ThinkRAG
1.0.0
영어 | 중국어 간체
ThinkRAG 대형 모델 검색 향상 생성 시스템은 노트북에 쉽게 배포하여 로컬 지식 기반에서 지능적인 질문 답변을 실현할 수 있습니다.
시스템은 LlamaIndex와 Streamlit을 기반으로 구축되었으며 모델 선택, 텍스트 처리 등 여러 분야에서 국내 사용자에게 최적화되었습니다.
ThinkRAG는 전문가, 연구원, 학생 및 기타 지식 근로자를 위해 개발된 대규모 모델 응용 프로그램 시스템으로 노트북에서 직접 사용할 수 있으며 지식 기반 데이터는 컴퓨터에 로컬로 저장됩니다.
ThinkRAG에는 다음과 같은 기능이 있습니다:
특히 ThinkRAG는 국내 사용자를 위한 맞춤화와 최적화도 많이 해왔습니다.
ThinkRAG는 LlamaIndex 데이터 프레임이 지원하는 모든 모델을 사용할 수 있습니다. 모델 목록 정보는 관련 문서를 참조하세요.
ThinkRAG는 직접적으로 사용할 수 있고 유용하며 사용하기 쉬운 응용 프로그램 시스템을 만들기 위해 최선을 다하고 있습니다.
따라서 우리는 다양한 모델, 구성 요소 및 기술을 신중하게 선택하고 절충했습니다.
첫째, 대형 모델을 사용하여 ThinkRAG는 OpenAI API와 다음과 같은 국내 주류 대형 모델 제조업체를 포함한 모든 호환 LLM API를 지원합니다.
대형 모델을 로컬로 배포하려는 경우 ThinkRAG는 간단하고 사용하기 쉬운 Ollama를 선택합니다. Ollama를 통해 로컬로 실행할 대형 모델을 다운로드할 수 있습니다.
현재 Ollama는 Llama, Gemma, GLM, Mistral, Phi, Llava 등을 포함한 거의 모든 주류 대형 모델의 현지화된 배포를 지원합니다. 자세한 내용은 아래 올라마 공식 홈페이지를 방문해 주세요.
이 시스템은 또한 임베딩 모델과 재배열 모델을 사용하며 Hugging Face의 대부분의 모델을 지원합니다. 현재 ThinkRAG는 BAAI의 BGE 시리즈 모델을 주로 사용하고 있습니다. 국내 사용자는 미러 웹사이트를 방문하여 학습하고 다운로드할 수 있습니다.
Github에서 코드를 다운로드한 후 pip를 사용하여 필수 구성 요소를 설치합니다.
pip3 install -r requirements.txt시스템을 오프라인으로 실행하려면 먼저 공식 웹사이트에서 Ollama를 다운로드하세요. 그런 다음 Ollama 명령을 사용하여 GLM, Gemma 및 QWen과 같은 대규모 모델을 다운로드합니다.
동기적으로, Hugging Face에서 임베딩 모델(BAAI/bge-large-zh-v1.5) 및 재순위 모델(BAAI/bge-reranker-base)을 localmodels 디렉터리로 다운로드합니다.
구체적인 단계는 docs 디렉터리의 HowToDownloadModels.md 문서를 참조하세요.
더 나은 성능을 얻으려면 수천억 개의 매개변수가 있는 상용 대형 모델 LLM API를 사용하는 것이 좋습니다.
먼저 LLM 서비스 제공자로부터 API 키를 받아 다음 환경 변수를 구성합니다.
ZHIPU_API_KEY = " "
MOONSHOT_API_KEY = " "
DEEPSEEK_API_KEY = " "
OPENAI_API_KEY = " "이 단계를 건너뛰고 시스템이 실행된 후 애플리케이션 인터페이스를 통해 API 키를 구성할 수 있습니다.
하나 이상의 LLM API를 사용하기로 선택한 경우 config.py 구성 파일에서 더 이상 사용하지 않는 서비스 제공자를 삭제하세요.
물론 구성 파일에 OpenAI API와 호환되는 다른 서비스 제공자를 추가할 수도 있습니다.
ThinkRAG는 기본적으로 개발 모드에서 실행됩니다. 이 모드에서는 시스템이 로컬 파일 저장소를 사용하므로 데이터베이스를 설치할 필요가 없습니다.
프로덕션 모드로 전환하려면 다음과 같이 환경 변수를 구성하면 됩니다.
THINKRAG_ENV = production프로덕션 모드에서 시스템은 벡터 데이터베이스 Chroma와 키-값 데이터베이스 Redis를 사용합니다.
Redis가 설치되어 있지 않은 경우 Docker를 통해 설치하거나 기존 Redis 인스턴스를 사용하는 것이 좋습니다. config.py 파일에서 Redis 인스턴스의 파라미터 정보를 설정해 주세요.
이제 ThinkRAG를 실행할 준비가 되었습니다.
app.py 파일이 포함된 디렉터리에서 다음 명령을 실행하세요.
streamlit run app.py시스템이 실행되고 자동으로 브라우저에서 다음 URL을 열어 애플리케이션 인터페이스를 표시합니다.
http://localhost:8501/
첫 번째 실행에는 시간이 걸릴 수 있습니다. Hugging Face에 내장된 모델을 미리 다운로드하지 않으면 시스템이 자동으로 모델을 다운로드하므로 더 오래 기다려야 합니다.
