Synonyms
Synonyms
자연어 처리 및 이해에 대한 중국어 동의어.
더 나은 중국어 동의어: 챗봇, 지능형 질문 및 답변 툴킷.
synonyms 텍스트 정렬, 추천 알고리즘, 유사성 계산, 의미 오프셋, 키워드 추출, 개념 추출, 자동 요약, 검색 엔진 등 자연어 이해의 다양한 작업에 사용될 수 있습니다.
안정적이고 신뢰할 수 있으며 장기적으로 최적화된 서비스를 제공하기 위해 동의어는 Chunsong 라이선스 v1.0을 사용하도록 변경되었으며 기계 학습 모델 다운로드 비용은 자세한 내용은 인증서 저장소를 참조하세요. 이전 기여자(뛰어난 기여를 한 코드 기여자)는 당사에 연락하여 청구 문제를 논의할 수 있습니다. -- Chatopera Inc. @ 2023년 10월
패키지를 설치하고 활성화하려면 아래 단계를 따르세요.
pip install -U synonyms현재 안정 버전은 v3.x입니다.
Synonyms의 기계 학습 모델 패키지는 Chatopera License Store의 라이선스가 필요합니다. 먼저 라이선스를 구매하고 Chatopera License Store의 라이선스 페이지에서 license id 받습니다.( license id : 인증서 스토어의 인증서 세부 정보 페이지에서 [복사]를 클릭합니다. 인증서 신원] ).
둘째, 아래와 같이 터미널이나 쉘 스크립트에서 환경 변수를 설정하십시오.
예: Linux, Windows, macOS의 Shell, CMD 스크립트.
# Linux / macOS
export SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # e.g. if your license id is `FOOBAR`, run `export SYNONYMS_DL_LICENSE=FOOBAR`
# Windows
# # 1/2 Command Prompt
set SYNONYMS_DL_LICENSE=YOUR_LICENSE
# # 2/2 PowerShell
$env :SYNONYMS_DL_LICENSE= ' YOUR_LICENSE '주피터 노트북 등
import os
os . environ [ "SYNONYMS_DL_LICENSE" ] = "YOUR_LICENSE"
_licenseid = os . environ . get ( "SYNONYMS_DL_LICENSE" , None )
print ( "SYNONYMS_DL_LICENSE=" , _licenseid )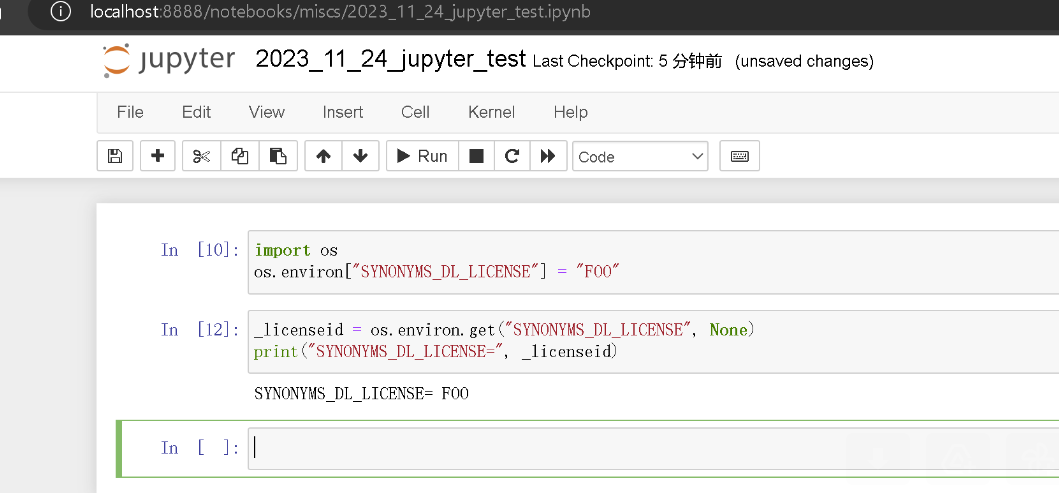
Tip: 단어 벡터 파일은 설치 후 처음 다운로드되며, 다운로드 속도는 네트워크 상태에 따라 달라집니다.
