multi agent reasoning
1.0.0
여러 AI 에이전트가 협력하여 사용자 프롬프트에 대한 최적의 응답을 생성하는 다중 에이전트 추론을 사용하는 Python 기반 솔루션입니다. 에이전트 간의 상호 작용을 시뮬레이션하고 Swarm Framework for Intelligence를 통합함으로써 시스템은 추론 기능을 향상시켜 정확하고 세련된 답변을 제공합니다. 사용자 지정 에이전트는 JSON을 통해 추가할 수 있으므로 성격, 상호 작용 스타일 등을 사용자 지정할 수 있습니다. 시스템은 프롬프트 캐싱을 활용하여 성능을 최적화하고 반복되는 프롬프트에 대한 대기 시간과 비용을 줄입니다.

다중 에이전트 추론 스크립트는 구조화된 추론 프로세스를 통해 여러 AI 에이전트가 협력하여 최적의 답변을 제공하는 대화형 챗봇 경험을 생성합니다. 각 상담원은 고유한 관점과 전문 지식을 제공하며 토론, 검증, 비평 및 개선의 반복적인 단계를 통해 고품질의 정확한 응답에 수렴됩니다.
또한 시스템은 Swarm Framework for Intelligence를 통합하여 에이전트 간의 협업을 향상시킵니다. Swarm을 사용하면 에이전트가 효율적으로 조정하고 집단 지능을 활용하여 복잡한 작업을 해결할 수 있습니다.
사용자는 개별 상담원과 채팅 할 수도 있습니다. 상담원은 성격과 특이성을 포함하여 서로를 인식하고 서로에 대한 질문에 답변할 수 있어 풍부하고 상호 작용적인 경험을 제공할 수 있습니다.
저장소를 복제하십시오 .
git clone https://github.com/AdieLaine/multi-agent-reasoning.git프로젝트 디렉터리로 이동합니다 .
cd multi-agent-reasoning필수 패키지를 설치하십시오 .
pip install openai colorama tiktoken스웜 설치:
pip install git+ssh://[email protected]/openai/swarm.git
or
pip install git+https://github.com/openai/swarm.git자세한 설치 지침은 Swarm의 GitHub 저장소를 참조하세요.
OpenAI API 키를 설정하세요 .
API 키를 환경 변수로 설정합니다.
export OPENAI_API_KEY= ' your-api-key-here ' 또는 스크립트에서 직접 설정하거나 .env 파일을 사용할 수 있습니다.
Python을 사용하여 스크립트를 실행합니다.
python reasoning.py스크립트를 실행하면 다음 메뉴가 표시됩니다.
═════════════════════════════════════════════════════════════════════════════════════════════
║ Multi-Agent Reasoning Chatbot ║
═════════════════════════════════════════════════════════════════════════════════════════════
Please select an option:
1. Chat with an agent
2. Use reasoning logic
3. Use Swarm-based reasoning
4. Exit
Enter your choice (1/2/3/4):
옵션 1: 상담원과 채팅
옵션 2: 추론 논리 사용
옵션 3: Swarm 기반 추론 사용
옵션 4: 종료
다중 에이전트 추론 시스템은 특정 OpenAI 모델을 사용합니다.
o1-preview-2024-09-12 모델을 사용합니다.gpt-4o 모델을 사용합니다.gpt-4o 입니다.이러한 모델은 고급 기능과 토큰 사용 보고를 지원하므로 시스템은 각 응답 후에 자세한 토큰 사용 정보를 제공할 수 있습니다.
목표 : 사용자가 선택한 상담원과 직접 채팅할 수 있습니다.
예 :
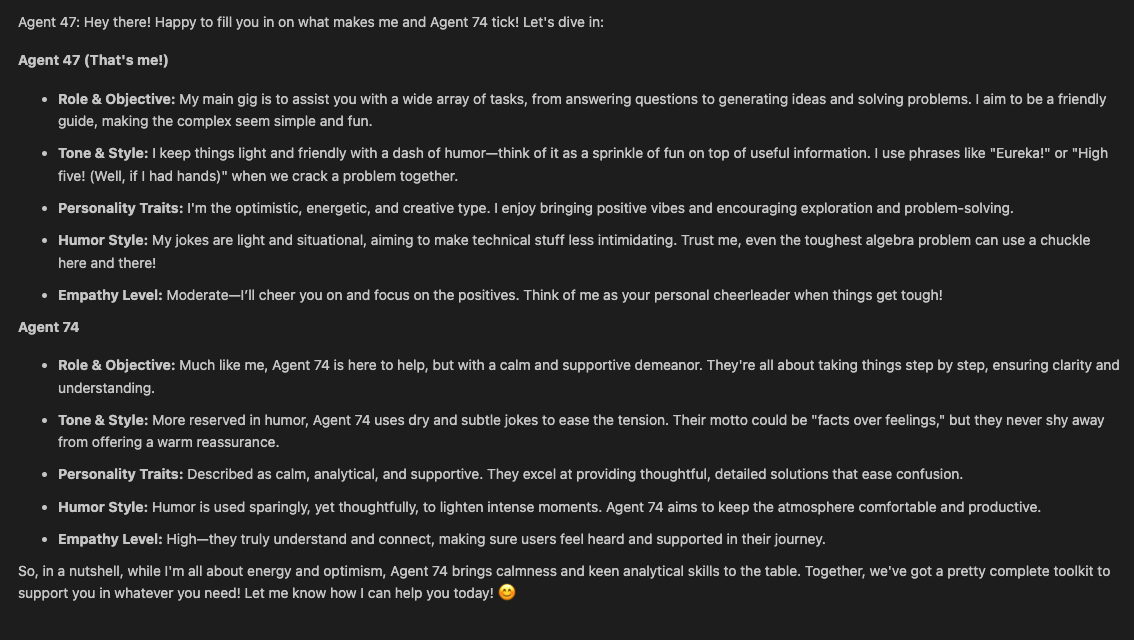
챗봇 기능의 핵심은 에이전트가 사용하는 추론 프로세스에 있습니다. 이 프로세스는 상담원이 비판적으로 생각하고, 사실을 확인하고, 서로의 관점에 이의를 제기하고, 건설적인 피드백을 기반으로 응답을 개선하는 협업 환경을 시뮬레이션하도록 설계되었습니다.