ThinkRAG는 대형 모델 LLM API의 기본 URL 및 API 키를 포함하여 사용자 인터페이스에서 대형 모델의 구성 및 선택을 지원하며 사용할 특정 모델을 선택할 수 있습니다(예: ThinkRAG의 glm-4).
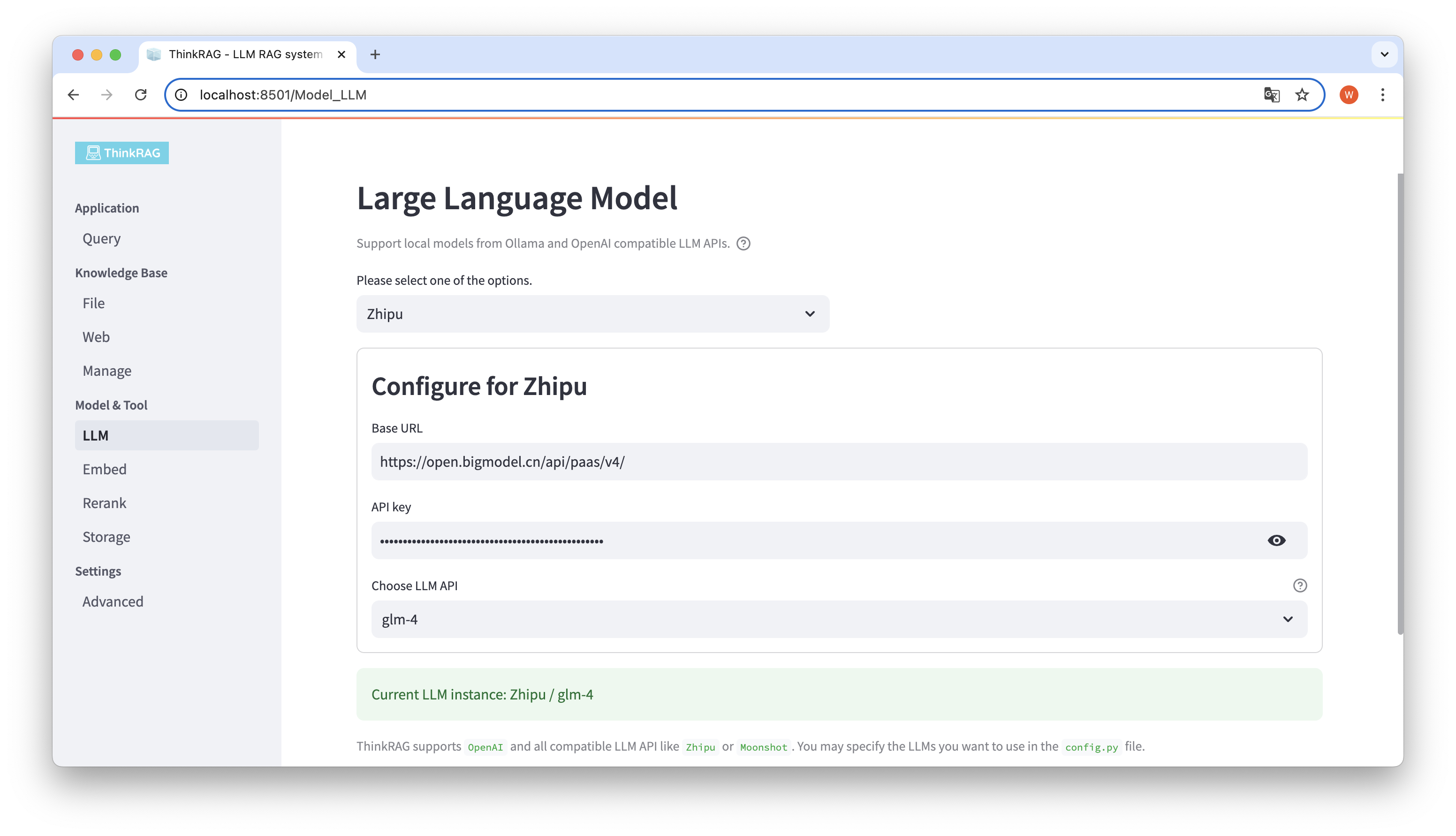
시스템은 API와 키를 사용할 수 있는지 자동으로 감지합니다. 사용 가능한 경우 현재 선택된 대형 모델 인스턴스가 하단에 녹색 텍스트로 표시됩니다.
마찬가지로 시스템은 Ollama가 다운로드한 모델을 자동으로 얻을 수 있으며, 사용자는 사용자 인터페이스에서 원하는 모델을 선택할 수 있습니다.
