msg_reply
1.0.0
Google 스마트 답장을 보거나 사용해 본 적이 있나요? 사용자 메시지에 대한 자동 답변 제안을 제공하는 서비스입니다. 아래를 참조하세요.
검색 기반 챗봇을 활용한 유용한 애플리케이션입니다. 생각해 보세요. 우리는 고맙습니다 , 안녕 , 또는 나중에 봐요 와 같은 메시지를 몇 번이나 보내나요? 이 프로젝트에서는 간단한 메시지 답장 제안 시스템을 구축합니다.
박규병
Yj Choi의 코드 검토
표시할 제안 목록을 설정해야 합니다. 당연히 빈도가 먼저 고려됩니다. 하지만 의미가 비슷한 문구는 어떻습니까? 예를 들어, 너무 감사 하고 독립적으로 대우 받아야 할까요? 우리는 그렇게 생각하지 않습니다. 우리는 그것들을 그룹화하고 슬롯을 저장하고 싶습니다. 어떻게? 우리는 병렬 코퍼스를 사용합니다. 둘 다 정말 감사합니다 . 감사합니다. 아마 같은 텍스트로 번역될 것 같습니다. 이러한 가정을 바탕으로 동일한 번역을 공유하는 영어 동의어 그룹을 구성합니다.
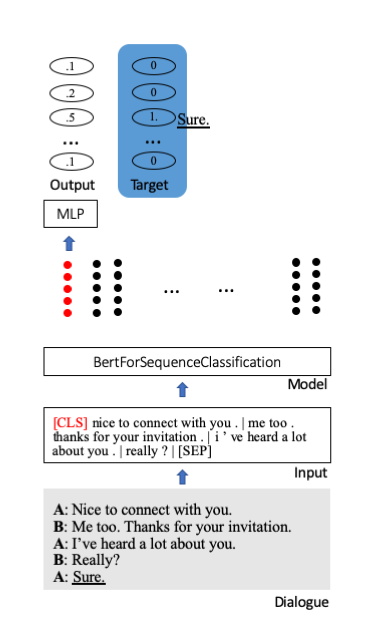
우리는 시퀀스 분류를 위해 Huggingface의 Bert 사전 훈련 모델을 미세 조정했습니다. 여기에는 특수 시작 토큰[CLS]이 문장의 전체 정보를 저장합니다. 압축된 정보를 분류 단위(여기서는 100)에 투영하기 위해 추가 레이어가 첨부됩니다.
우리는 OpenSubtitles 2018 스페인어-영어 병렬 코퍼스를 사용하여 동의어 그룹을 구성합니다. OpenSubtitles는 번역된 영화 자막의 대규모 컬렉션입니다. en-es 데이터는 61M개 이상의 정렬된 선으로 구성됩니다.
이상적으로는 훈련을 위해 (매우) 큰 대화 코퍼스가 필요하지만 우리는 이를 찾지 못했습니다. 대신 Cornell Movie Dialogue Corpus를 사용합니다. 83,097개의 대화, 304,713개의 대사로 구성되어 있습니다.
파이썬>=3.6
tqdm>=4.30.0
파이토치>=1.0
pytorch_pretrained_bert>=0.6.1
nltk>=3.4
0단계. OpenSubtitles 2018 스페인어-영어 병렬 데이터를 다운로드하세요.
bash download.sh
STEP 1. 말뭉치에서 동의어 그룹을 구성합니다.
python construct_sg.py
STEP 2. phr2sg_id 및 sg_id2phr 사전을 만듭니다.
python make_phr2sg_id.py
STEP 3. 단일 언어로 된 영어 텍스트를 ID로 변환합니다.
python encode.py
STEP 4. 훈련 데이터를 생성하고 피클에 저장합니다.
python prepro.py
5단계. 훈련.
