cambrian
1.0.0
재미있는 사실: 시력은 캄브리아기 시대에 동물에게서 나타났습니다! 이것이 우리 프로젝트 이름 Cambrian에 영감을 주었습니다.
eval/ 하위 폴더를 참조하세요.dataengine/ 하위 폴더를 참조하세요.현재 TorchXLA를 사용한 TPU 교육을 지원합니다.
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install -e " .[tpu] " pip install torch~=2.2.0 torch_xla[tpu]~=2.2.0 -f https://storage.googleapis.com/libtpu-releases/index.html
git clone https://github.com/cambrian-mllm/cambrian
cd cambrianconda create -n cambrian python=3.10 -y
conda activate cambrian
pip install --upgrade pip # enable PEP 660 support
pip install " .[gpu] " 여기에 가중치 사용 방법에 대한 지침과 함께 캄브리아기 체크포인트가 있습니다. 당사의 모델은 8B, 13B 및 34B 매개변수 수준에서 다양한 차원에 걸쳐 탁월합니다. 여러 벤치마크에서 GPT-4V, Gemini-Pro 및 Grok-1.4V와 같은 비공개 소스 독점 모델과 비교하여 경쟁력 있는 성능을 보여줍니다.
| 모델 | # 비스. 톡. | MMB | SQA-I | MathVistaM | 차트QA | MMVP |
|---|---|---|---|---|---|---|
| GPT-4V | UNK | 75.8 | - | 49.9 | 78.5 | 50.0 |
| Gemini-1.0 프로 | UNK | 73.6 | - | 45.2 | - | - |
| Gemini-1.5 프로 | UNK | - | - | 52.1 | 81.3 | - |
| 그록-1.5 | UNK | - | - | 52.8 | 76.1 | - |
| MM-1-8B | 144 | 72.3 | 72.6 | 35.9 | - | - |
| MM-1-30B | 144 | 75.1 | 81.0 | 39.4 | - | - |
| 기본 LLM: Phi-3-3.8B | ||||||
| 캄브리아기-1-8B | 576 | 74.6 | 79.2 | 48.4 | 66.8 | 40.0 |
| 기본 LLM: LLaMA3-8B-Instruct | ||||||
| 미니-제미니-HD-8B | 2880 | 72.7 | 75.1 | 37.0 | 59.1 | 18.7 |
| LLaVA-NeXT-8B | 2880 | 72.1 | 72.8 | 36.3 | 69.5 | 38.7 |
| 캄브리아기-1-8B | 576 | 75.9 | 80.4 | 49.0 | 73.3 | 51.3 |
| 기본 LLM: Vicuna1.5-13B | ||||||
| 미니-제미니-HD-13B | 2880 | 68.6 | 71.9 | 37.0 | 56.6 | 19.3 |
| LLaVA-NeXT-13B | 2880 | 70.0 | 73.5 | 35.1 | 62.2 | 36.0 |
| 캄브리아기-1-13B | 576 | 75.7 | 79.3 | 48.0 | 73.8 | 41.3 |
| 기본 LLM: Hermes2-Yi-34B | ||||||
| 미니-제미니-HD-34B | 2880 | 80.6 | 77.7 | 43.4 | 67.6 | 37.3 |
| LLaVA-NeXT-34B | 2880 | 79.3 | 81.8 | 46.5 | 68.7 | 47.3 |
| 캄브리아기-1-34B | 576 | 81.4 | 85.6 | 53.2 | 75.6 | 52.7 |
전체 표를 보려면 Cambrian-1 논문을 참조하세요.
