chat4u
1.0.0
WeChat 채팅 기록을 사용하여 나만의 챗봇을 훈련하세요.
WeChat 채팅 기록은 암호화되어 sqlite 데이터베이스에 저장됩니다. 먼저 데이터베이스 키를 얻어야 하며, Android/iPhone 휴대폰이 필요합니다.
git clone https://github.com/nalzok/wechat-decipher-macossudo ./wechat-decipher-macos/macos/dbcracker.d -p $( pgrep WeChat ) | tee dbtrace.logdbtrace.log 에 저장됩니다. sqlcipher '/Users/<user>/Library/Containers/com.tencent.xinWeChat/Data/Library/Application Support/com.tencent.xinWeChat/2.0b4.0.9/5976edc4b2ac64741cacc525f229c5fe/Message/msg_0.db'
--------------------------------------------------------------------------------
PRAGMA key = "x'<384_bit_key>'";
PRAGMA cipher_compatibility = 3;
PRAGMA kdf_iter = 64000;
PRAGMA cipher_page_size = 1024;
........................................
다른 운영 체제 사용자는 참고용으로 연구만 수행되고 검증되지 않은 다음 방법을 시도해 볼 수 있습니다.
EnMicroMsg.db 내보내기 위한 ROOT 권한: https://github.com/ppwwyyxx/wechat-dumpEnMicroMsg.db 키 무차별 대입: https://github.com/chg-hou/EnMicroMsg.db-Password-Cracker 내 macOS 노트북에서는 WeChat 채팅 기록이 msg_0.db - msg_9.db 에 저장되어 있으며 이 데이터베이스만 해독할 수 있습니다.
암호 해독을 위해서는 sqlcipher를 설치해야 합니다. macOS 시스템 사용자는 다음을 직접 실행할 수 있습니다.
brew install sqlcipher 다음 스크립트를 실행하여 dbtrace.log 자동으로 구문 분석하고, msg_x.db 해독하고 plain_msg_x.db 로 내보냅니다.
python3 decrypt.py https://sqliteviewer.app/을 통해 복호화된 데이터베이스 plain_msg_x.db 를 열고, 필요한 채팅 기록이 있는 테이블을 찾아 prepare_data.py 에 데이터베이스 및 테이블 이름을 입력하고, 다음 스크립트를 실행하여 생성할 수 있습니다. 훈련 데이터 train.json 현재 전략은 비교적 간단합니다. 단일 대화 라운드만 처리하고 5분 이내에 연속 대화를 병합합니다.
python3 prepare_data.py학습 데이터의 예는 다음과 같습니다.
[
{ "instruction" : "你好" , "output" : "你好" }
{ "instruction" : "你是谁" , "output" : "你猜猜" }
] GPU가 포함된 Linux 시스템과 GPU 시스템에 대한 scp train.json 준비합니다.
저는 stanford_alpaca 전체 이미지 미세 조정 LLaMA-7B를 사용하고 8카드 V100-SXM2-32GB에서 3세대 동안 90,000개의 데이터를 훈련했는데, 이는 단 1시간 밖에 걸리지 않았습니다.
# clone the alpaca repo
git clone https://github.com/tatsu-lab/stanford_alpaca.git && cd stanford_alpaca
# adjust deepspeed config ... such as disabling offloading
vim ./configs/default_offload_opt_param.json
# train with deepspeed zero3
torchrun --nproc_per_node=8 --master_port=23456 train.py
--model_name_or_path huggyllama/llama-7b
--data_path ../train.json
--model_max_length 128
--fp16 True
--output_dir ../llama-wechat
--num_train_epochs 3
--per_device_train_batch_size 8
--per_device_eval_batch_size 8
--gradient_accumulation_steps 1
--evaluation_strategy " no "
--save_strategy " epoch "
--save_total_limit 1
--learning_rate 2e-5
--weight_decay 0.
--warmup_ratio 0.03
--lr_scheduler_type " cosine "
--logging_steps 10
--deepspeed " ./configs/default_offload_opt_param.json "
--tf32 FalseDeepSpeed zero3은 가중치를 슬라이스로 저장하며 이를 pytorch 체크포인트 파일에 병합해야 합니다.
cd llama-wechat
python3 zero_to_fp32.py . pytorch_model.bin소비자급 그래픽 카드에서는 alpaca-lora를 사용해 볼 수 있습니다. lora 가중치를 미세 조정해야만 그래픽 메모리와 교육 비용을 크게 줄일 수 있습니다.