마지막으로 명령이나 스크립트를 통해 모델 패키지를 다운로드합니다.
python -c " import synonyms; synonyms.display('能量') " # download word vectors file 
환경 변수를 사용하여 단어 분할 어휘 및 word2vec 단어 벡터 파일을 구성할 수 있습니다.
| 환경 변수 | 설명하다 |
|---|---|
| SYNONYMS_WORD2VEC_BIN_MODEL_ZH_CN | word2vec, 바이너리 형식을 사용하여 훈련된 Word 벡터 파일입니다. |
| SYNONYMS_WORDSEG_DICT | 중국어 단어 분할 마스터 사전 , 형식 및 사용법 참조 |
| 동의어_디버그 | ["TRUE"|"FALSE"], 디버깅 로그 출력 여부, "TRUE" 출력으로 설정, 기본값은 "FALSE" |
import synonyms
print ( "人脸: " , synonyms . nearby ( "人脸" ))
print ( "识别: " , synonyms . nearby ( "识别" ))
print ( "NOT_EXIST: " , synonyms . nearby ( "NOT_EXIST" )) synonyms.nearby(WORD [,SIZE]) 튜플을 반환합니다. 튜플에는 ([nearby_words], [ nearby_words ([nearby_words], [nearby_words_score]) 라는 두 항목이 포함됩니다. 거리가 가까운 것부터 먼 것 순으로 배열되어 있습니다. nearby_words_score 는 nearby_words 의 해당 위치 에 있는 단어 사이의 거리에 대한 점수입니다. 점수는 (0-1) 간격에 있으며 1에 가까울수록 반환되는 단어 수는 SIZE 에 가깝습니다. 기본값은 10입니다. 예를 들어:
synonyms . nearby (人脸, 10 ) = (
[ "图片" , "图像" , "通过观察" , "数字图像" , "几何图形" , "脸部" , "图象" , "放大镜" , "面孔" , "Mii" ],
[ 0.597284 , 0.580373 , 0.568486 , 0.535674 , 0.531835 , 0.530
095 , 0.525344 , 0.524009 , 0.523101 , 0.516046 ]) OOV의 경우 ([], []) 반환되며 현재 사전 크기는 435,729입니다.
두 문장의 유사성 비교
sen1 = "发生历史性变革"
sen2 = "发生历史性变革"
r = synonyms . compare ( sen1 , sen2 , seg = True )그 중 seg 매개변수는 Synonys.compare가 sen1과 sen2에 대해 단어 분할을 수행하는지 여부를 나타내며 기본값은 True입니다. 반환값 : [0-1], 1에 가까울수록 두 문장이 유사함을 의미합니다.
旗帜引领方向 vs 道路决定命运: 0.429
旗帜引领方向 vs 旗帜指引道路: 0.93
发生历史性变革 vs 发生历史性变革: 1.0 display(WORD [, SIZE]) 을 용이하게 하기 위해 친숙한 방식으로 synonyms#nearby 를 인쇄합니다.
>> > synonyms . display ( "飞机" )
'飞机'近义词:
1. 飞机: 1.0
2. 直升机: 0.8423391
3. 客机: 0.8393003
4. 滑翔机: 0.7872388
5. 军用飞机: 0.7832081
6. 水上飞机: 0.77857226
7. 运输机: 0.7724742
8. 航机: 0.7664748
9. 航空器: 0.76592904
10. 民航机: 0.74209654 SIZE 인쇄된 어휘 목록의 수이며 기본값은 10입니다.
현재 패키지의 설명 정보를 인쇄합니다.
>>> synonyms.describe()
Vocab size in vector model: 435729
model_path: /Users/hain/chatopera/Synonyms/synonyms/data/words.vector.gz
version: 3.18.0
{'vocab_size': 435729, 'version': '3.18.0', 'model_path': '/chatopera/Synonyms/synonyms/data/words.vector.gz'}
numpy 배열인 단어 벡터를 가져옵니다. 단어가 등록되지 않은 단어인 경우 KeyError 예외가 발생합니다.
