whisperX
3.1.1
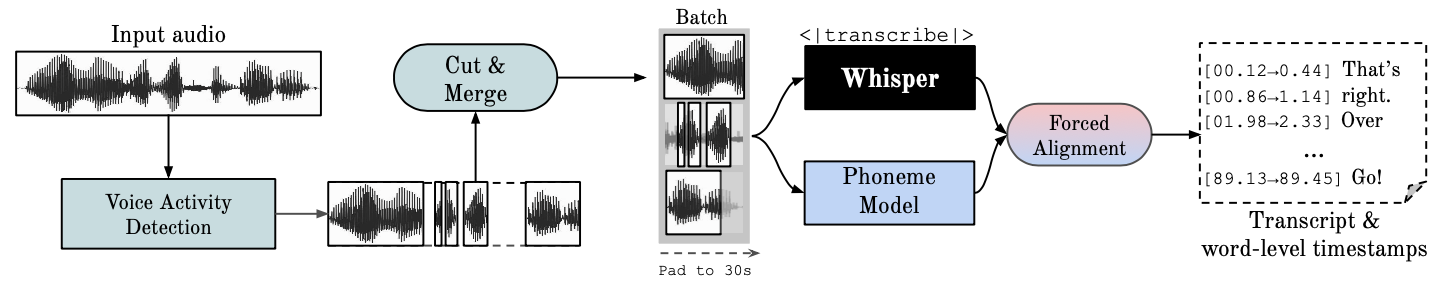
이 저장소는 단어 수준 타임스탬프 및 화자 분할을 통해 빠른 자동 음성 인식(대규모 v2에서 70x 실시간)을 제공합니다.
Whisper 는 OpenAI에서 개발한 ASR 모델로, 다양한 오디오의 대규모 데이터 세트를 학습했습니다. 매우 정확한 전사를 생성하지만 해당 타임스탬프는 단어 단위가 아닌 발화 수준에 있으며 몇 초 정도 부정확할 수 있습니다. OpenAI의 속삭임은 기본적으로 일괄 처리를 지원하지 않습니다.
음소 기반 ASR 한 단어를 다른 단어와 구별하는 가장 작은 음성 단위(예: "tap"의 요소 p)를 인식하도록 미세 조정된 모델 모음입니다. 널리 사용되는 예제 모델은 wav2vec2.0입니다.
강제 정렬은 자동으로 전화 수준 분할을 생성하기 위해 철자 표기를 오디오 녹음에 정렬하는 프로세스를 나타냅니다.
VAD(음성 활동 감지)는 사람의 음성 유무를 감지하는 것입니다.
화자 분할은 사람의 음성이 포함된 오디오 스트림을 각 화자의 신원에 따라 동종 세그먼트로 분할하는 프로세스입니다.
GPU를 실행하려면 NVIDIA 라이브러리 cuBLAS 11.x 및 cuDNN 8.x가 시스템에 설치되어 있어야 합니다. CTranslate2 문서를 참고하세요.
conda create --name whisperx python=3.10
conda activate whisperx
conda install pytorch==2.0.0 torchaudio==2.0.0 pytorch-cuda=11.8 -c pytorch -c nvidia
여기에서 다른 방법을 참조하세요.
pip install git+https://github.com/m-bain/whisperx.git
이미 설치된 경우 패키지를 최신 커밋으로 업데이트합니다.
pip install git+https://github.com/m-bain/whisperx.git --upgrade
이 패키지를 수정하려면 편집 가능 모드에서 복제하고 설치하십시오.
$ git clone https://github.com/m-bain/whisperX.git
$ cd whisperX
$ pip install -e .
ffmpeg, Rust 등을 설치해야 할 수도 있습니다. https://github.com/openai/whisper#setup에서 openAI 지침을 따르세요.
Speaker Diarization을 활성화 하려면 --hf_token 인수 뒤에 여기에서 생성할 수 있는 Hugging Face 액세스 토큰(읽기)을 포함하고 Segmentation 및 Speaker-Diarization-3.1(스피커를 사용하기로 선택한 경우) 모델에 대한 사용자 계약에 동의하세요. -Diarization 2.x, 대신 여기의 요구 사항을 따르세요.)
메모
2023년 10월 11일 현재, WhisperX의 pyannote/Speaker-Diarization-3.0 성능 저하와 관련된 알려진 문제가 있습니다. 이는 fast-whisper와 pyannote-audio 3.0.0 간의 종속성 충돌 때문입니다. 자세한 내용과 잠재적인 해결 방법은 이 문제를 참조하세요.
예제 세그먼트에서 속삭임을 실행합니다(기본 매개변수 사용, 작은 속삭임 사용) --highlight_words True 추가하여 .srt 파일의 단어 타이밍을 시각화합니다.
whisperx examples/sample01.wav
wav2vec2.0 대형에 강제 정렬하여 WhisperX를 사용한 결과:
이것을 많은 필사본이 동기화되지 않은 원래 속삭임과 비교해 보세요.
타임스탬프 정확도를 높이려면 더 높은 GPU 메모리를 사용하는 대신 더 큰 모델을 사용하십시오(더 큰 정렬 모델은 그다지 도움이 되지 않는 것으로 나타났습니다. 논문 참조).
whisperx examples/sample01.wav --model large-v2 --align_model WAV2VEC2_ASR_LARGE_LV60K_960H --batch_size 4
화자 ID로 대화 내용에 라벨을 지정하려면(알려진 경우 화자 수 설정, 예: --min_speakers 2 --max_speakers 2 ):
whisperx examples/sample01.wav --model large-v2 --diarize --highlight_words True
GPU 대신 CPU에서 실행하려면(Mac OS X에서 실행하려면):
whisperx examples/sample01.wav --compute_type int8
음소 ASR 정렬 모델은 언어별로 다릅니다 . 테스트된 언어의 경우 이러한 모델은 torchaudio 파이프라인 또는 Huggingface에서 자동으로 선택됩니다. --language 코드를 전달하고 속삭임 --model large 사용하세요.