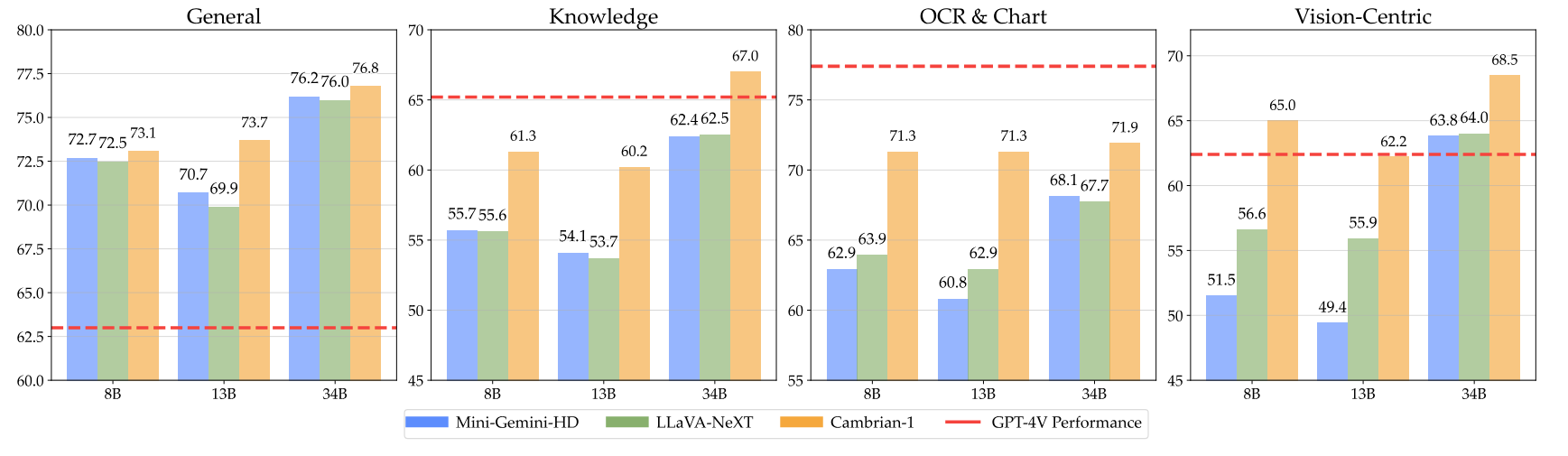
우리 모델은 더 적은 수의 시각적 토큰을 사용하면서 매우 경쟁력 있는 성능을 제공합니다.
모델 가중치를 사용하려면 Hugging Face에서 다운로드하세요.
inference.py 에서 샘플 모델 로딩 및 생성 스크립트를 제공합니다.

이 작업에서 우리는 MLLM 훈련 데이터를 연구하기 위한 향후 작업을 위해 매우 큰 명령 튜닝 데이터 풀인 Cambrian-10M을 수집합니다. 예비 연구에서 우리는 데이터를 Cambrian-7M이라고 하는 고품질의 7M 선별 데이터 포인트 세트로 필터링했습니다. 이 두 데이터세트는 Hugging Face 데이터세트인 Cambrian-10M에서 사용할 수 있습니다.
우리는 VQA, 시각적 대화, 구체화된 시각적 상호 작용을 비롯한 다양한 소스로부터 다양한 범위의 시각적 명령 조정 데이터를 수집했습니다. 고품질, 신뢰성 있는 대규모 지식 데이터를 보장하기 위해 인터넷 데이터 엔진을 설계했습니다.
또한 우리는 VQA 데이터가 매우 짧은 출력을 생성하는 경향이 있어 훈련 데이터에서 분포 변화가 발생한다는 것을 관찰했습니다. 이 문제를 해결하기 위해 우리는 GPT-4v 및 GPT-4o를 활용하여 확장된 응답과 보다 창의적인 데이터를 만들었습니다.
과학 관련 데이터의 부족함을 해결하기 위해 인터넷 데이터 엔진을 설계하여 신뢰할 수 있는 과학 관련 VQA 데이터를 수집했습니다. 이 엔진은 모든 주제에 대한 데이터를 수집하는 데 적용할 수 있습니다. 이 엔진을 사용하여 161,000개의 과학 관련 시각적 지침 튜닝 데이터 포인트를 추가로 수집하여 이 도메인의 총 데이터를 400% 늘렸습니다! 이 부분의 데이터를 사용하려면 이 jsonl을 사용하세요.
우리는 GPT-4v를 사용하여 추가 77,000개의 데이터 포인트를 생성했습니다. 이 데이터는 GPT-4v를 사용하여 원래의 답변 전용 VQA를 더 자세한 응답을 포함하는 더 긴 답변으로 다시 작성하거나 주어진 이미지를 기반으로 시각적 명령 조정 데이터를 생성합니다. 이 부분의 데이터를 사용하려면 이 jsonl을 사용하세요.
우리는 GPT-4o를 사용하여 추가로 60,000개의 크리에이티브 데이터 포인트를 생성했습니다. 이 데이터는 모델이 매우 긴 응답을 생성하도록 장려하며 종종 시 쓰기, 노래 작곡 등과 같은 매우 창의적인 질문을 포함합니다. 이 부분의 데이터를 사용하려면 이 jsonl을 사용하세요.
