42315 | 42849 | 4809.22 |
둘 다 SQL 기반 데이터베이스임에도 불구하고 PostgreSQL은 쓰기 시간 측면에서 약 16배 더 빠릅니다. 이는 데이터베이스 엔진 아키텍처와 드라이버 구현(PostgreSQL의 경우 postgresql-42.2.5.jar , MySQL의 경우 mysql-connector-j-8.3.0.jar )의 차이로 인해 발생할 수 있습니다.
프로젝트의 2부에서는 API(애플리케이션 프로그래밍 인터페이스) 세트를 노출하는 백엔드 라이브러리를 구축하여 데이터베이스 시스템에 액세스하는 기본 기능을 제공하는 데 중점을 둡니다. 가져와야 하는 추가 데이터세트도 있으므로 업데이트된 데이터베이스 구현이 필요합니다( ./Project2/DataImport 에서 찾을 수 있음).
[상세 요구사항 읽어보기]
./Project2/DataImport/src/main/sql/ddl.sql 에 제공된 DDL을 사용하여 MySQL 데이터베이스를 설정합니다../Project2/DataImport/src/main/java/ImportScript.java 에 제공된 스크립트를 사용하여 데이터를 가져옵니다../Project2/ShenzhenMetro ) 빌드(IntelliJ IDEA IDE 권장)