>> > synonyms . v ( "飞机" )
array ([ - 2.412167 , 2.2628384 , - 7.0214124 , 3.9381874 , 0.8219283 ,
- 3.2809453 , 3.8747153 , - 5.217062 , - 2.2786229 , - 1.2572327 ],
dtype = float32 )단어 분할 후 문장의 벡터를 구합니다. 벡터는 BoW 모드에서 구성됩니다.
sentence : 句子是分词后通过空格联合起来
ignore : 是否忽略OOV , False时,随机生成一个向量중국어 단어 분할
synonyms . seg ( "中文近义词工具包" )단어 분할 결과는 단어와 해당 품사로 구성된 두 개의 목록으로 구성된 튜플입니다.
([ '中文' , '近义词' , '工具包' ], [ 'nz' , 'n' , 'n' ])이 분사는 중지 단어와 구두점을 제거하지 않습니다.
키워드 추출 기본적으로 중요도에 따라 키워드가 추출됩니다.
keywords = synonyms.keywords("9月15日以来,台积电、高通、三星等华为的重要合作伙伴,只要没有美国的相关许可证,都无法供应芯片给华为,而中芯国际等国产芯片企业,也因采用美国技术,而无法供货给华为。目前华为部分型号的手机产品出现货少的现象,若该形势持续下去,华为手机业务将遭受重创。")
디버깅을 위해 더 많은 로그를 가져오고 환경 변수를 설정하세요.
SYNONYMS_DEBUG=TRUE
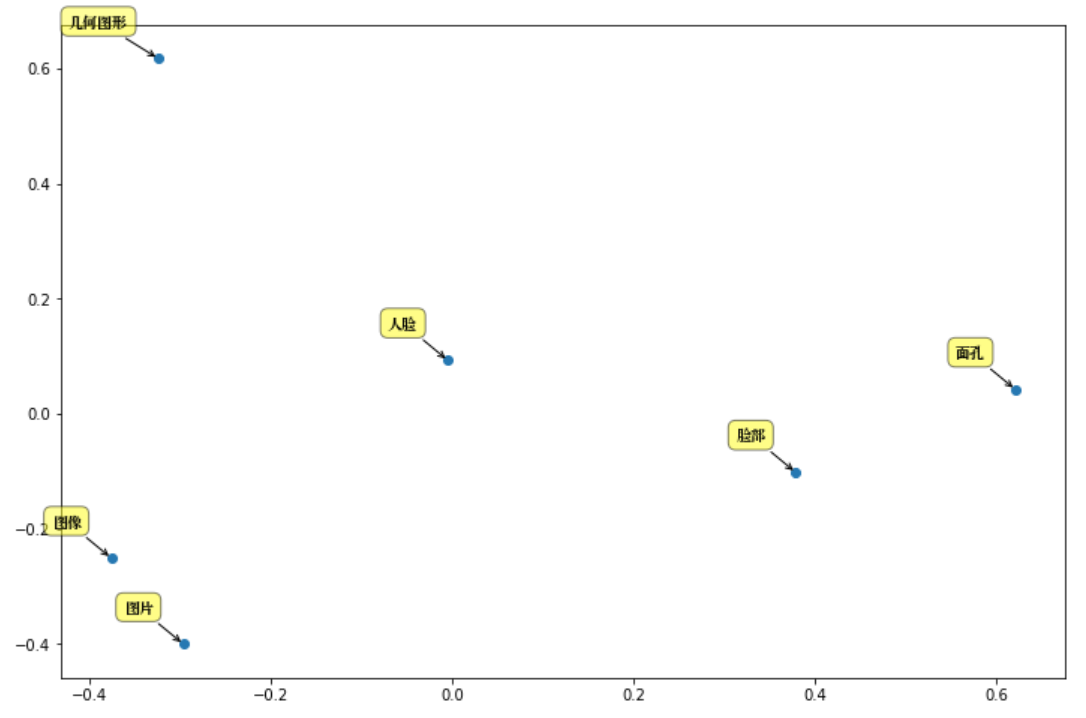
주요 구성 요소를 분석하기 위해 "사람의 얼굴"을 예로 들어 보겠습니다.
$ pip install -r Requirements.txt
$ python demo.py상태 설명이 업데이트되었습니다.
사용자 의견:
데이터는 wikidata-corpus를 기반으로 구축되었습니다.