디버깅을 위해 alpaca-lora를 사용하여 그래디언트 프런트 엔드를 배포할 수 있습니다. 전체 이미지를 미세 조정하는 경우에는 peft 관련 코드를 주석 처리하고 기본 모델만 로드하면 됩니다.
git clone https://github.com/tloen/alpaca-lora.git && cd alpaca-lora
CUDA_VISIBLE_DEVICES=0 python3 generate.py --base_model ../llama-wechat가동 효과:

OpenAI API와 호환되는 모델 서비스를 배포해야 합니다. 서비스를 시작하려면 llama4openai-api.py를 기반으로 한 간단한 적응을 참조하세요.
CUDA_VISIBLE_DEVICES=0 python3 llama4openai-api.py인터페이스를 사용할 수 있는지 테스트합니다.
curl http://127.0.0.1:5000/chat/completions -v -H " Content-Type: application/json " -H " Authorization: Bearer $OPENAI_API_KEY " --data ' {"model":"llama-wechat","max_tokens":128,"temperature":0.95,"messages":[{"role":"user","content":"你好"}]} 'wechat-chatgpt를 사용하여 WeChat에 액세스하고 API 주소에 대한 로컬 모델 서비스 주소를 입력하세요.
docker run -it --rm --name wechat-chatgpt
-e API=http://127.0.0.1:5000
-e OPENAI_API_KEY= $OPENAI_API_KEY
-e MODEL= " gpt-3.5-turbo "
-e CHAT_PRIVATE_TRIGGER_KEYWORD= " "
-v $( pwd ) /data:/app/data/wechat-assistant.memory-card.json
holegots/wechat-chatgpt:latest가동 효과:
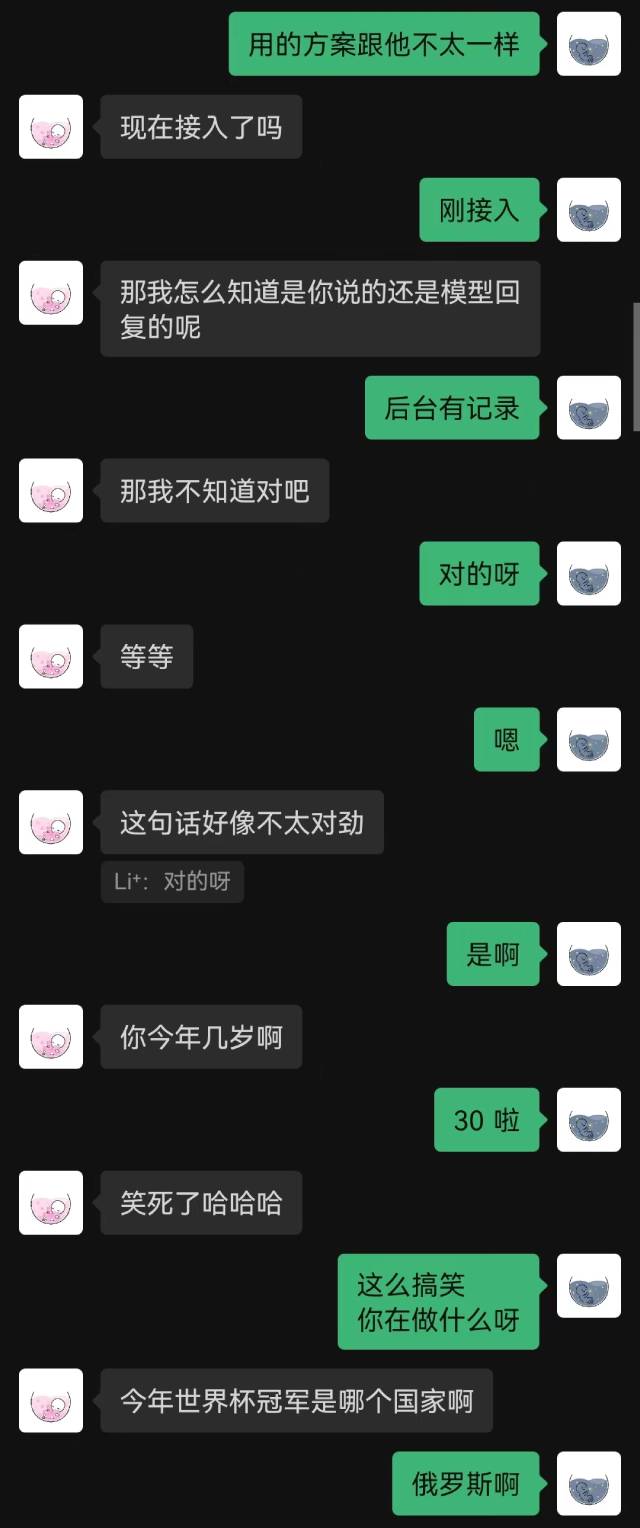 | 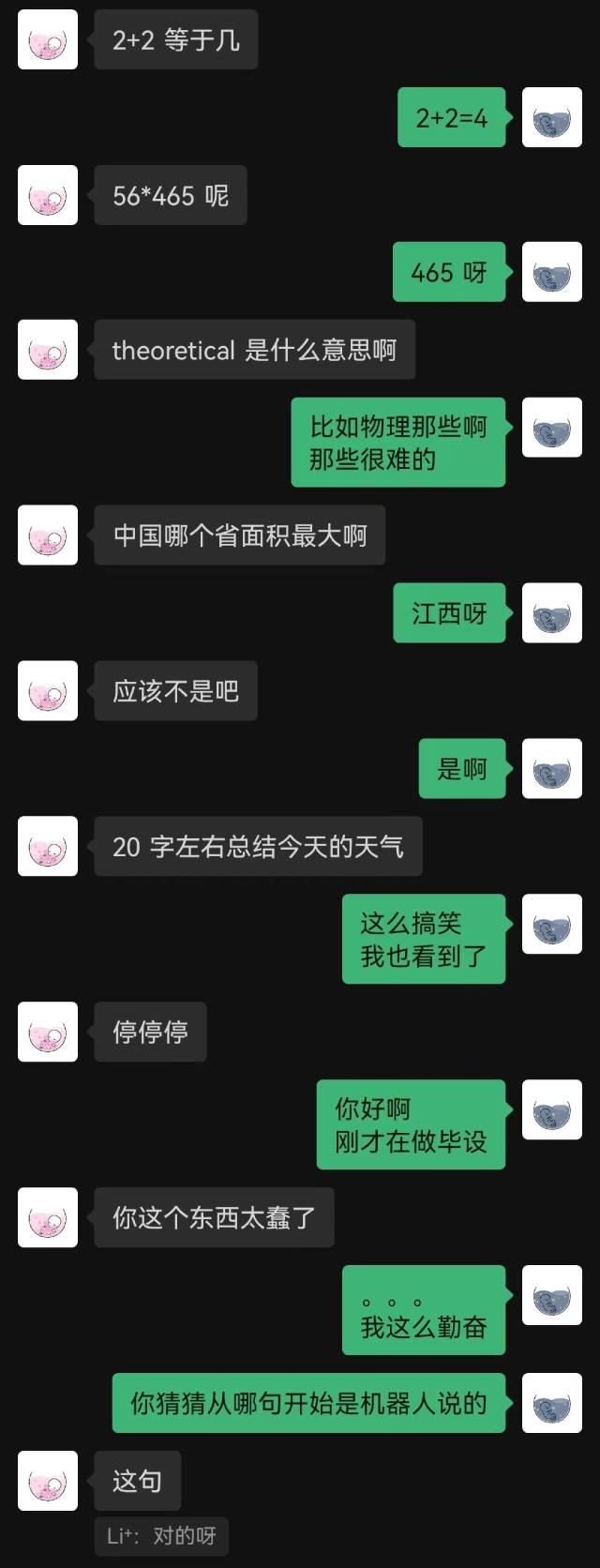 |
|---|
"그냥 연결됐어"라는 말이 로봇이 한 첫 문장이었고, 상대방은 끝까지 짐작하지 못했다.
일반적으로 채팅 기록으로 훈련된 로봇은 필연적으로 상식적인 실수를 할 수 있지만 채팅 스타일을 더 잘 모방했습니다.


