Candle은 성능(GPU 지원 포함)과 사용 편의성에 중점을 둔 Rust용 미니멀한 ML 프레임워크입니다. 온라인 데모를 사용해 보세요: 속삭임, LLaMA2, T5, yolo, Segment Anything.
설치 에 설명된 대로 candle-core 올바르게 설치되었는지 확인하십시오.
간단한 행렬 곱셈을 실행하는 방법을 살펴보겠습니다. myapp/src/main.rs 파일에 다음을 작성합니다.
use candle_core :: { Device , Tensor } ;
fn main ( ) -> Result < ( ) , Box < dyn std :: error :: Error > > {
let device = Device :: Cpu ;
let a = Tensor :: randn ( 0f32 , 1. , ( 2 , 3 ) , & device ) ? ;
let b = Tensor :: randn ( 0f32 , 1. , ( 3 , 4 ) , & device ) ? ;
let c = a . matmul ( & b ) ? ;
println ! ( "{c}" ) ;
Ok ( ( ) )
} cargo run Tensor[[2, 4], f32] 모양의 텐서가 표시되어야 합니다.
Cuda를 지원하는 candle 설치한 후 GPU에 device 정의하기만 하면 됩니다.
- let device = Device::Cpu;
+ let device = Device::new_cuda(0)?;더 고급 예제를 보려면 다음 섹션을 살펴보세요.
이러한 온라인 데모는 브라우저에서 완전히 실행됩니다.
또한 최첨단 모델을 사용하여 몇 가지 명령줄 기반 예제도 제공합니다.
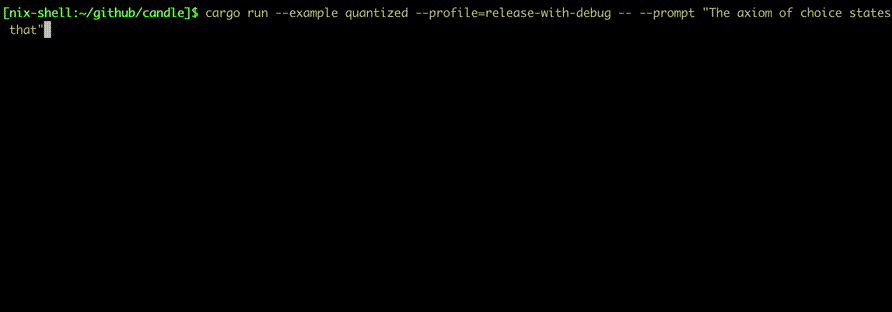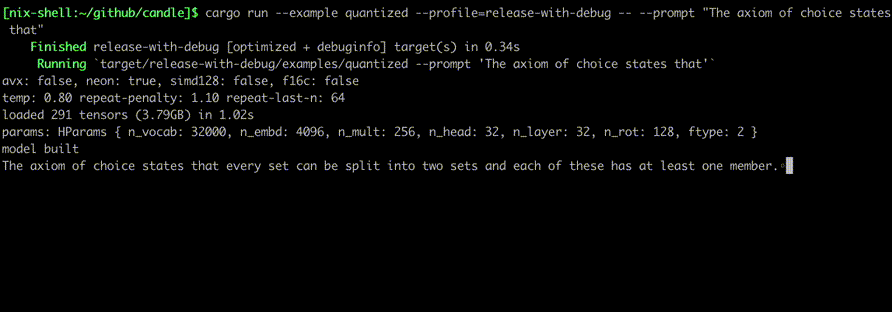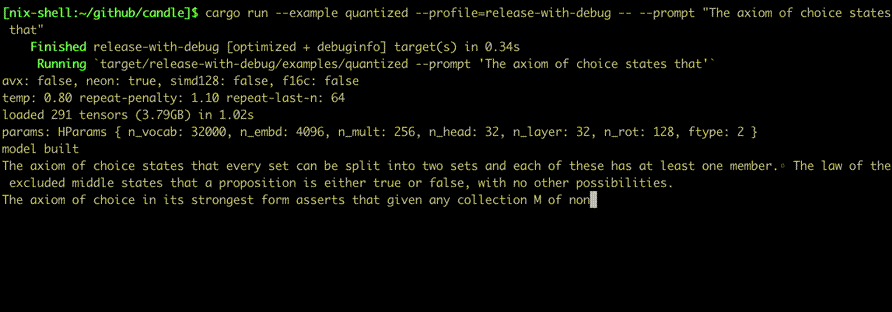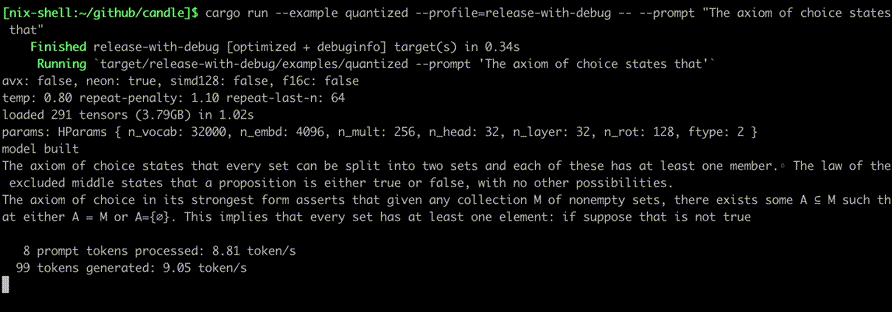





다음과 같은 명령을 사용하여 실행하십시오.
cargo run --example quantized --release
CUDA를 사용하려면 예제 명령줄에 --features cuda 추가하세요. cuDNN이 설치되어 있는 경우 --features cudnn 사용하면 더욱 빠른 속도를 얻을 수 있습니다.