우리는 다음을 통해 데이터 큐레이션에 대한 초기 연구를 수행했습니다.
경험적으로 우리는 그 설정을 발견했습니다
| 범주 | 데이터 비율 |
|---|---|
| 언어 | 21.00% |
| 일반적인 | 34.52% |
| OCR | 27.22% |
| 계산 | 8.71% |
| 수학 | 7.20% |
| 암호 | 0.87% |
| 과학 | 0.88% |
이전 LLaVA-665K 모델과 비교하여 아래 표에 표시된 것처럼 확장 및 향상된 데이터 큐레이션으로 모델 성능이 크게 향상되었습니다.
| 모델 | 평균 | 일반 지식 | OCR | 차트 | 비전 중심 |
|---|---|---|---|---|---|
| LLaVA-665K | 40.4 | 64.7 | 45.2 | 20.8 | 31.0 |
| 캄브리아기-10M | 53.8 | 68.7 | 51.6 | 47.1 | 47.6 |
| 캄브리아기-7M | 54.8 | 69.6 | 52.6 | 47.3 | 49.5 |
Cambrian-7M을 사용한 교육은 경쟁력 있는 벤치마크 결과를 제공하지만 모델이 더 짧은 응답을 출력하고 질문 답변 기계처럼 작동하는 경향이 있음을 관찰했습니다. "Answer Machine" 현상이라고 하는 이 동작은 보다 복잡한 상호 작용에서 모델의 유용성을 제한할 수 있습니다.
"단어나 문구를 사용하여 질문에 답하세요"와 같은 시스템 프롬프트를 추가하는 것을 발견했습니다. 문제를 완화하는 데 도움이 될 수 있습니다. 이 접근 방식은 모델이 상황에 따라 적절한 경우에만 간결한 답변을 제공하도록 권장합니다. 자세한 내용은 당사의 논문을 참조하세요.
또한 모델의 창의성과 채팅 능력을 향상시키기 위한 시스템 프롬프트가 포함된 시스템 프롬프트가 포함 된 Cambrian-7M 데이터세트를 선별했습니다.
다음은 Cambrian-1의 최신 교육 구성입니다.
Cambrian-1 논문에서는 2단계 훈련의 필요성을 입증하기 위해 광범위한 연구를 수행합니다. Cambrian-1 훈련은 두 단계로 구성됩니다.
Cambrian-1은 TPU-V4-512에서 학습되었지만 TPU-V4-64부터 TPU에서도 학습될 수 있습니다. GPU 훈련 코드는 곧 출시될 예정입니다. 더 적은 수의 GPU에서 GPU 훈련을 하려면 per_device_train_batch_size 를 줄이고 그에 따라 gradient_accumulation_steps 늘려서 전역 배치 크기가 동일하게 유지되도록 하십시오: per_device_train_batch_size gradient_accumulation_steps x num_gpus .
사전 훈련과 미세 조정에 사용되는 하이퍼파라미터는 모두 아래에 나와 있습니다.
| 기본 LLM | 글로벌 배치 크기 | 학습률 | SVA 학습률 | 시대 | 최대 길이 |
|---|---|---|---|---|---|
| LLaMA-3 8B | 512 | 1e-3 | 1e-4 | 1 | 2048년 |
| 비쿠나-1.5 13B | 512 | 1e-3 | 1e-4 | 1 | 2048년 |
| 헤르메스 Yi-34B | 1024 | 1e-3 | 1e-4 | 1 | 2048년 |
| 기본 LLM | 글로벌 배치 크기 | 학습률 | 시대 | 최대 길이 |
|---|---|---|---|---|
| LLaMA-3 8B | 512 | 4e-5 | 1 | 2048년 |
| 비쿠나-1.5 13B | 512 | 4e-5 | 1 | 2048년 |
| 헤르메스 Yi-34B | 1024 | 2e-5 | 1 | 2048년 |
지침 미세 조정을 위해 모델 훈련을 위한 최적의 학습 속도를 결정하기 위한 실험을 수행했습니다. 조사 결과에 따르면 다음 공식을 사용하여 장치의 가용성에 따라 학습률을 조정하는 것이 좋습니다.
optimal lr = base_lr * sqrt(bs / base_bs)
기본 LLM을 얻고 8B, 13B 및 34B 모델을 교육하려면 다음을 수행하세요.
우리는 LLaVA, ShareGPT4V, Mini-Gemini 및 ALLaVA 정렬 데이터의 조합을 사용하여 시각적 커넥터(SVA)를 사전 훈련합니다. Cambrian-1에서는 추가 정렬 데이터 사용의 필요성과 이점을 입증하기 위해 광범위한 연구를 수행합니다.
