LARS
v2.0-beta8:

LARS는 LLM(Large Language Models)을 장치에서 로컬로 실행하고, 자신의 문서를 업로드하고, LLM이 업로드된 콘텐츠로 응답을 근거로 삼는 대화에 참여할 수 있게 해주는 애플리케이션입니다. 이러한 접지는 정확도를 높이고 AI에서 생성된 부정확성 또는 "환각"이라는 일반적인 문제를 줄이는 데 도움이 됩니다. 이 기술은 일반적으로 "검색 증강 생성(Retrieval Augmented Generation)" 또는 RAG로 알려져 있습니다.
LLM을 로컬로 실행하기 위한 많은 데스크톱 응용 프로그램이 있으며 LARS는 궁극적인 오픈 소스 RAG 중심 LLM 응용 프로그램을 목표로 합니다. 이를 위해 LARS는 모든 응답에 상세한 인용을 추가하고 특정 문서 이름, 페이지 번호, 텍스트 강조 표시, 질문과 관련된 이미지를 제공하고 심지어 문서 리더를 바로 제공함으로써 RAG의 개념을 훨씬 더 발전시킵니다. 응답창. 모든 응답에 대해 모든 인용이 항상 존재하는 것은 아니지만, 모든 RAG 응답에 대해 적어도 일부 인용 조합이 표시되도록 하는 것이 아이디어이며 일반적으로 그런 경우입니다.
LARS 기능 시연 영상
Python v3.10.x 이상: https://www.python.org/downloads/
파이토치:
GPU를 사용하여 LLM을 실행할 계획이라면 설정에 맞게 GPU 드라이버와 CUDA/ROCm 툴킷을 설치한 다음 아래 PyTorch 설정을 진행하세요.
귀하의 시스템에 적합한 PyTorch 버전을 다운로드하여 설치하십시오: https://pytorch.org/get-started/locally/
저장소를 복제합니다.
git clone https://github.com/abgulati/LARS
cd LARS
GitHub Settings -> Developer settings (located on the bottom left!) -> Personal access tokensPython 종속성을 설치합니다.
PIP를 통한 Windows:
pip install -r .requirements.txt
PIP를 통한 Linux:
pip3 install -r ./requirements.txt
Azure에 대한 참고 사항: 일부 필수 Azure 라이브러리는 MacOS 플랫폼에서 사용할 수 없습니다! 따라서 다음 라이브러리를 제외하고 MacOS에는 별도의 요구 사항 파일이 포함됩니다.
맥OS:
pip3 install -r ./requirements_mac.txt
목차로 돌아가기
설치 후 다음을 사용하여 LARS를 실행하십시오.
cd web_app
python app.py # Use 'python3' on Linux/macOS
브라우저에서 http://localhost:5000/ 으로 이동하세요.
LARS에 필요한 모든 애플리케이션 디렉토리가 이제 디스크에 생성됩니다.
HF-Waitress 서버가 자동으로 시작되고 처음 실행 시 LLM(Microsoft Phi-3-Mini-Instruct-44)을 다운로드합니다. 이는 인터넷 연결 속도에 따라 다소 시간이 걸릴 수 있습니다.
첫 번째 쿼리에서는 HuggingFace Hub에서 임베딩 모델(all-mpnet-base-v2)이 다운로드되며, 이 작업에는 짧은 시간이 걸립니다.
목차로 돌아가기
Windows의 경우:
공식 사이트 - "Visual Studio용 도구"에서 Microsoft Visual Studio Build Tools 2022를 다운로드하세요.
참고: 위 항목을 설치할 때 다음 구성 요소를 선택했는지 확인하십시오.
Desktop development with C++
# Then from the "Optional" category on the right, make sure to select the following:
MSVC C++ x64/x86 build tools
C++ CMake tools for Windows
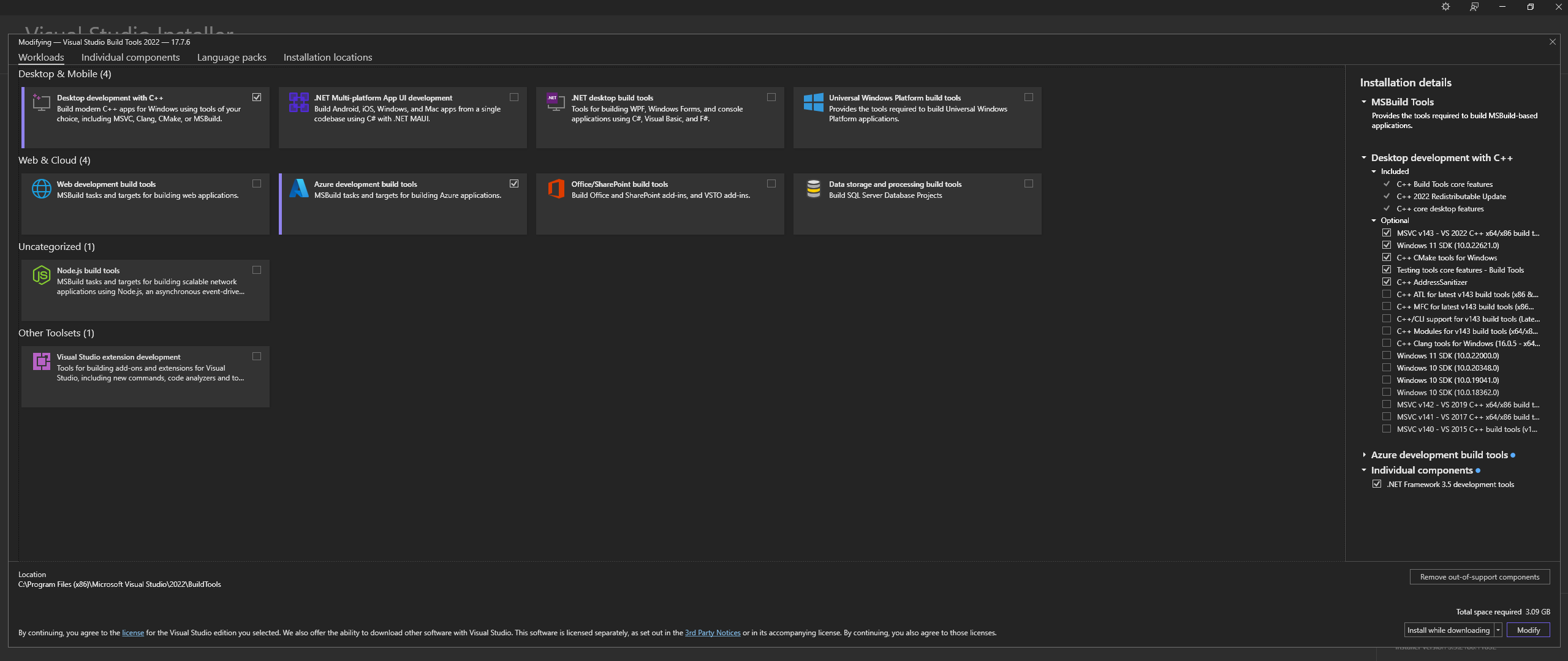
Desktop development with C++ 과 MSVC and C++ CMake 옵션이 선택되었는지 확인하세요.Linux(Ubuntu 및 Debian 기반)에서는 다음 패키지를 설치합니다.