속삭임과 llama2.c에 대한 몇 가지 wasm 예제도 있습니다. trunk 사용하여 구축하거나 온라인으로 사용해 볼 수 있습니다(Whisper, llama2, T5, Phi-1.5 및 Phi-2, Segment Anything 모델).
LLaMA2의 경우 다음 명령을 실행하여 가중치 파일을 검색하고 테스트 서버를 시작합니다.
cd candle-wasm-examples/llama2-c
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
trunk serve --release --port 8081그런 다음 http://localhost:8081/로 이동합니다.
candle-tutorial : PyTorch 모델을 Candle로 변환하는 방법을 보여주는 매우 자세한 튜토리얼입니다.candle-lora : 캔들을 위한 효율적이고 인체공학적인 LoRA 구현입니다. candle-lora 에는optimisers : 운동량을 갖춘 SGD, AdaGrad, AdaDelta, AdaMax, NAdam, RAdam 및 RMSprop를 포함한 옵티마이저 모음입니다.candle-vllm : OpenAI 호환 API 서버를 포함한 로컬 LLM 추론 및 제공을 위한 효율적인 플랫폼입니다.candle-ext : 현재 Candle에서 사용할 수 없는 PyTorch 기능을 제공하는 Candle의 확장 라이브러리입니다.candle-coursera-ml : Coursera의 기계 학습 전문화 과정에서 ML 알고리즘을 구현합니다.kalosm : 제어된 생성, 사용자 정의 샘플러, 메모리 내 벡터 데이터베이스, 오디오 전사 등을 지원하여 사전 훈련된 로컬 모델과 인터페이스하기 위한 Rust의 다중 모드 메타 프레임워크입니다.candle-sampling : 캔들 샘플링 기술.gpt-from-scratch-rs : 장난감 문제에 대한 Candle API를 보여주는 YouTube의 Andrej Karpathy의 Let's build GPT 튜토리얼의 포트입니다.candle-einops : Python einops 라이브러리의 순수 Rust 구현입니다.atoma-infer : 효율적인 Attention 계산을 위한 FlashAttention2, 효율적인 KV 캐시 메모리 관리를 위한 PagedAttention 및 다중 GPU 지원을 활용하여 규모에 따른 빠른 추론을 위한 Rust 라이브러리입니다. OpenAI API와 호환됩니다.이 목록에 추가할 내용이 있으면 풀 요청을 제출하세요.