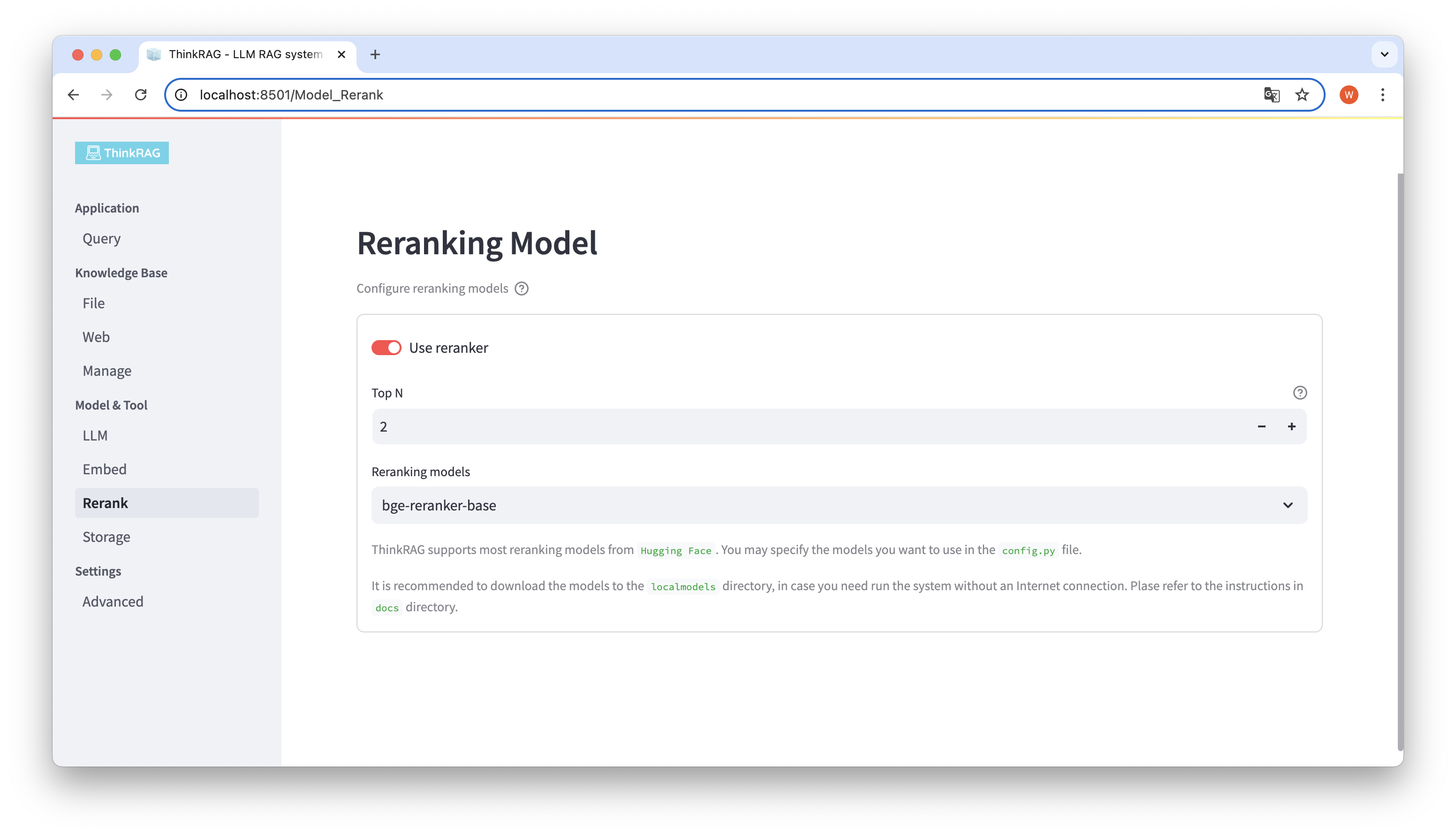
내장된 모델을 다운로드하고 모델을 로컬 localmodels 디렉터리에 재배열한 경우. 사용자 인터페이스에서는 선택한 모델을 전환하고 Top N과 같은 재배열된 모델의 매개변수를 설정할 수 있습니다.
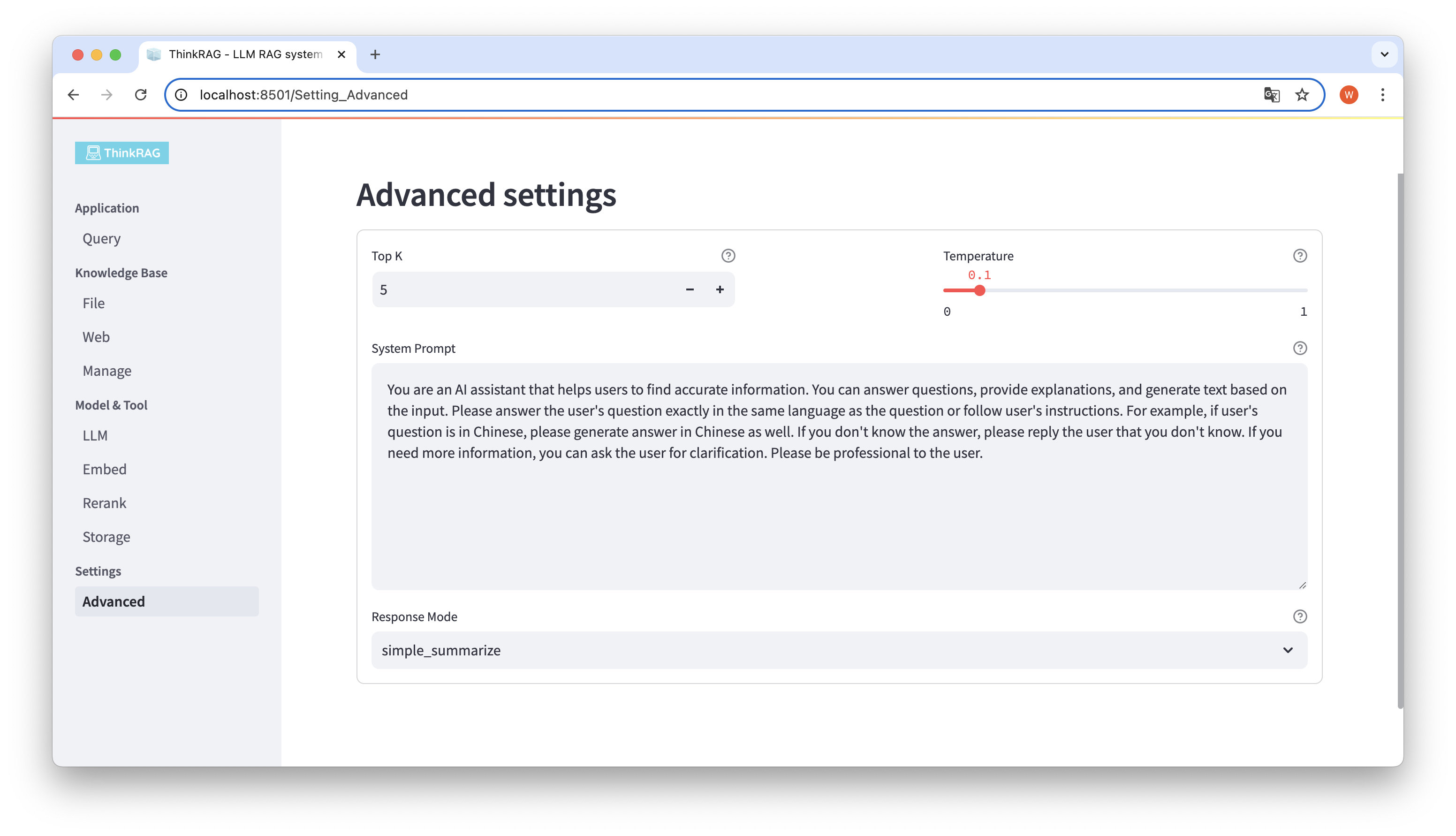