sudo apt-get update
sudo apt-get install -y software-properties-common build-essential libffi-dev libssl-dev cmake
공식 저장소에서 다운로드:
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp
공식 사이트에서 Windows에 CMAKE를 설치하세요.
C:Program FilesCMakebinCMAKE를 사용하여 llama.cpp를 빌드합니다.
참고: 더 빠른 컴파일을 위해 -j 인수를 추가하여 여러 작업을 병렬로 실행하세요. 예를 들어 cmake --build build --config Release -j 8 8개의 작업을 병렬로 실행합니다.
CUDA로 빌드:
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="52;61;70;75;80;86"
cmake --build build --config Release
cmake -B build
cmake --build build --config Release
CMake -B build 실행을 시도할 때 문제가 발생하는 경우 아래의 광범위한 CMake 설치 문제 해결 단계를 확인하세요.
경로에 추가:
path_to_cloned_repollama.cppbuildbinRelease
터미널을 통해 설치를 확인합니다.
llama-server
Nvidia GPU 드라이버 설치
Nvidia CUDA Toolkit 설치 - LARS는 v12.2 및 v12.4로 구축 및 테스트되었습니다.
터미널을 통해 설치를 확인합니다.
nvcc -V
nvidia-smi
CMAKE-CUDA 수정(매우 중요!):
다음 디렉터리에서 4개 파일을 모두 복사합니다.
C:Program FilesNVIDIA GPU Computing ToolkitCUDAv12.2extrasvisual_studio_integrationMSBuildExtensions
다음 디렉터리에 붙여넣습니다.
C:Program Files (x86)Microsoft Visual Studio2022BuildToolsMSBuildMicrosoftVCv170BuildCustomizations
이는 선택 사항이지만 매우 권장되는 종속성입니다. 이 설정이 완료되지 않으면 PDF만 지원됩니다.
윈도우:
공식 사이트에서 다운로드
다음 중 하나를 통해 PATH에 추가합니다.
고급 시스템 설정 -> 환경 변수 -> 시스템 변수 -> PATH 변수 편집 -> 아래 추가(설치 위치에 따라 변경):
C:Program FilesLibreOfficeprogram
또는 PowerShell을 통해:
Set PATH=%PATH%;C:Program FilesLibreOfficeprogram
Ubuntu 및 Debian 기반 Linux - 공식 사이트에서 다운로드하거나 터미널을 통해 설치:
sudo apt-get update
sudo apt-get install -y libreoffice
Fedora 및 기타 RPM 기반 배포판 - 공식 사이트에서 다운로드하거나 터미널을 통해 설치:
sudo dnf update
sudo dnf install libreoffice
MacOS - 공식 사이트에서 다운로드하거나 Homebrew를 통해 설치:
brew install --cask libreoffice
설치 확인:
Windows 및 MacOS: LibreOffice 애플리케이션 실행
Linux에서 터미널을 통해:
libreoffice --version
LARS는 pdf2image Python 라이브러리를 활용하여 문서의 각 페이지를 OCR에 필요한 이미지로 변환합니다. 이 라이브러리는 본질적으로 변환 프로세스를 처리하는 Poppler 유틸리티를 둘러싼 래퍼입니다.
윈도우:
공식 저장소에서 다운로드
다음 중 하나를 통해 PATH에 추가합니다.
고급 시스템 설정 -> 환경 변수 -> 시스템 변수 -> PATH 변수 편집 -> 아래 추가(설치 위치에 따라 변경):
path_to_installationpoppler_versionLibrarybin
또는 PowerShell을 통해:
Set PATH=%PATH%;path_to_installationpoppler_versionLibrarybin
리눅스:
sudo apt-get update
sudo apt-get install -y poppler-utils wget
이는 선택적 종속성입니다. Tesseract-OCR은 LARS에서 적극적으로 사용되지 않지만 이를 사용하는 방법은 소스 코드에 있습니다.
윈도우:
UB-Mannheim을 통해 Windows용 Tesseract-OCR을 다운로드하세요.