목표 : 상담원은 개인의 추론과 지식을 바탕으로 사용자의 프롬프트에 대한 초기 응답을 생성합니다.
예 :
목표 : 상담원은 사실의 정확성을 보장하기 위해 자신의 응답의 정확성과 타당성을 확인합니다.
예 :
목표 : 상담원은 서로의 확인된 답변을 비판하여 개선, 누락 또는 편견 영역을 식별합니다.
예 :
목표 : 에이전트는 비평의 피드백을 통합하고 초기 추론을 개선하여 자신의 응답을 개선합니다.
예 :
목표 : 모든 상담원의 세련된 답변을 하나의 응집력 있고 포괄적인 답변으로 결합합니다.
blend_responses 함수를 사용하여 혼합됩니다.예 :
목표 : 사용자의 피드백을 통합하여 응답을 더욱 구체화하고 만족도와 정확성을 보장합니다.
MAX_REFINEMENT_ATTEMPTS .예 :
목표 : 일관된 대화를 위해 대화가 여러 사용자 프롬프트에서 컨텍스트를 유지할 수 있도록 합니다.
예 :
Swarm Integration은 동적 에이전트 조정 및 작업 위임을 활성화하여 다중 에이전트 추론 시스템을 향상시킵니다. Swarm을 사용하면 에이전트가 효율적으로 협업하고 집단 지능을 활용하여 복잡한 작업을 해결하고 응답성을 향상할 수 있습니다.
Swarm은 에이전트 조정 및 실행을 가볍고 제어 가능하며 쉽게 테스트할 수 있도록 만드는 데 중점을 둡니다. 이는 에이전트 와 핸드오프라는 두 가지 기본 추상화를 통해 달성됩니다. 에이전트에는 지침과 도구가 포함되어 있으며 언제든지 대화를 다른 에이전트에게 전달하도록 선택할 수 있습니다.

Swarm 클라이언트 초기화 : 시스템은 Swarm 클라이언트를 초기화하여 에이전트 상호 작용을 관리합니다.
from swarm import Agent , Swarm
client = Swarm ()에이전트 초기화 :
agents.json 의 구성이 통합됩니다.대화 처리 :
목표 : Swarm Framework for Intelligence를 활용하여 에이전트를 동적으로 조정하여 효율적인 협업 및 작업 위임을 가능하게 합니다.
초기화 :
agents.json 구성 파일에서 에이전트를 로드하고 초기화합니다.논의 :
client.run() 메서드를 사용하여 사용자 프롬프트에 대한 초기 응답을 제공합니다.확인 :
비평 :
개선 :
혼합 응답 :
blend_responses 기능을 사용하여 에이전트의 정제된 응답을 응집력 있는 최종 답변으로 혼합하는 작업을 조정합니다.예 :
목표 : 원활한 상담원 상호 작용을 위해 Swarm의 기능을 활용하는 채팅 인터페이스를 제공합니다.
채팅용 스웜 에이전트 :
대화 처리 :
def swarm_chat_interface ( conversation_history ):
# Load Swarm agent's configuration
swarm_agent = ... # Initialize Swarm agent
messages = [{ "role" : "system" , "content" : swarm_agent . instructions }]
messages . extend ( conversation_history )
response = client . run ( agent = swarm_agent , messages = messages )
swarm_reply = response . messages [ - 1 ][ 'content' ]. strip ()
return swarm_reply동적 응답 :
예 :
에이전트 디자인 :
기능 정의 :
컨텍스트 변수 :
오류 처리 :
테스트 :
Swarm은 무엇이며 시스템을 어떻게 향상시키나요?
Swarm과 함께 작동하려면 기존 에이전트를 수정해야 합니까?
Agent 인스턴스로 정의되어야 합니다. 기존 에이전트는 Swarm의 구조와 규칙을 통합하여 조정할 수 있습니다.Swarm 시스템에 에이전트를 더 추가할 수 있나요?
agents.json 파일에 추가 에이전트를 정의하고 시스템에서 초기화할 수 있습니다.Swarm은 에이전트 핸드오프를 어떻게 처리합니까?