왼쪽 탐색 모음에서 고급 설정(설정-고급)을 클릭합니다. 다음 매개변수도 설정할 수 있습니다.
다양한 매개변수를 사용하여 대규모 모델 출력을 비교하고 가장 효과적인 매개변수 조합을 찾을 수 있습니다.
ThinkRAG는 PDF, DOCX, PPTX 등 다양한 파일 업로드를 지원하며 웹페이지 URL 업로드도 지원합니다.
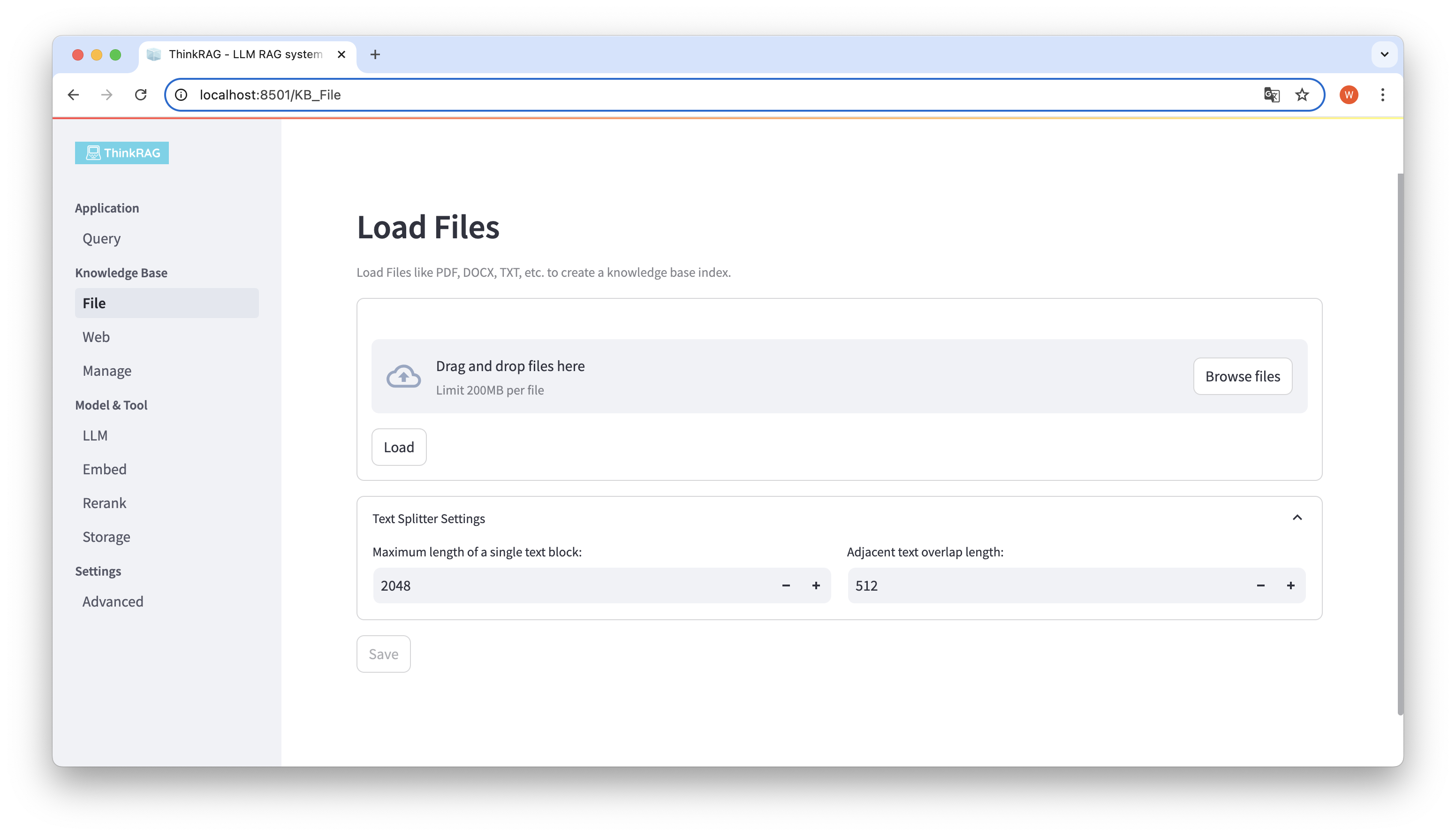