다음 중 하나를 통해 PATH에 추가합니다.
고급 시스템 설정 -> 환경 변수 -> 시스템 변수 -> PATH 변수 편집 -> 아래 추가(설치 위치에 따라 변경):
C:Program FilesTesseract-OCR
또는 PowerShell을 통해:
Set PATH=%PATH%;C:Program FilesTesseract-OCR
목차로 돌아가기
LARS는 Python v3.11.x로 구축 및 테스트되었습니다.
Windows에 Python v3.11.x를 설치합니다.
공식 사이트에서 v3.11.9를 다운로드하세요.
설치하는 동안 "PATH에 Python 3.11 추가"를 선택하거나 나중에 다음을 통해 수동으로 추가하십시오.
고급 시스템 설정 -> 환경 변수 -> 시스템 변수 -> PATH 변수 편집 -> 아래 추가(설치 위치에 따라 변경):
C:Usersuser_nameAppDataLocalProgramsPythonPython311
또는 PowerShell을 통해:
Set PATH=%PATH%;C:Usersuser_nameAppDataLocalProgramsPythonPython311
Linux(Ubuntu 및 Debian 기반)에 Python v3.11.x를 설치합니다.
sudo add-apt-repository ppa:deadsnakes/ppa -y
sudo apt-get update
sudo apt-get install -y python3.11 python3.11-venv python3.11-dev
sudo python3.11 -m ensurepip
터미널을 통해 설치를 확인합니다.
python3 --version
pip install 에서 오류가 발생하면 다음을 시도하십시오:
버전 번호 제거:
==version.number 세그먼트를 제거합니다. 예를 들면 다음과 같습니다.urllib3==2.0.4urllib3Python 가상 환경을 만들고 사용합니다.
다른 Python 프로젝트와의 충돌을 피하기 위해 가상 환경을 사용하는 것이 좋습니다.
윈도우:
Python 가상 환경(venv)을 만듭니다.
python -m venv larsenv
venv를 활성화하고 이후에 사용합니다.
.larsenvScriptsactivate
완료되면 venv를 비활성화합니다.
deactivate
리눅스와 맥OS:
Python 가상 환경(venv)을 만듭니다.
python3 -m venv larsenv
venv를 활성화하고 이후에 사용합니다.
source larsenv/bin/activate
완료되면 venv를 비활성화합니다.
deactivate
문제가 지속되면 LARS GitHub 저장소에서 문제를 열어 지원을 받는 것을 고려해 보세요.
CMake nmake failed 오류가 발생하는 경우: 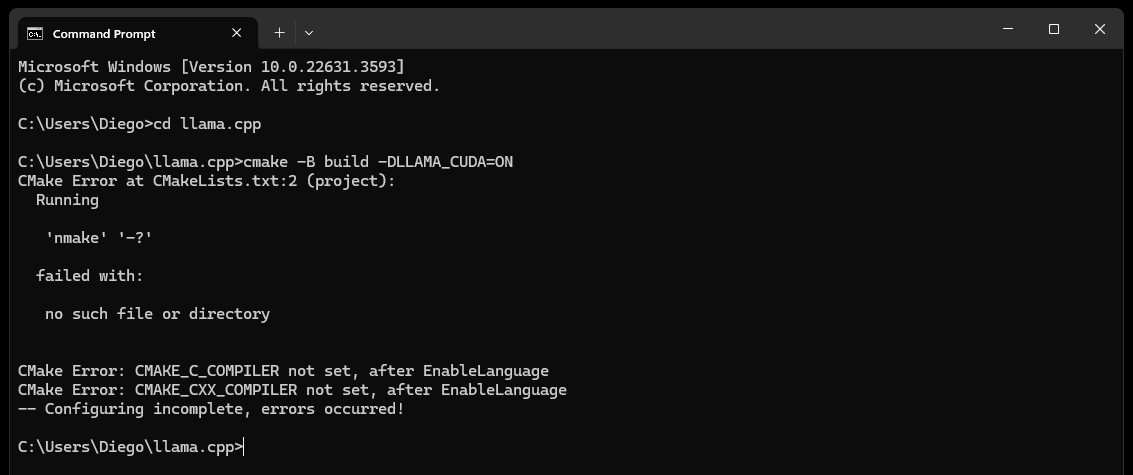
이는 일반적으로 CMake가 Microsoft Visual Studio 빌드 도구의 일부인 nmake 도구를 찾을 수 없기 때문에 Microsoft Visual Studio 빌드 도구에 문제가 있음을 나타냅니다. 문제를 해결하려면 아래 단계를 시도해 보세요.
Visual Studio 빌드 도구가 설치되어 있는지 확인하세요.
nmake를 포함하여 Visual Studio 빌드 도구가 설치되어 있는지 확인하세요. Desktop development with C++ 과 MSVC and C++ CMake 옵션을 선택하여 Visual Studio 설치 관리자를 통해 이러한 도구를 설치할 수 있습니다.
종속성 섹션의 0단계, 특히 해당 스크린샷을 확인하세요.
환경 변수를 확인하십시오.
C:Program Files (x86)Microsoft Visual Studio2019CommunityVCAuxiliaryBuild
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7IDE
C:Program Files (x86)Microsoft Visual Studio2019CommunityCommon7Tools
개발자 명령 프롬프트 사용:
필요한 환경 변수를 설정하는 "Visual Studio용 개발자 명령 프롬프트"를 엽니다.
Visual Studio의 시작 메뉴에서 이 메시지를 찾을 수 있습니다.
CMake 생성기 설정:
cmake -G "NMake Makefiles" -B build -DLLAMA_CUDA=ON
문제가 지속되면 LARS GitHub 저장소에서 문제를 열어 지원을 받는 것을 고려해 보세요.