치트시트:
| PyTorch 사용 | 양초 사용하기 | |
|---|---|---|
| 창조 | torch.Tensor([[1, 2], [3, 4]]) | Tensor::new(&[[1f32, 2.], [3., 4.]], &Device::Cpu)? |
| 창조 | torch.zeros((2, 2)) | Tensor::zeros((2, 2), DType::F32, &Device::Cpu)? |
| 인덱싱 | tensor[:, :4] | tensor.i((.., ..4))? |
| 운영 | tensor.view((2, 2)) | tensor.reshape((2, 2))? |
| 운영 | a.matmul(b) | a.matmul(&b)? |
| 산수 | a + b | &a + &b |
| 장치 | tensor.to(device="cuda") | tensor.to_device(&Device::new_cuda(0)?)? |
| Dtype | tensor.to(dtype=torch.float16) | tensor.to_dtype(&DType::F16)? |
| 절약 | torch.save({"A": A}, "model.bin") | candle::safetensors::save(&HashMap::from([("A", A)]), "model.safetensors")? |
| 로드 중 | weights = torch.load("model.bin") | candle::safetensors::load("model.safetensors", &device) |
Tensor 구조체 정의Candle의 핵심 목표는 서버리스 추론을 가능하게 하는 것입니다. PyTorch와 같은 전체 기계 학습 프레임워크는 매우 크기 때문에 클러스터에서 인스턴스 생성 속도가 느려집니다. Candle을 사용하면 경량 바이너리를 배포할 수 있습니다.
둘째, Candle을 사용하면 프로덕션 워크로드에서 Python을 제거할 수 있습니다. Python 오버헤드는 성능을 심각하게 저하시킬 수 있으며 GIL은 골치 아픈 원인으로 악명 높습니다.
마지막으로 Rust는 멋지네요! 많은 HF 생태계에는 이미 safetensor 및 tokenizer와 같은 Rust 상자가 있습니다.
dfdx는 모양이 유형에 포함되는 강력한 상자입니다. 이렇게 하면 컴파일러가 즉시 모양 불일치에 대해 불평하게 하여 많은 골칫거리를 방지할 수 있습니다. 그러나 일부 기능에는 여전히 Nightly가 필요하며 Rust 전문가가 아닌 사람에게는 코드 작성이 다소 어려울 수 있다는 사실을 발견했습니다.
우리는 런타임 동안 다른 핵심 상자를 활용하고 기여하고 있으므로 두 상자가 서로 이익을 얻을 수 있기를 바랍니다.
burn은 워크로드에 가장 적합한 엔진을 선택할 수 있도록 여러 백엔드를 활용할 수 있는 일반 크레이트입니다.
tch-rs Rust의 토치 라이브러리에 바인딩합니다. 매우 다재다능하지만 전체 토치 라이브러리를 런타임에 가져옵니다. tch-rs 의 주요 기여자는 candle 개발에도 참여하고 있습니다.
mkl 또는 가속 기능을 사용하여 바이너리/테스트를 컴파일할 때 누락된 기호가 있는 경우(예: mkl의 경우) 다음과 같은 결과가 나타납니다.
= note: /usr/bin/ld: (....o): in function `blas::sgemm':
.../blas-0.22.0/src/lib.rs:1944: undefined reference to `sgemm_' collect2: error: ld returned 1 exit status
= note: some `extern` functions couldn't be found; some native libraries may need to be installed or have their path specified
= note: use the `-l` flag to specify native libraries to link
= note: use the `cargo:rustc-link-lib` directive to specify the native libraries to link with Cargo
또는 가속을 위해:
Undefined symbols for architecture arm64:
"_dgemm_", referenced from:
candle_core::accelerate::dgemm::h1b71a038552bcabe in libcandle_core...