시작하려면 포옹 얼굴 정렬 데이터 페이지를 방문하여 자세한 내용을 확인하세요. 다음 링크에서 정렬 데이터를 다운로드할 수 있습니다.
우리는 다음에서 샘플 교육 스크립트를 제공합니다.
다른 데이터 소스나 사용자 정의 데이터로 훈련하려는 경우 일반적으로 사용되는 LLaVA 데이터 형식을 지원합니다. 매우 큰 파일을 처리할 때 지연 데이터 로딩을 위해 JSON 형식 대신 JSONL 형식을 사용하여 메모리 사용을 최적화합니다.
Training SVA와 마찬가지로 명령 튜닝 데이터에 대한 자세한 내용을 보려면 Cambrian-10M 데이터를 방문하세요.
우리는 다음에서 샘플 교육 스크립트를 제공합니다.
--mm_projector_type : SVA 모듈을 사용하려면 이 값을 sva 로 설정하세요. LLaVA 스타일 2레이어 MLP 프로젝터를 사용하려면 이 값을 mlp2x_gelu 로 설정하세요.--vision_tower_aux_list : 사용할 비전 모델 목록(예: '["siglip/CLIP-ViT-SO400M-14-384", "openai/clip-vit-large-patch14-336", "facebook/dinov2-giant-res378", "clip-convnext-XXL-multi-stage"]' ).--vision_tower_aux_token_len_list : 각 비전 타워에 대한 비전 토큰 수 목록입니다. 각 숫자는 제곱수여야 합니다(예: '[576, 576, 576, 9216]' ). 이 요구 사항을 충족하기 위해 각 비전 타워의 기능 맵이 보간됩니다.--image_token_len : LLM에 제공될 최종 비전 토큰 수입니다. 숫자는 제곱수여야 합니다(예: 576 ). mm_projector_type 이 mlp인 경우 vision_tower_aux_token_len_list 의 각 숫자는 image_token_len 과 동일해야 합니다. 아래 인수는 SVA 프로젝터에만 의미가 있습니다.--num_query_group : SVA 모듈의 G 값입니다.--query_num_list : SVA의 각 쿼리 그룹에 대한 쿼리 번호 목록입니다(예: '[576]' ). 목록의 길이는 num_query_group 과 같아야 합니다.--connector_depth : SVA 모듈의 D 값입니다.--vision_hidden_size : SVA 모듈의 숨겨진 크기입니다.--connector_only : true인 경우 SVA 모듈은 LLM 앞에만 나타나고, 그렇지 않으면 LLM 내에 여러 번 삽입됩니다. 다음 세 가지 인수는 False 로 설정된 경우에만 의미가 있습니다.--num_of_vision_sampler_layers : LLM 내부에 삽입된 SVA 모듈의 총 수입니다.--start_of_vision_sampler_layers : SVA 삽입이 시작된 이후의 LLM 레이어 인덱스입니다.--stride_of_vision_sampler_layers : LLM 내부에 SVA 모듈 삽입의 보폭입니다. 우리는 eval/ 하위 폴더에 평가 코드를 공개했습니다. 자세한 내용은 README를 참조하세요.
다음 지침은 Cambrian을 사용하여 로컬 Gradio 데모를 시작하는 과정을 안내합니다. 우리는 모델과 상호 작용할 수 있는 간단한 웹 인터페이스를 제공합니다. 추론을 위해 CLI를 사용할 수도 있습니다. 이 설정은 LLaVA에서 많은 영감을 받았습니다.
로컬 Gradio 데모를 실행하려면 아래 단계를 따르세요. 지역 제공 코드의 다이어그램은 1 아래에 있습니다.