파일 찾아보기 버튼을 클릭하고 컴퓨터에서 파일을 선택한 다음 로드 버튼을 클릭하면 로드된 모든 파일이 나열됩니다.
그런 다음 저장 버튼을 클릭하면 시스템이 텍스트 분할 및 포함을 포함하여 파일을 처리하고 지식 베이스에 저장합니다.
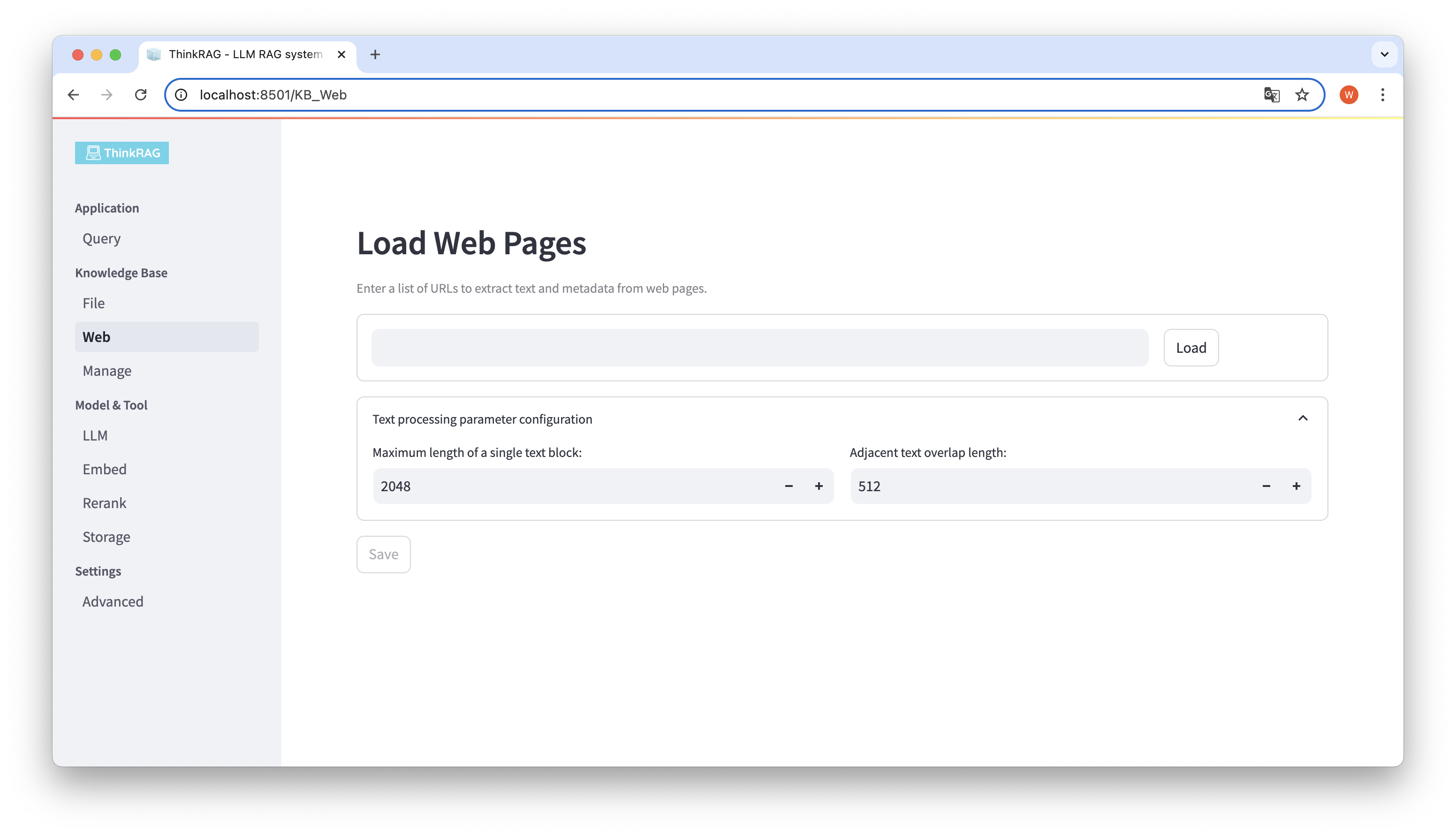
마찬가지로 웹페이지 URL을 입력하거나 붙여넣고, 웹페이지 정보를 얻고, 처리 후 지식 베이스에 저장할 수 있습니다.