python train.py
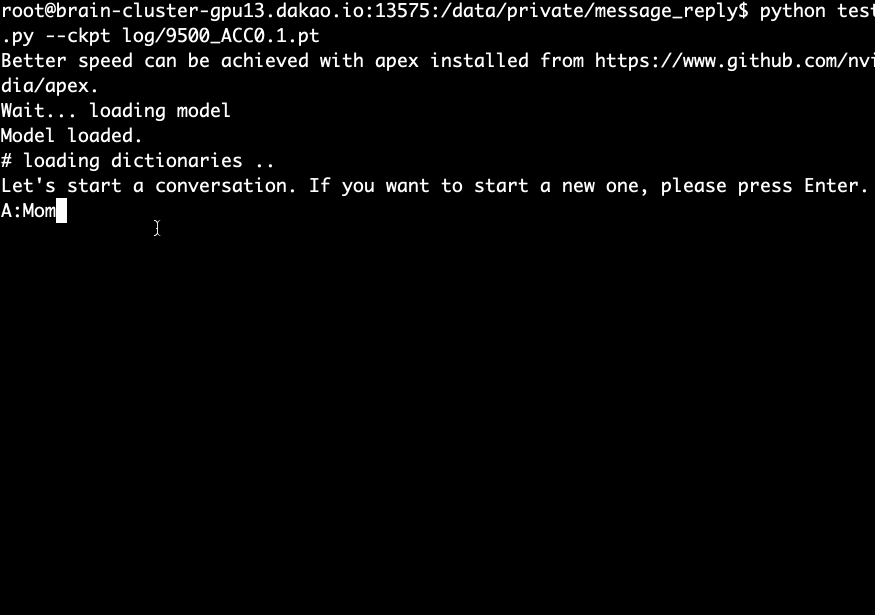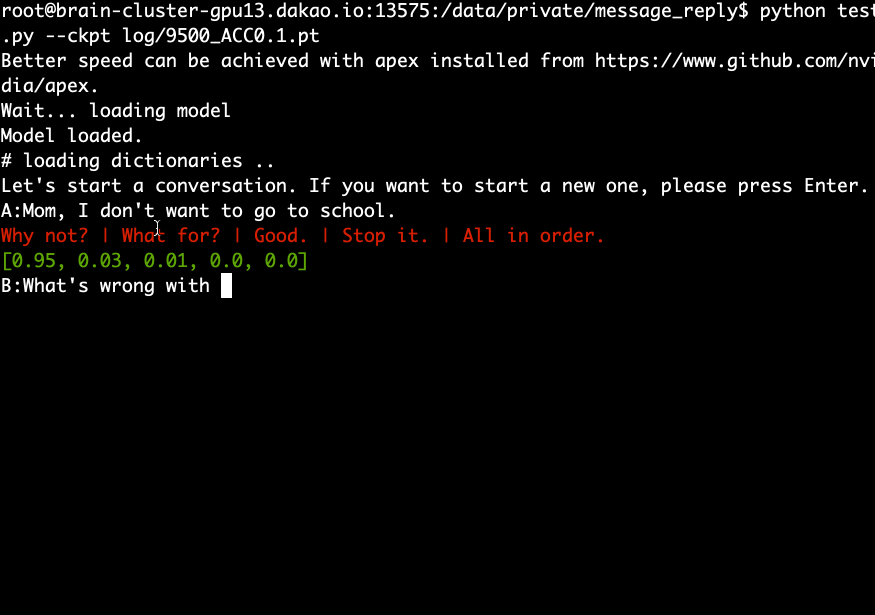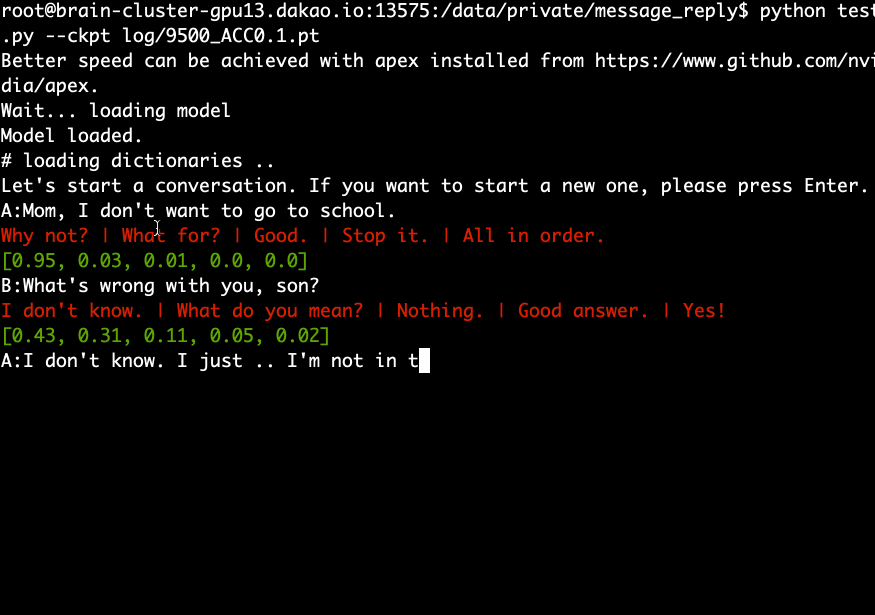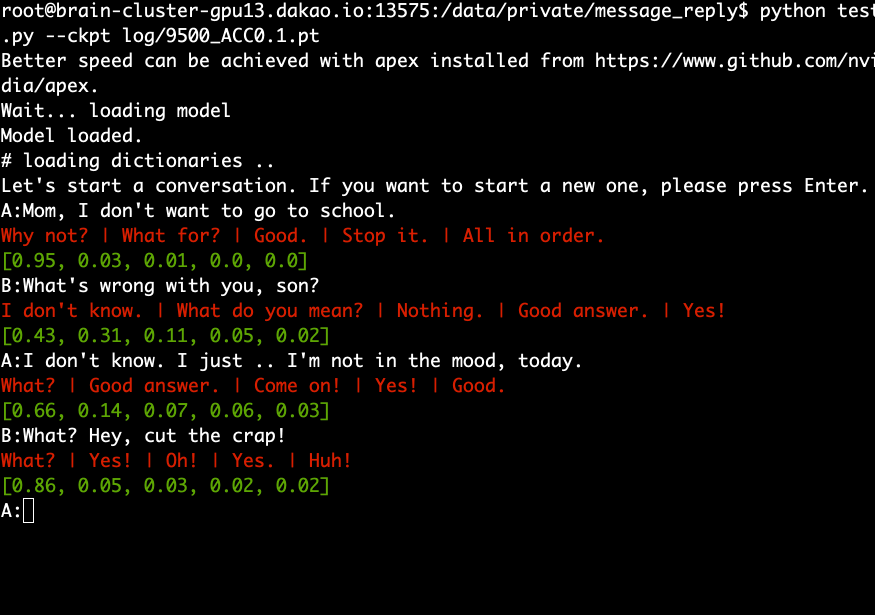
사전 훈련된 모델을 다운로드 및 추출하고 다음 명령을 실행합니다.
python test.py --ckpt log/9500_ACC0.1.pt
훈련 손실은 느리지만 꾸준히 감소합니다.
평가 데이터의 정확도@5는 10~20%입니다.
실제 적용을 위해서는 훨씬 더 큰 코퍼스가 필요합니다.
영화 대본이 메시지 대화와 얼마나 유사한지 잘 모르겠습니다.
동의어 그룹을 구성하기 위한 더 나은 전략이 필요합니다.
검색 기반 챗봇은 생성 기반 챗봇보다 간편하고 간편하기 때문에 현실적으로 활용 가능한 애플리케이션입니다.