현재 기본 모델은 {en, fr, de, es, it, ja, zh, nl, uk, pt} 에 제공됩니다. 감지된 언어가 이 목록에 없으면 허깅페이스 모델 허브에서 음소 기반 ASR 모델을 찾아 데이터에서 테스트해야 합니다.
whisperx --model large-v2 --language de examples/sample_de_01.wav
여기에서 다른 언어로 된 더 많은 예를 확인하세요.
import whisperx
import gc
device = "cuda"
audio_file = "audio.mp3"
batch_size = 16 # reduce if low on GPU mem
compute_type = "float16" # change to "int8" if low on GPU mem (may reduce accuracy)
# 1. Transcribe with original whisper (batched)
model = whisperx . load_model ( "large-v2" , device , compute_type = compute_type )
# save model to local path (optional)
# model_dir = "/path/"
# model = whisperx.load_model("large-v2", device, compute_type=compute_type, download_root=model_dir)
audio = whisperx . load_audio ( audio_file )
result = model . transcribe ( audio , batch_size = batch_size )
print ( result [ "segments" ]) # before alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model
# 2. Align whisper output
model_a , metadata = whisperx . load_align_model ( language_code = result [ "language" ], device = device )
result = whisperx . align ( result [ "segments" ], model_a , metadata , audio , device , return_char_alignments = False )
print ( result [ "segments" ]) # after alignment
# delete model if low on GPU resources
# import gc; gc.collect(); torch.cuda.empty_cache(); del model_a
# 3. Assign speaker labels
diarize_model = whisperx . DiarizationPipeline ( use_auth_token = YOUR_HF_TOKEN , device = device )
# add min/max number of speakers if known
diarize_segments = diarize_model ( audio )
# diarize_model(audio, min_speakers=min_speakers, max_speakers=max_speakers)
result = whisperx . assign_word_speakers ( diarize_segments , result )
print ( diarize_segments )
print ( result [ "segments" ]) # segments are now assigned speaker IDs 자신의 GPU에 액세스할 수 없다면 위의 링크를 사용하여 WhisperX를 사용해 보세요.
배치 및 정렬, VAD 효과, 선택한 정렬 모델에 대한 자세한 내용은 사전 인쇄 용지를 참조하십시오.
GPU 메모리 요구 사항을 줄이려면 다음 중 하나를 시도해 보십시오(2. 및 3.은 품질에 영향을 줄 수 있음).
--batch_size 4--model base--compute_type int8 사용openai의 속삭임과의 전사 차이점:
--without_timestamps True . 이는 일괄 처리에서 샘플당 1개의 전달 패스를 보장합니다. 그러나 이로 인해 기본 속삭임 출력에 불일치가 발생할 수 있습니다.--condition_on_prev_text 기본적으로 False 로 설정됩니다(환각 감소). 다국어 사용자인 경우 이 프로젝트에 기여할 수 있는 주요 방법은 Huggingface에서 음소 모델을 찾고(또는 직접 훈련) 대상 언어에 대한 음성에서 테스트하는 것입니다. 결과가 좋아 보이면 끌어오기 요청과 성공을 보여주는 몇 가지 예시를 보내세요.
이미 원래 연구 범위에서 벗어나 있기 때문에 이 프로젝트를 계속 진행하려면 버그 찾기 및 풀 요청도 높이 평가됩니다.
다국어 초기화
언어 감지를 기반으로 자동 정렬 모델 선택
파이썬 사용법
화자 분할 통합
낮은 GPU 메모리 리소스를 위한 모델 플러시
더 빠른 속삭임 백엔드
max-line 등을 추가하세요. (openai의 속삭임 utils.py)을 참조하세요.
문장 수준 세그먼트(nltk 도구 상자)
정렬 논리 개선
분할 및 단어 강조 표시로 예제 업데이트
자막 .ass 출력 <- 다시 가져오기(v3에서는 제거됨)
벤치마킹 코드 추가(spd/WER 및 단어 분할을 위한 TEDLIUM)
대체 VAD 옵션으로 silero-vad 허용
분할(단어 수준)을 개선합니다. 처음 생각보다 어렵네요...
문의사항은 [email protected]으로 연락주세요.
이 작업과 나의 박사 학위는 VGG(Visual Geometry Group)와 옥스퍼드 대학교의 지원을 받습니다.
물론 이것은 openAI의 속삭임에 기초한 것입니다. 강제 정렬에 대한 PyTorch 튜토리얼에서 중요한 정렬 코드를 차용하고 멋진 pyannote VAD / Diarization https://github.com/pyannote/pyannote-audio를 사용합니다.
[pyannote audio][https://github.com/pyannote/pyannote-audio]의 귀중한 VAD 및 분할 모델
더 빠른 속삭임과 CTranslate2를 통한 훌륭한 백엔드
본 사업에 금전적인 지원을 해주신 분들
마지막으로, 이 프로젝트를 계속 진행하고 버그를 식별해 준 OS 기여자들에게 감사드립니다.
@article { bain2022whisperx ,
title = { WhisperX: Time-Accurate Speech Transcription of Long-Form Audio } ,
author = { Bain, Max and Huh, Jaesung and Han, Tengda and Zisserman, Andrew } ,
journal = { INTERSPEECH 2023 } ,
year = { 2023 }
}