이 시스템은 지식베이스 관리를 지원합니다.
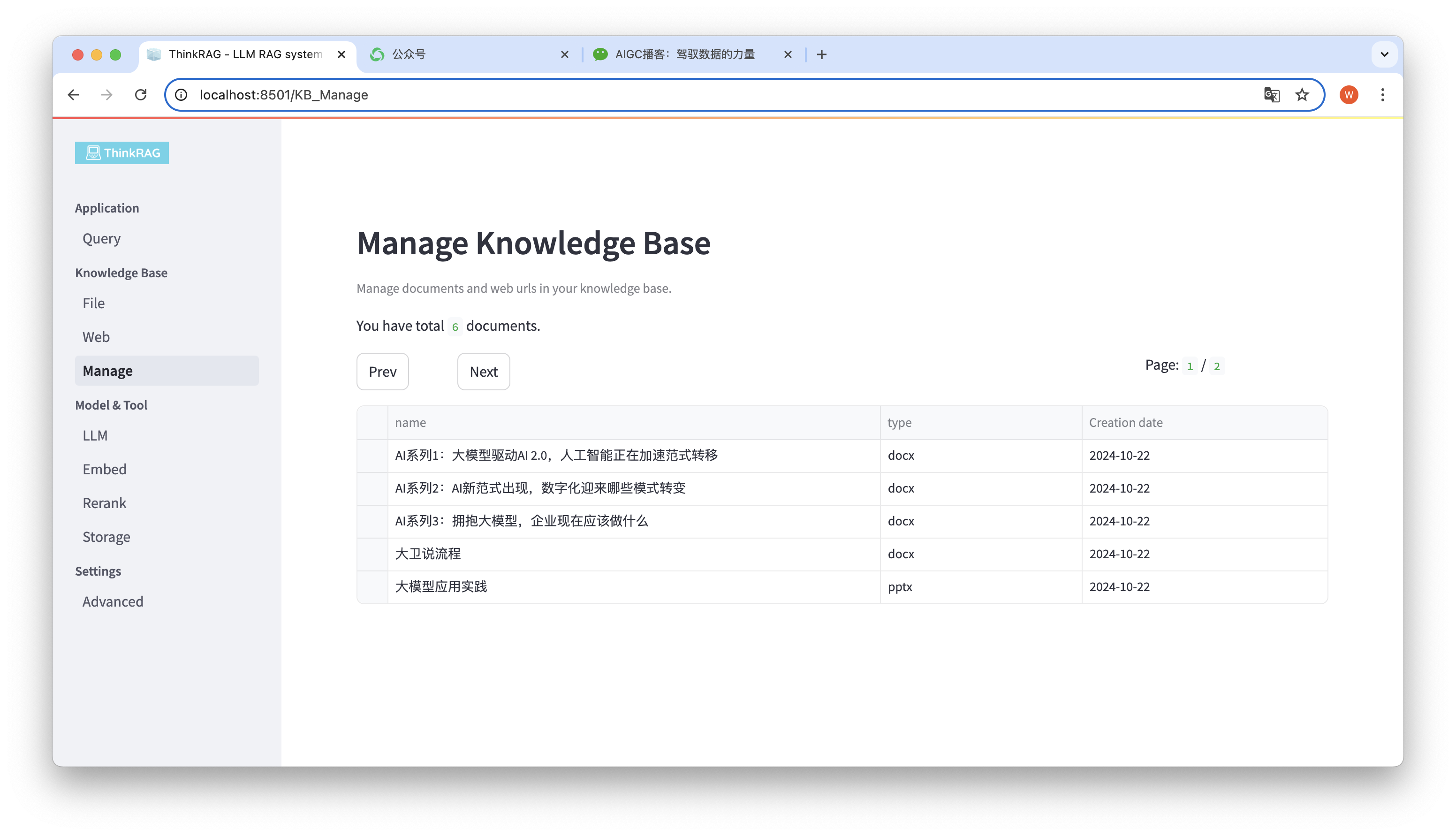
위 그림에 표시된 것처럼 ThinkRAG는 지식 베이스의 모든 문서를 페이지 단위로 나열할 수 있습니다.
삭제할 문서를 선택하면 선택한 문서 삭제 버튼이 나타납니다. 이 버튼을 클릭하면 지식 베이스에서 문서가 삭제됩니다.
왼쪽 탐색 모음에서 쿼리를 클릭하면 지능형 Q&A 페이지가 나타납니다.
질문을 입력하면 시스템이 지식 베이스를 검색하여 답변을 제공합니다. 이 프로세스 동안 시스템은 지식 기반에서 정확한 콘텐츠를 얻기 위해 하이브리드 검색 및 재배열과 같은 기술을 사용합니다.