결국(약 60초 후) 페이지에 오류를 나타내는 경고가 표시됩니다.
Failed to start llama.cpp local-server
이는 첫 실행이 완료되었고 모든 앱 디렉터리가 생성되었지만 models 디렉터리에 LLM이 없으며 이제 해당 디렉터리로 이동할 수 있음을 나타냅니다.
LLM(llama.cpp에서 지원하는 모든 파일 형식, 바람직하게는 GGUF)을 새로 생성된 models 디렉터리로 이동합니다. 기본적으로 다음 위치에 있습니다.
C:/web_app_storage/models/app/storage/models/app/models 위의 적절한 models 디렉토리에 LLM을 배치한 후 http://localhost:5000/ 새로 고치십시오.
약 60초 후에 Failed to start llama.cpp local-server 라는 오류 경고가 다시 한 번 표시됩니다.
이제 LARS Settings 메뉴에서 LLM을 선택해야 하기 때문입니다.
경고를 수락하고 오른쪽 상단의 Settings 톱니바퀴 아이콘을 클릭하세요.
LLM Selection 탭의 해당 드롭다운에서 LLM과 적절한 프롬프트 템플릿 형식을 선택하세요.
GPU 옵션, Context-Length 및 선택적으로 선택한 LLM에 대한 토큰 생성 제한( Maximum tokens to predict )을 올바르게 설정하려면 고급 설정을 수정하세요.
Save 누르고 자동 새로고침이 실행되지 않으면 페이지를 수동으로 새로고침하세요.
모든 단계가 올바르게 실행되면 이제 최초 설정이 완료되고 LARS를 사용할 수 있습니다.
LARS는 이후 사용을 위해 LLM 설정도 기억합니다.
목차로 돌아가기
지원되는 문서 형식:
종속성 섹션의 4단계에 설명된 대로 LibreOffice를 설치하고 PATH에 추가한 경우 다음 형식이 지원됩니다.
LibreOffice가 설정되어 있지 않으면 PDF만 지원됩니다.
텍스트 추출을 위한 OCR 옵션:
LARS는 다양한 문서 유형과 품질을 수용하면서 문서에서 텍스트를 추출하는 세 가지 방법을 제공합니다.
로컬 텍스트 추출: 스캔되지 않은 PDF에서 효율적인 텍스트 추출을 위해 PyPDF2를 사용합니다. 높은 정확도가 중요하지 않거나 완전히 로컬 처리가 필요한 경우 빠른 처리에 이상적입니다.
Azure ComputerVision OCR - 텍스트 추출 정확도를 향상하고 스캔된 문서를 지원합니다. 표준 문서 레이아웃을 처리하는 데 유용합니다. 초기 평가판 및 소량 사용에 적합한 무료 등급을 제공하며 최대 트랜잭션 수는 월 5,000건, 분당 트랜잭션 20건으로 제한됩니다.
Azure AI Document Intelligence OCR - 테이블과 같은 복잡한 구조의 문서에 가장 적합합니다. LARS의 사용자 정의 파서는 추출 프로세스를 최적화합니다.
참고:
Azure OCR 옵션은 대부분의 경우 API 비용이 발생하며 LARS와 함께 번들로 제공되지 않습니다.
위에 링크된 대로 ComputerVision OCR에 대한 제한된 무료 계층을 사용할 수 있습니다. 이 서비스는 전체적으로 저렴하지만 속도가 느리고 비표준 문서 레이아웃(A4 등 제외)에서는 작동하지 않을 수 있습니다.
OCR 옵션을 선택할 때 문서 유형과 정확성 요구 사항을 고려하십시오.
LLM:
현재는 로컬 LLM만 지원됩니다.
Settings 메뉴는 고급 사용자가 LLM Selection 탭을 통해 LLM을 구성하고 변경할 수 있는 다양한 옵션을 제공합니다.
llama.cpp를 사용하는 경우 참고 사항: 매우 중요: 실행 중인 LLM에 적합한 프롬프트 템플릿 형식을 선택하세요.
다음 프롬프트 템플릿 형식에 대해 훈련된 LLM은 현재 llama.cpp를 통해 지원됩니다.
Advanced Settings 통해 핵심 구성 설정 조정(LLM 다시 로드 및 페이지 새로 고침 트리거):
언제든지 응답 동작을 변경하려면 설정을 조정하세요.
임베딩 모델 및 벡터 데이터베이스:
LARS에는 4가지 임베딩 모델이 제공됩니다.
Azure-OpenAI 임베딩을 제외하고 다른 모든 모델은 완전히 로컬에서 무료로 실행됩니다. 처음 실행 시 이러한 모델은 HuggingFace Hub에서 다운로드됩니다. 이는 일회성 다운로드이며 이후에 로컬로 제공됩니다.
사용자는 Settings 메뉴의 VectorDB & Embedding Models 탭을 통해 언제든지 이러한 임베딩 모델 간에 전환할 수 있습니다.
문서 로드 테이블: Settings 메뉴에는 연결된 벡터 데이터베이스에 포함된 문서 목록을 표시하는 선택된 임베딩 모델에 대한 테이블이 표시됩니다. 문서가 여러 번 로드되면 이 표에 여러 항목이 포함되어 문제를 디버깅하는 데 유용할 수 있습니다.
VectorDB 지우기: Reset 버튼을 사용하고 확인을 제공하여 선택한 벡터 데이터베이스를 지웁니다. 그러면 선택한 임베딩 모델에 대해 디스크에 새로운 벡터DB가 생성됩니다. 이전 벡터DB는 여전히 보존되며 config.json 파일을 수동으로 수정하여 되돌릴 수 있습니다.