"동의어 Cilin"은 1983년에 Mei Jiaju 등이 편집했습니다. 현재 가장 널리 사용되는 버전은 하얼빈 공업대학교 사회 컴퓨팅 및 정보 검색 연구 센터에서 관리하는 "동의어 Cilin 확장판"입니다. 카테고리와 하위 카테고리는 단어 간의 관계를 정리합니다. 동의어 Cilin의 확장 버전에는 70,000개 이상의 단어가 포함되어 있으며, 그 중 30,000개 이상이 오픈 데이터 형태로 공유됩니다.
HowNet이라고도 알려진 HowNet은 단순한 의미 사전이 아니라 단어 간의 관계는 기본 사용 시나리오 중 하나입니다. CNKI에 8개 이상의 단어가 포함되어 있습니다.
단어 유사성 알고리즘에 대한 국제 평가 표준은 일반적으로 Miller&Charles에서 발표한 영어 단어 쌍 집합의 수동 판단 값을 채택합니다. 단어쌍 집합은 관련성이 높은 영어 단어쌍 10쌍, 관련성이 낮은 영어 단어쌍 10쌍, 관련성이 낮은 영어 단어쌍 10쌍으로 구성되며, 피험자 38명에게 이 30쌍의 의미적 관련성을 판단하고 최종적으로 평균을 구하게 된다. 값은 수동 기준으로 사용됩니다. 그런 다음 다양한 동의어 도구도 이러한 단어의 유사성을 평가하고 이를 Pearson 상관 계수 사용과 같은 수동 판단 기준과 비교합니다. 중국어 분야에서는 중국어 동의어를 비교하기 위해 이 어휘 목록의 번역 버전을 사용하는 것도 일반적인 방법입니다.
동의어의 어휘 목록 용량은 435,729개입니다. 아래에서는 유사성을 비교하기 위해 동의어 Cilin, CNKI 및 동의어에 존재하는 일부 단어를 선택합니다.
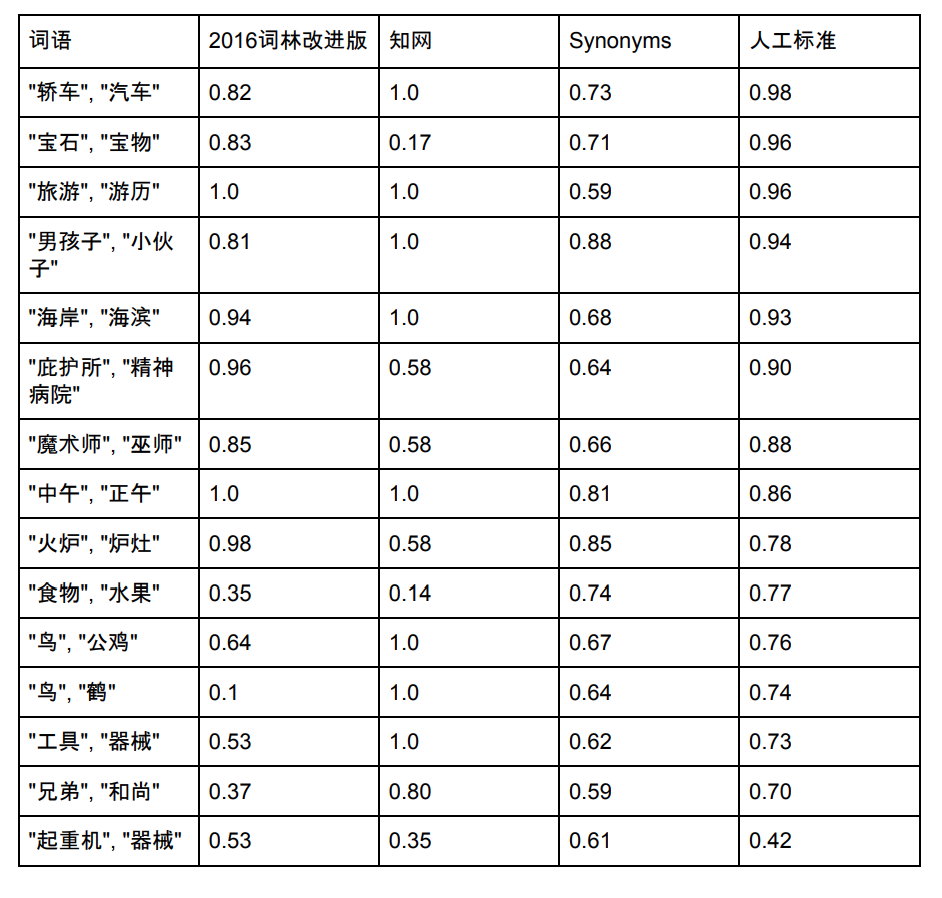
참고: Synonym Forest 및 CNKI 데이터 및 점수의 출처. 동의어 역시 지속적으로 최적화되고 있으며, 새로운 점수는 위의 그림과 일치하지 않을 수 있습니다.