예를 들어 지식 베이스에 "David Says Process.docx"라는 Word 문서를 업로드했습니다.
이제 "프로세스의 세 가지 특성은 무엇입니까?"라는 질문을 입력해 보세요.
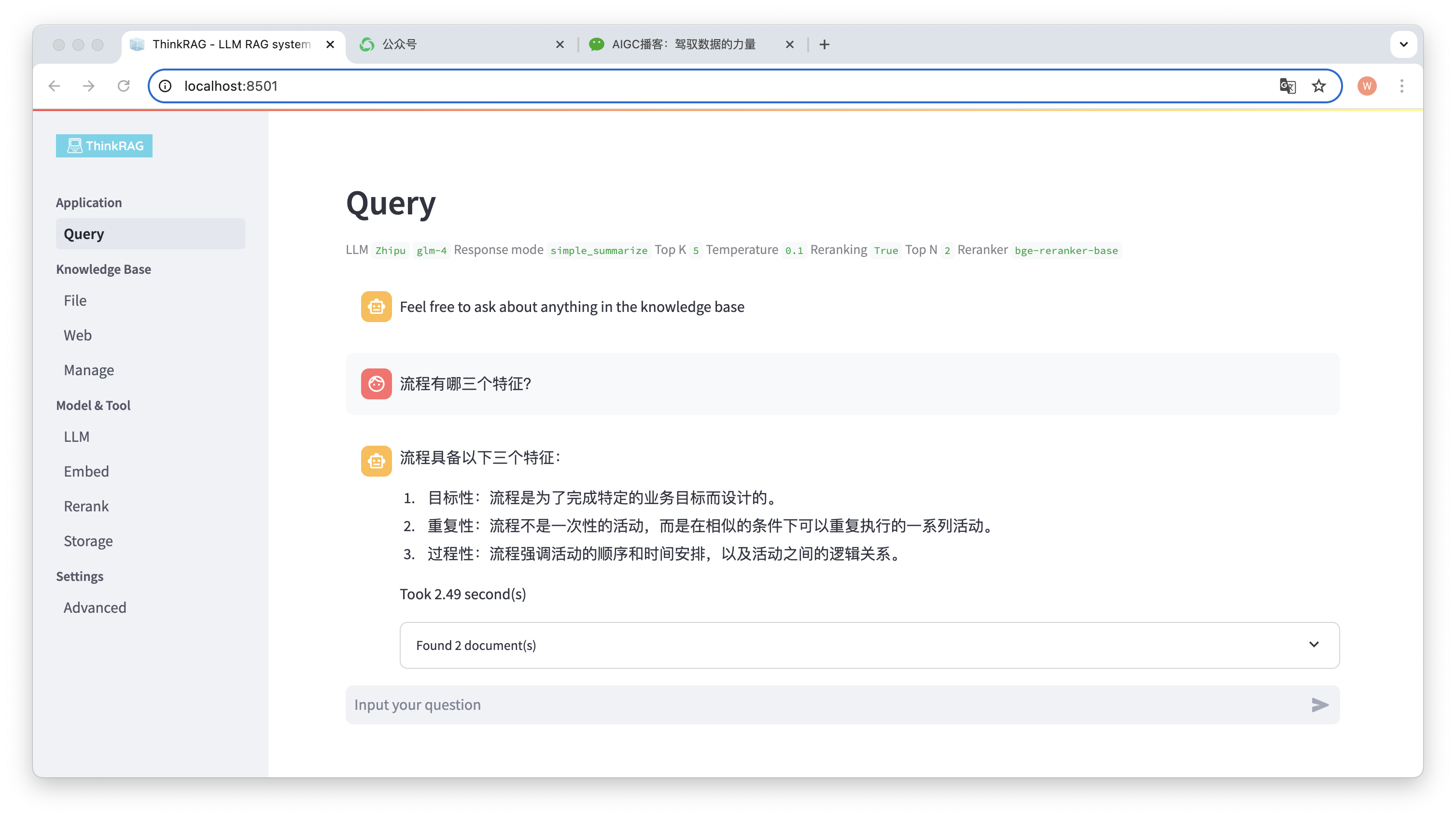
그림에서 볼 수 있듯이 시스템은 정확한 답변을 제공하는 데 2.49초가 걸렸습니다. 프로세스는 대상이 지정되고 반복적이며 절차적입니다. 동시에 시스템은 지식 베이스에서 검색된 2개의 관련 문서도 제공합니다.
ThinkRAG는 로컬 지식 기반을 기반으로 향상된 대규모 모델 검색 생성 기능을 완전하고 효과적으로 구현하는 것을 볼 수 있습니다.