시스템 프롬프트 편집:
시스템 프롬프트는 전체 대화에 대해 LLM에 대한 지침 역할을 합니다.
LARS는 System Prompt 탭의 드롭다운에서 Custom 옵션을 선택하여 Settings 메뉴를 통해 시스템 프롬프트를 편집할 수 있는 기능을 사용자에게 제공합니다.
시스템 프롬프트를 변경하면 새 채팅이 시작됩니다.
RAG 강제 활성화/비활성화:
사용자는 필요할 때마다 Settings 메뉴를 통해 RAG(검색 증강 생성 – LLM 생성 응답을 개선하기 위해 문서의 콘텐츠 사용)를 강제로 활성화 또는 비활성화할 수 있습니다.
이는 두 시나리오 모두에서 LLM 응답을 평가하는 데 유용한 경우가 많습니다.
강제 비활성화하면 기여 분석 기능도 꺼집니다.
NLP를 사용하여 RAG를 수행해야 하는 시기와 수행하지 말아야 하는 시기를 결정하는 기본 설정은 권장 옵션입니다.
이 설정은 언제든지 변경할 수 있습니다.
채팅 기록:
왼쪽 상단의 채팅 기록 메뉴를 사용하여 이전 대화를 탐색하고 재개하세요.
매우 중요: 이전 대화를 재개할 때 프롬프트 템플릿 불일치에 주의하세요! 오른쪽 상단에 있는 Information 아이콘을 사용하여 이전 대화에 사용된 LLM과 현재 사용 중인 LLM이 모두 동일한 프롬프트 템플릿 형식을 기반으로 하는지 확인하세요!
사용자 평가:
사용자는 언제든지 각 응답을 5점 척도로 평가할 수 있습니다.
평가 데이터는 앱 디렉터리에 있는 chat-history.db SQLite3 데이터베이스에 저장됩니다.
C:/web_app_storage/app/storage/app평가 데이터는 워크플로우 도구를 평가하고 개선하는 데 매우 중요합니다.
해야 할 일과 하지 말아야 할 일:
목차로 돌아가기
채팅이 잘못되거나 이상한 응답이 생성되면 왼쪽 상단 메뉴를 통해 New Chat 시작해 보세요.
또는 페이지를 새로 고쳐 새 채팅을 시작하세요.
인용이나 RAG 성능에 문제가 있는 경우 위 일반 사용자 가이드의 4단계에 설명된 대로 벡터DB를 재설정해 보세요.
애플리케이션 문제가 발생하고 새 채팅을 시작하거나 LARS를 다시 시작해도 해결되지 않는 경우 아래 단계에 따라 config.json 파일을 삭제해 보세요.
CTRL+C 로 Python 프로그램을 종료하여 LARS 앱 서버를 종료합니다.LARS/web_app ( app.py 와 동일한 디렉터리)에 있는 config.json 파일을 백업하고 삭제합니다.위의 일반 사용자 가이드의 4단계에 설명된 대로 VectorDB를 재설정해도 해결되지 않는 심각한 데이터 및 인용 문제의 경우 다음 단계를 수행하십시오.
CTRL+C 로 Python 프로그램을 종료하여 LARS 앱 서버를 종료합니다.C:/web_app_storage/app/storage/app문제가 지속되면 LARS GitHub 저장소에서 문제를 열어 지원을 받는 것을 고려해 보세요.
목차로 돌아가기
LARS는 아래와 같이 두 개의 별도 이미지를 통해 Docker 컨테이너 배포 환경에 맞게 조정되었습니다.
전자는 배포가 더 간단하다는 점에서 둘 다 요구 사항이 다르지만 병목 현상을 일으키는 CPU 및 DDR 메모리로 인해 추론 성능이 훨씬 느려집니다.
명시적으로 필요하지는 않지만 Docker 컨테이너에 대한 경험과 컨테이너화 및 가상화 개념에 대한 지식이 이 섹션에서 매우 도움이 될 것입니다!
두 가지 모두에 대한 일반적인 설정 단계부터 시작합니다.
도커 설치
CPU는 가상화를 지원해야 하며 시스템의 BIOS/UEFI에서 활성화되어야 합니다.
Docker 데스크탑 다운로드 및 설치
Windows의 경우 Linux용 Windows 하위 시스템이 아직 없으면 설치해야 할 수도 있습니다. 이렇게 하려면 관리자로 PowerShell을 열고 다음을 실행합니다.
wsl --install
Docker Desktop이 실행 중인지 확인한 후 명령 프롬프트/터미널을 열고 다음 명령을 실행하여 Docker가 올바르게 설치되어 실행 중인지 확인하세요.
docker ps
런타임에 LARS 컨테이너에 연결될 Docker 스토리지 볼륨을 만듭니다.
LARS 컨테이너와 함께 사용할 스토리지 볼륨을 생성하면 LARS 컨테이너를 최신 버전으로 업그레이드하거나 모든 설정, 채팅 기록 및 벡터 데이터베이스를 원활하게 유지하면서 CPU 및 GPU 컨테이너 변형 간에 전환할 수 있으므로 매우 유리합니다. .
명령 프롬프트/터미널에서 다음 명령을 실행합니다.
docker volume create lars_storage_volue
이 볼륨은 나중에 런타임 시 LARS 컨테이너에 연결됩니다. 지금은 아래 단계에 따라 LARS 이미지 빌드를 진행하세요.
명령 프롬프트/터미널에서 다음 명령을 실행합니다.
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized
docker build -t lars-no-gpu .