추가 비교 결과.
Github 관련 사용자 목록
py3, MacBook Pro로 테스트해 보세요.
python benchmark.py
++++++++++ OS 이름 및 버전 ++++++++++
플랫폼: 다윈
커널: 16.7.0
아키텍처: ('64비트', '')
++++++++++ CPU 코어 ++++++++++
코어: 4
CPU 부하: 60
++++++++++ 시스템 메모리 ++++++++++
메모정보 8GB
synonyms#nearby: 100000 loops, best of 3 epochs: 0.209 usec per loop
52nlp.cn
기계의 심장
온라인 공유 기록 : 동의어 중국어 동의어 툴킷 @ 2018-02-07
동의어는 인증서 MIT를 게시합니다. 데이터와 절차는 연구 및 상업용 제품에 사용될 수 있으며 게시된 모든 미디어, 저널, 잡지 또는 블로그 등에서 인용되고 언급되어야 합니다.
@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/chatopera/Synonyms},
urldate = {2017-09-27}
}
위키데이터 말뭉치
word2vec 원리 도출 및 코드 분석
지원되지 않습니다. 자세한 내용은 #5를 참조하세요.
Google에서 출시한 Word2vec은 C 언어로 작성된 라이브러리로 메모리 사용 효율성이 높고 학습 속도가 빠릅니다. gensim은 word2vec에서 출력된 모델 파일을 로드할 수 있습니다.
자세한 내용은 #64를 참조하세요.
왕 하이량
후잉시
이 책은 동의어 작가들의 공동 집필입니다.
빠른 도서 구매 링크 
『지능형 질문답변과 딥러닝』은 머신러닝과 자연어 처리를 시작하려는 학생과 소프트웨어 엔지니어를 위한 책으로, 이론상 많은 원리와 알고리즘을 소개하고 실용성을 높이기 위한 다양한 예제 프로그램도 제공하고 있다. 샘플 프로그램 코드 라이브러리에 요약되어 있습니다. 이 프로그램은 주로 모든 사람이 원리와 알고리즘을 이해하도록 돕기 위한 것입니다. 코드베이스의 주소는 다음과 같습니다.
https://github.com/l11x0m7/book-of-qna-code
Google의 Word2vec
Wikimedia: 훈련 코퍼스 소스
원본: word2vec.py
SentenceSim: 유사성 평가 코퍼스
jieba: 중국어 단어 분할
춘송 공중 라이선스, 버전 1.0
https://bot.chatopera.com/
Chatopera 클라우드 서비스는 채팅 로봇 구현을 위한 원스톱 클라우드 서비스이며, 인터페이스 호출 횟수에 따라 요금이 청구됩니다. Chatopera Cloud Service는 Chatopera 봇 플랫폼의 SaaS(Software-as-a-Service) 인스턴스입니다. Chatopera 클라우드 서비스는 클라우드 컴퓨팅을 기반으로 하는 챗봇 서비스형 클라우드 서비스입니다.
Chatopera 로봇 플랫폼에는 지식 기반, 다단계 대화, 의도 인식 및 음성 인식, 표준화된 채팅 로봇 개발과 같은 구성 요소가 포함되어 있으며 엔터프라이즈 OA 지능형 Q&A, HR 지능형 Q&A, 지능형 고객 서비스 및 온라인 마케팅과 같은 시나리오를 지원합니다. 기업 IT 부서와 비즈니스 부서는 Chatopera 클라우드 서비스를 사용하여 신속하게 챗봇을 온라인으로 전환합니다!