"_sgemm_", referenced from:
candle_core::accelerate::sgemm::h2cf21c592cba3c47 in libcandle_core...
ld: symbol(s) not found for architecture arm64
이는 mkl 라이브러리를 활성화하는 데 필요한 링커 플래그가 누락되었기 때문일 수 있습니다. 바이너리 상단에 mkl에 대해 다음을 추가해 볼 수 있습니다.
extern crate intel_mkl_src ;또는 가속을 위해:
extern crate accelerate_src ; Error: request error: https://huggingface.co/meta-llama/Llama-2-7b-hf/resolve/main/tokenizer.json: status code 401
이는 LLaMA-v2 모델에 대한 권한이 없기 때문일 수 있습니다. 이 문제를 해결하려면 Huggingface-hub에 등록하고 LLaMA-v2 모델 조건을 수락하고 인증 토큰을 설정해야 합니다. 자세한 내용은 문제 #350을 참조하세요.
In file included from kernels/flash_fwd_launch_template.h:11:0,
from kernels/flash_fwd_hdim224_fp16_sm80.cu:5:
kernels/flash_fwd_kernel.h:8:10: fatal error: cute/algorithm/copy.hpp: No such file or directory
#include <cute/algorithm/copy.hpp>
^~~~~~~~~~~~~~~~~~~~~~~~~
compilation terminated.
Error: nvcc error while compiling:
cutlass는 git 하위 모듈로 제공되므로 다음 명령을 실행하여 제대로 체크인할 수 있습니다.
git submodule update --init /usr/include/c++/11/bits/std_function.h:530:146: error: parameter packs not expanded with ‘...’:
이것은 Cuda 컴파일러에 의해 유발된 gcc-11의 버그입니다. 이 문제를 해결하려면 지원되는 다른 gcc 버전(예: gcc-10)을 설치하고 NVCC_CCBIN 환경 변수에 컴파일러 경로를 지정합니다.
env NVCC_CCBIN=/usr/lib/gcc/x86_64-linux-gnu/10 cargo ...
Couldn't compile the test.
---- .candle-booksrcinferencehub.md - Using_the_hub::Using_in_a_real_model_ (line 50) stdout ----
error: linking with `link.exe` failed: exit code: 1181
//very long chain of linking
= note: LINK : fatal error LNK1181: cannot open input file 'windows.0.48.5.lib'
프로젝트 대상 외부에 있을 수 있는 모든 기본 라이브러리를 연결했는지 확인하세요. 예를 들어 mdbook 테스트를 실행하려면 다음을 실행해야 합니다.
mdbook test candle-book -L .targetdebugdeps `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.42.2lib `
-L native=$env:USERPROFILE.cargoregistrysrcindex.crates.io-6f17d22bba15001fwindows_x86_64_msvc-0.48.5lib
이는 /mnt/c 에서 로드되는 모델로 인해 발생할 수 있습니다. 자세한 내용은 stackoverflow에 있습니다.
캔들 오류 발생 시 역추적을 제공하도록 RUST_BACKTRACE=1 설정할 수 있습니다.
Err 값 on an Result::unwrap() called 오류가 발생하는 경우 value: LoadLibraryExW { source: Os { code: 126, kind: Uncategorized, message: "The specified module could not be found." } } 창에서. 복사를 수정하고 이 3개 파일의 이름을 바꾸려면(경로에 있는지 확인하세요). 경로는 cuda 버전에 따라 다릅니다. c:WindowsSystem32nvcuda.dll -> cuda.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincublas64_12.dll -> cublas.dll c:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.4bincurand64_10.dll -> curand.dll