# Once the build is complete, run the container:
docker run -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-no-gpu
완료되면 브라우저에서 http://localhost:5000/ 으로 이동하여 첫 실행 단계 및 사용자 가이드의 나머지 부분을 따르세요.
문제 해결 섹션은 Container-LARS에도 적용됩니다.
요구사항(Docker에 추가):
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Linux의 경우 위의 설정이 모두 완료되었으므로 다음 단계를 건너뛰고 바로 빌드로 이동하여 아래의 추가 단계를 실행하세요.
Windows의 경우, 그리고 Docker에서 Nvidia GPU 컨테이너를 처음 실행하는 경우, 꽤 즐거운 시간이 될 것이므로 끈을 묶으십시오(좋아하는 음료 또는 세 가지를 적극 권장합니다!).
극도의 중복 위험이 있으므로 진행하기 전에 다음 종속성이 있는지 확인하십시오.
Compatible Nvidia GPU(s)
Nvidia GPU drivers
Nvidia CUDA Toolkit v12.2
Docker Desktop
Windows Subsystem for Linux (WSL)
확실하지 않은 경우 위의 Nvidia CUDA 종속성 섹션 및 Docker 설정 섹션을 참조하세요.
위의 내용이 있고 설정되어 있으면 계속 진행할 수 있습니다.
PC에서 Microsoft Store 앱을 열고 Ubuntu 22.04.3 LTS를 다운로드하여 설치합니다(dockerfile의 2번째 줄에 있는 버전과 일치해야 함).
예, 위 내용을 읽으셨습니다. Microsoft 스토어 앱에서 Ubuntu를 다운로드하여 설치하세요. 아래 스크린샷을 참조하세요.
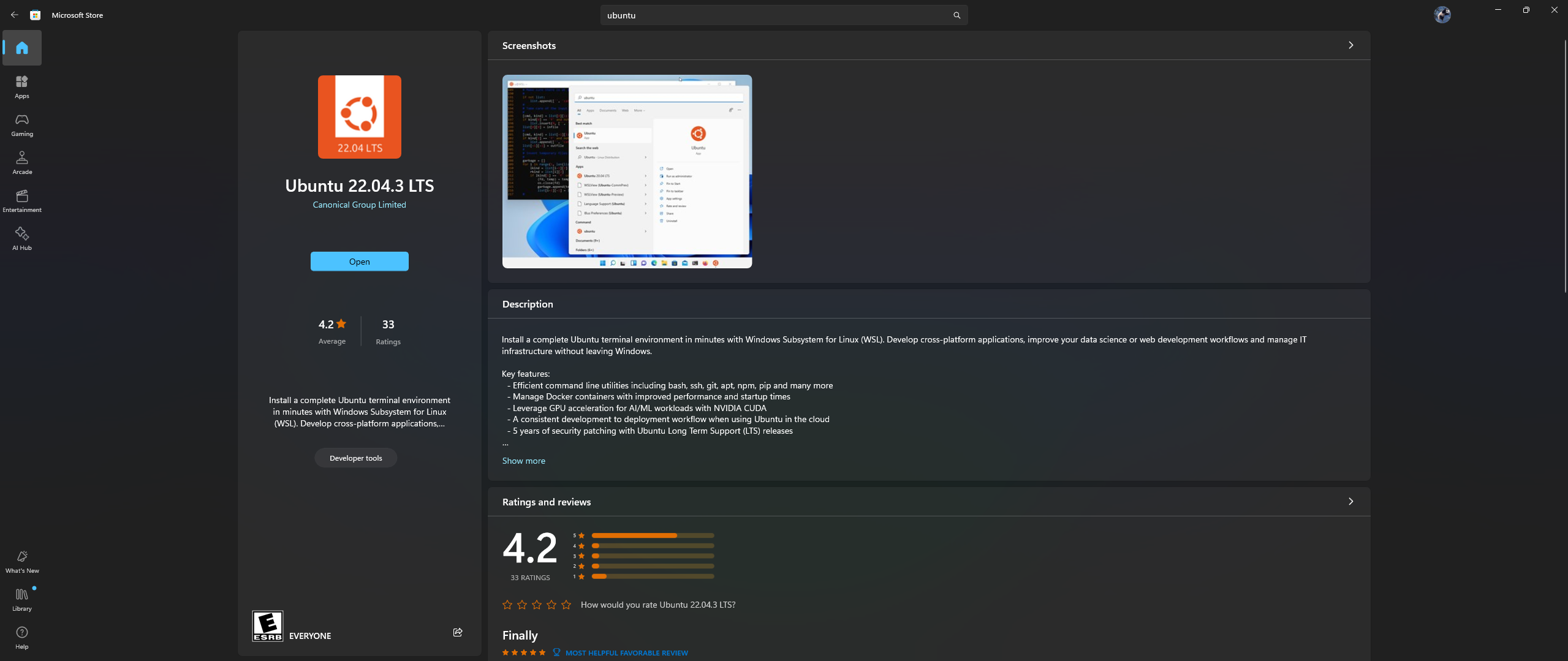
이제 Ubuntu 내에 Nvidia Container Toolkit을 설치할 차례입니다. 설치하려면 아래 단계를 따르세요.
위 설치가 완료된 후 시작 메뉴에서 Ubuntu 검색하여 Windows에서 Ubuntu 쉘을 시작합니다.
열리는 Ubuntu 명령줄에서 다음 단계를 수행합니다.
프로덕션 저장소를 구성합니다.