%%{init: {"theme": "base"}}%%
흐름도 BT
%% 노드 선언
스타일 gws 채우기:#f9f,획:#333,획 너비:2px
스타일 C 채우기:#bbf,획:#333,획 너비:2px
스타일 mw8b 채우기:#aff,획:#333,획 너비:2px
스타일 mw13b 채우기:#aff,획:#333,획 너비:2px
%% 스타일 sglw13b 채우기:#ffa,획:#333,획 너비:2px
%% 스타일 lsglw13b 채우기:#ffa,획:#333,획 너비:2px
gws["Gradio(UI 서버)"]
c["컨트롤러(API 서버):<br/>포트: 10000"]
mw8b["모델 작업자:<br/><b>Cambrian-1-8B</b><br/>포트: 40000"]
mw13b["모델 작업자:<br/><b>Cambrian-1-13B</b><br/>포트: 40001"]
%% sglw13b["SGLang 백엔드:<br/><b>Cambrian-1-34B</b><br/>http://localhost:30000"]
%% lsglw13b["SGLang 작업자:<br/><b>Cambrian-1-34B<b><br/>포트: 40002"]
하위 그래프 "데모 아키텍처"
방향 BT
c <--> gws
mw8b <--> c
mw13b <--> c
%% lsglw13b <--> c
%% sglw13b <--> lsglw13b
끝
python -m cambrian.serve.controller --host 0.0.0.0 --port 10000python -m cambrian.serve.gradio_web_server --controller http://localhost:10000 --model-list-mode reload방금 Gradio 웹 인터페이스를 시작했습니다. 이제 화면에 인쇄된 URL을 사용하여 웹 인터페이스를 열 수 있습니다. 모델 목록에 모델이 없는 것을 확인할 수 있습니다. 아직 모델 워커를 출시하지 않았으니 걱정하지 마세요. 모델 작업자를 시작하면 자동으로 업데이트됩니다.
곧 출시됩니다.
이는 GPU에서 추론을 수행하는 실제 작업자 입니다. 각 작업자는 --model-path 에 지정된 단일 모델을 담당합니다.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8b프로세스가 모델 로드를 완료할 때까지 기다리면 "Uvicorn running on ..."이 표시됩니다. 이제 Gradio 웹 UI를 새로 고치면 모델 목록에 방금 시작한 모델이 표시됩니다.
원하는 만큼 작업자를 실행하고 동일한 Gradio 인터페이스에서 다양한 모델 체크포인트를 비교할 수 있습니다. --controller 동일하게 유지하고 --port 및 --worker 각 작업자에 대해 다른 포트 번호로 수정하십시오.
python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port < different from 40000, say 40001> --worker http://localhost: < change accordingly, i.e. 40001> --model-path < ckpt 2> M1 또는 M2 칩이 탑재된 Apple 장치를 사용하는 경우 --device 플래그: --device mps 사용하여 mps 장치를 지정할 수 있습니다.
GPU의 VRAM이 24GB 미만인 경우(예: RTX 3090, RTX 4090 등) 여러 GPU로 실행해 볼 수 있습니다. 우리의 최신 코드 베이스는 GPU가 두 개 이상인 경우 자동으로 여러 GPU를 사용하려고 시도합니다. CUDA_VISIBLE_DEVICES 와 함께 사용할 GPU를 지정할 수 있습니다. 다음은 처음 두 개의 GPU를 사용하여 실행하는 예입니다.
CUDA_VISIBLE_DEVICES=0,1 python -m cambrian.serve.model_worker --host 0.0.0.0 --controller http://localhost:10000 --port 40000 --worker http://localhost:40000 --model-path nyu-visionx/cambrian-8bTODO
Cambrian이 귀하의 연구 및 응용에 유용하다고 생각되면 다음 BibTeX를 사용하여 인용해 주십시오.
@misc { tong2024cambrian1 ,
title = { Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs } ,
author = { Shengbang Tong and Ellis Brown and Penghao Wu and Sanghyun Woo and Manoj Middepogu and Sai Charitha Akula and Jihan Yang and Shusheng Yang and Adithya Iyer and Xichen Pan and Austin Wang and Rob Fergus and Yann LeCun and Saining Xie } ,
year = { 2024 } ,
eprint = { 2406.16860 } ,
}
사용 및 라이선스 고지 사항 : 이 프로젝트는 해당 원본 라이선스가 적용되는 특정 데이터 세트 및 체크포인트를 활용합니다. 사용자는 데이터 세트에 대한 OpenAI 사용 약관과 데이터 세트를 사용하여 훈련된 체크포인트에 대한 기본 언어 모델에 대한 특정 라이센스(예: LLaMA-3에 대한 Llama 커뮤니티 라이센스, 및 비쿠나-1.5). 이 프로젝트는 원래 라이센스에 규정된 것 이상의 추가 제한 사항을 부과하지 않습니다. 또한 사용자는 데이터 세트 및 체크포인트를 모든 관련 법률 및 규정을 준수하여 사용하는지 확인해야 합니다.
LLaVA의 다이어그램에서 복사되었습니다. ↩