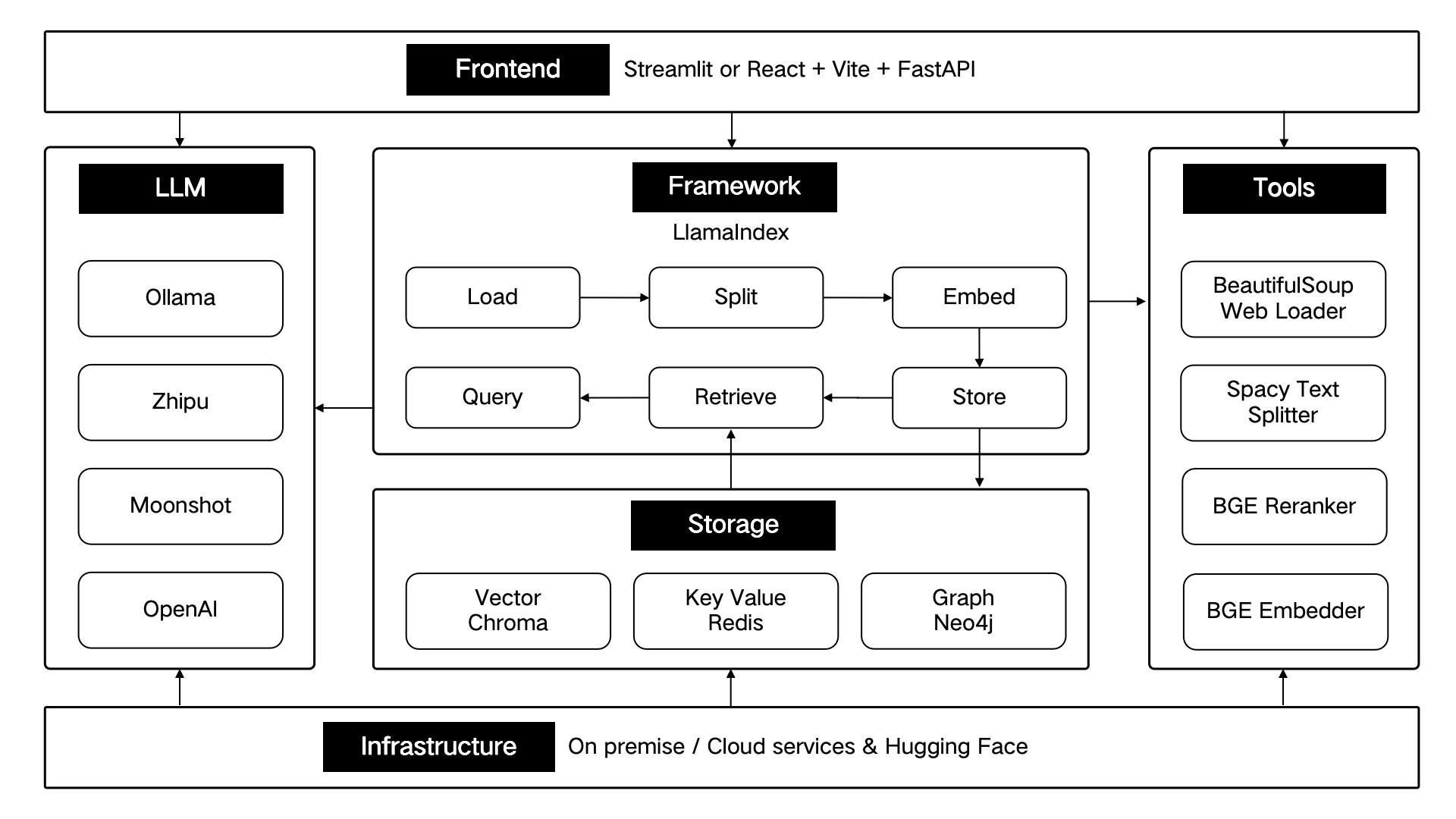
ThinkRAG는 LlamaIndex 데이터 프레임워크를 사용하여 개발되었으며 프런트엔드에 Streamlit을 사용합니다. 시스템의 개발 모드와 생산 모드는 다음 표에 표시된 것처럼 각각 다른 기술 구성 요소를 사용합니다.
| 개발 모드 | 생산 모드 | |
|---|---|---|
| RAG 프레임워크 | 라마인덱스 | 라마인덱스 |
| 프론트엔드 프레임워크 | 스트림라이트 | 스트림라이트 |
| 임베디드 모델 | BAAI/bge-small-zh-v1.5 | BAAI/bge-large-zh-v1.5 |
| 모델을 재배열하다 | BAAI/bge-reranker-base | BAAI/bge-reranker-대형 |
| 텍스트 분할기 | 문장분할기 | SpacyTextSplitter |
| 대화 저장 | 심플챗스토어 | 레디스 |
| 문서 보관 | SimpleDocumentStore | 레디스 |
| 인덱스 저장 | SimpleIndexStore | 레디스 |
| 벡터 저장 | SimpleVectorStore | 랜스DB |
이러한 기술 구성 요소는 프런트엔드, 프레임워크, 대규모 모델, 도구, 스토리지 및 인프라의 6개 부분에 따라 구조적으로 설계되었습니다.
아래와 같이:
ThinkRAG는 계속해서 핵심 기능을 최적화하고 주로 다음을 포함하여 검색의 효율성과 정확성을 지속적으로 개선할 것입니다.
동시에 우리는 주로 다음을 포함하여 애플리케이션 아키텍처를 더욱 개선하고 사용자 경험을 향상할 것입니다.
ThinkRAG 오픈 소스 프로젝트에 참여하여 함께 협력하여 사용자가 좋아하는 AI 제품을 만들 수 있습니다!
ThinkRAG는 MIT 라이센스를 사용합니다.