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list |
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' |
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
저장소에서 패키지 목록을 업데이트하고 Nvidia 컨테이너 툴킷 패키지를 설치합니다.
sudo apt-get update && apt-get install -y nvidia-container-toolkit
Docker가 Nvidia 컨테이너 런타임을 사용할 수 있도록 /etc/docker/daemon.json 파일을 수정하는 nvidia-ctk 명령을 사용하여 컨테이너 런타임을 구성합니다.
sudo nvidia-ctk runtime configure --runtime=docker
Docker 데몬을 다시 시작합니다.
sudo systemctl restart docker
이제 Ubuntu 설정이 완료되었습니다. WSL 및 Docker 통합을 완료할 시간입니다.
새 PowerShell 창을 열고 이 Ubuntu 설치를 WSL 기본값으로 설정합니다.
wsl --list
wsl --set-default Ubuntu-22.04 # if not already marked as Default
Docker Desktop -> Settings -> Resources -> WSL Integration -> 기본 및 Ubuntu 22.04 통합 확인으로 이동합니다. 아래 스크린샷을 참조하세요.
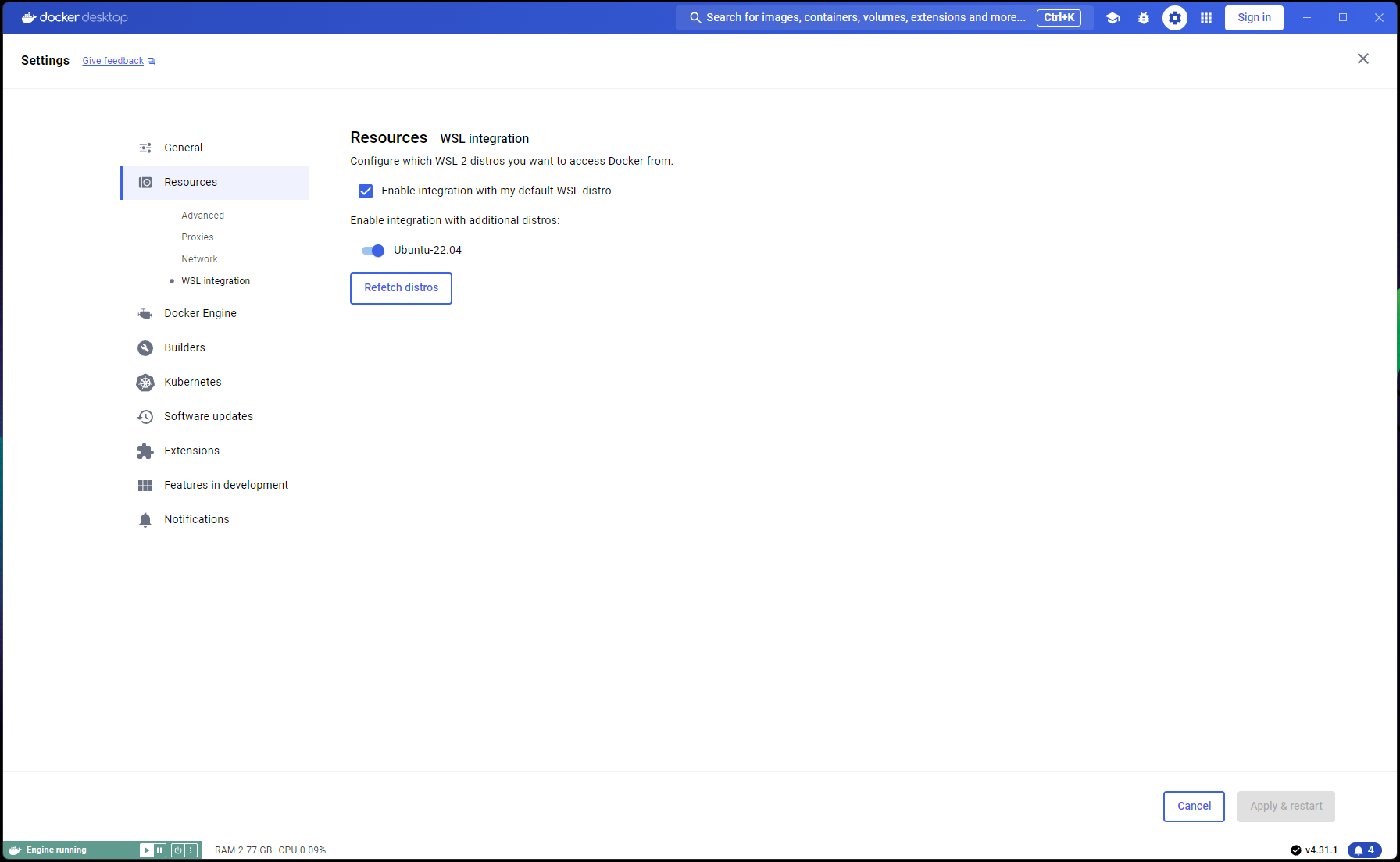
이제 모든 작업이 올바르게 완료되었으면 컨테이너를 빌드하고 실행할 준비가 되었습니다!
명령 프롬프트/터미널에서 다음 명령을 실행합니다.
git clone https://github.com/abgulati/LARS # skip if already done
cd LARS # skip if already done
cd dockerized_nvidia_cuda_gpu
docker build -t lars-nvcuda .
# Once the build is complete, run the container:
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda
완료되면 브라우저에서 http://localhost:5000/ 으로 이동하여 첫 실행 단계 및 사용자 가이드의 나머지 부분을 따르세요.
문제 해결 섹션은 Container-LARS에도 적용됩니다.
네트워크 관련 오류, 특히 컨테이너를 구축할 때 사용할 수 없는 패키지 리포지토리와 관련된 오류가 발생하는 경우 이는 종종 방화벽 문제와 관련된 최종 네트워킹 문제입니다.
Windows에서는 Control PanelSystem and SecurityWindows Defender FirewallAllowed apps 로 이동하거나 시작 메뉴에서 Firewall 검색하고 Allow an app through the firewall 으로 가서 ``Docker Desktop Backend``가 허용되는지 확인하세요.
LARS를 처음 실행하면 문장 변환기 임베딩 모델이 다운로드됩니다.
컨테이너화된 환경에서 이 다운로드는 때때로 문제가 될 수 있으며 쿼리를 요청할 때 오류가 발생할 수 있습니다.
이런 일이 발생하면 LARS 설정 메뉴( Settings->VectorDB & Embedding Models 로 이동하여 임베딩 모델을 BGE-Base 또는 BGE-Large로 변경하면 강제로 다시 로드되고 다시 다운로드됩니다.
완료되면 다시 질문을 진행하면 응답이 정상적으로 생성됩니다.
문장 변환기 삽입 모델로 다시 전환하면 문제가 해결됩니다.
위의 문제 해결 섹션에 설명된 대로 임베딩 모델은 LARS가 처음 실행될 때 다운로드됩니다.
컨테이너를 종료하기 전에 컨테이너 상태를 저장하는 것이 가장 좋습니다. 따라서 이후에 컨테이너가 시작될 때마다 이 다운로드 단계를 반복할 필요가 없습니다.
이렇게 하려면 실행 중인 LARS 컨테이너를 종료하기 전에 다른 명령 프롬프트/터미널을 열고 변경 사항을 커밋하세요.
docker ps # note the container_id here
docker commit <container_ID> <new_image_name> # for new_image_name, I simply add 'pfr', for 'post-first-run' to the current image name, example: lars-nvcuda-pfr
그러면 후속 실행에서 사용할 수 있는 업데이트된 이미지가 생성됩니다.
docker run --gpus all -p 5000:5000 -p 8080:8080 -v lars_storage:/app/storage lars-nvcuda-pfr
참고: 위 작업을 수행한 후 docker images 사용하여 이미지가 사용하는 공간을 확인하면 사용된 공간이 많이 있음을 알 수 있습니다. 그러나 여기의 크기를 문자 그대로 받아들이지 마십시오! 각 이미지에 표시되는 크기에는 모든 레이어의 전체 크기가 포함되지만, 특히 해당 이미지가 동일한 기본 이미지를 기반으로 하거나 한 이미지가 다른 이미지의 커밋된 버전인 경우 해당 레이어 중 상당수가 이미지 간에 공유됩니다. Docker 이미지가 실제로 사용하고 있는 디스크 공간을 확인하려면 다음을 사용하세요.
docker system df
목차로 돌아가기
| 범주 | 작업 | 상태 |
|---|---|---|
| 버그 수정: | 0바이트 텍스트 파일 생성 위험 - 때때로 입력 문서의 OCR/텍스트 추출이 실패하는 경우 0B .txt 파일이 남아 있어 파일이 이미 로드되었다고 믿게 만드는 추가 재시도가 발생할 수 있습니다. | ? 향후 과제 |
| 실용적인 특징: | 사용 편의성 중심: | |
| Azure CV-OCR 무료 계층 UI 토글 | ✅ 2024년 6월 8일 완료 | |
| 채팅 삭제 | ? 향후 과제 | |
| 채팅 이름 바꾸기 | ? 향후 과제 | |
| PowerShell 설치 스크립트 | ? 향후 과제 | |
| 리눅스 설치 스크립트 | ? 향후 과제 | |
| llama.cpp의 대안으로 Ollama LLM 추론 백엔드 | ? 향후 과제 | |
| 다른 클라우드 제공업체(GCP, AWS, OCI 등)의 OCR 서비스 통합 | ? 향후 과제 | |
| 문서를 업로드할 때 이전 텍스트 추출을 무시하는 UI 토글 | ? 향후 과제 | |
| 파일 업로드를 위한 모달 팝업: 설정에서 텍스트 추출 옵션 미러링, 제출 시 전역 덮어쓰기, 설정 유지로 전환 | ? 향후 과제 | |
| 성능 중심: | ||
| 엔비디아 TensorRT-LLM AWQ 지원 | ? 향후 과제 | |
| 연구 과제: | Nvidia TensorRT-LLM 조사: 대상 GPU에 특정한 AWQ-LLM TRT 엔진을 구축해야 합니다. NvTensorRT-LLM은 자체 생태계이며 Python v3.10에서만 작동합니다. | ✅ 2024년 6월 13일 완료 |
| Vision LLM이 포함된 로컬 OCR: MS-TrOCR(완료), Kosmos-2.5(높은 우선순위), Llava, Florence-2 | ? 2024년 7월 5일 업데이트 진행 중 | |
| RAG 개선: Re-ranker, RAPTOR, T-RAG | ? 향후 과제 | |
| GraphDB 통합 조사: LLM을 사용하여 문서에서 엔터티 관계 데이터를 추출하고 GraphDB를 채우고 업데이트 및 유지 관리합니다. | ? 향후 과제 |
목차로 돌아가기
LARS가 귀하의 작업에 귀중한 역할을 하였기를 바라며 지속적인 개발을 지원해 주시기 바랍니다! 도구에 감사하고 향후 개선에 기여하고 싶다면 기부를 고려해 보세요. 귀하의 지원은 LARS를 지속적으로 개선하고 새로운 기능을 추가하는 데 도움이 됩니다.
기부 방법 기부하려면 내 PayPal에 대한 다음 링크를 사용하십시오.
PayPal을 통해 기부
귀하의 기여에 크게 감사드리며 향후 개발 노력에 자금을 지원하는 데 사용될 것입니다.
목차로 돌아가기