Swarm은 시스템에 사용되는 모델과 호환됩니까?
gpt-4o 입니다. 프롬프트 캐싱은 반복되거나 긴 프롬프트를 처리할 때 대기 시간과 비용을 줄여 다중 에이전트 추론 시스템의 효율성을 향상시킵니다. 프롬프트의 가장 긴 공통 접두사를 캐싱하여 이러한 접두사를 재사용하는 후속 요청을 더 빠르게 처리할 수 있습니다.
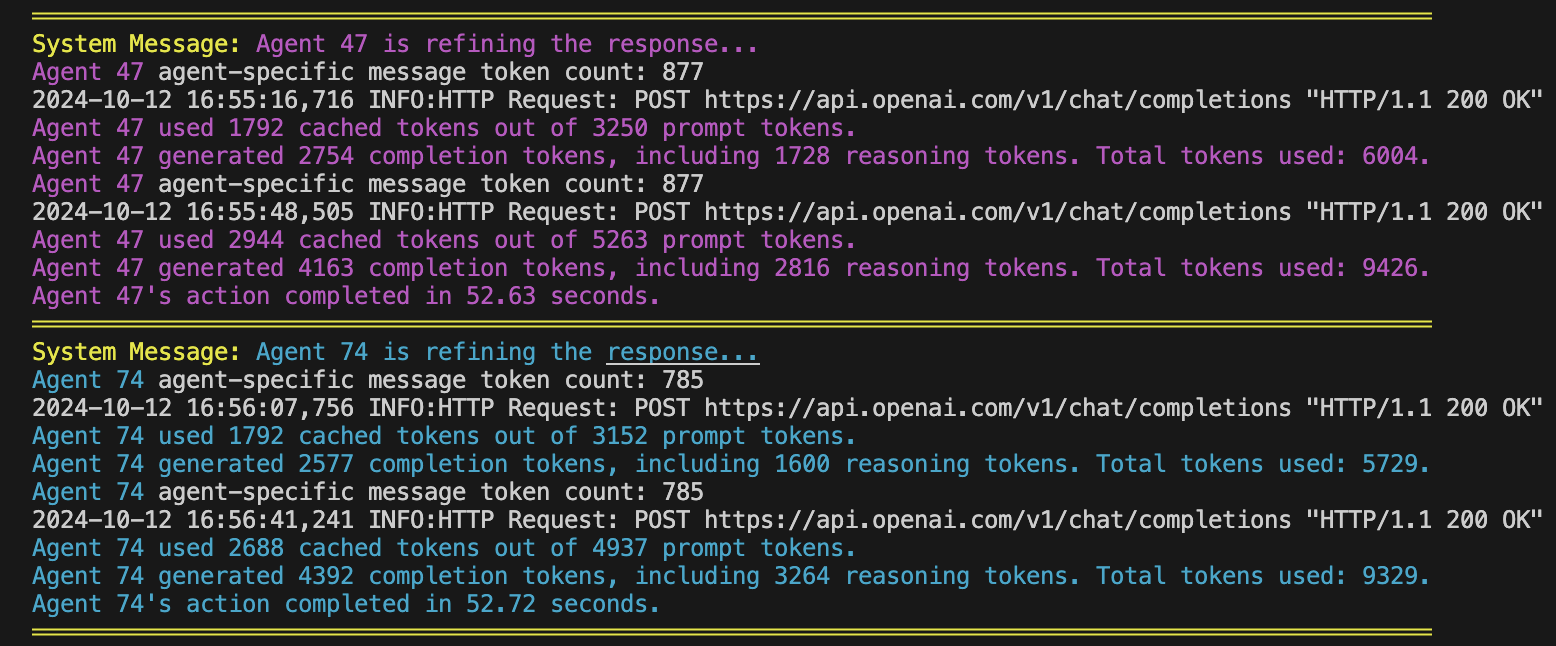
캐시 기간 :
usage 필드가 포함되어 있습니다. "usage" : {
"prompt_tokens" : 2006 ,
"completion_tokens" : 300 ,
"total_tokens" : 2306 ,
"prompt_tokens_details" : {
"cached_tokens" : 1920
},
"completion_tokens_details" : {
"reasoning_tokens" : 0
}
}cached_tokens 캐시에서 검색된 프롬프트 토큰 수를 나타냅니다. 에이전트는 agents.json 파일을 통해 구성되므로 해당 속성을 쉽게 사용자 정의할 수 있습니다.
위치 : reasoning.py 스크립트와 동일한 디렉터리에 있어야 합니다.
구조 :
{
"agents" : [
{
"name" : " Agent 47 " ,
"system_purpose" : " You are a logical and analytical assistant, focusing on facts and clear reasoning. " ,
"interaction_style" : { ... },
"ethical_conduct" : { ... },
"capabilities_limitations" : { ... },
"context_awareness" : { ... },
"adaptability_engagement" : { ... },
"responsiveness" : { ... },
"additional_tools_modules" : { ... },
"personality" : {
"logical" : " Yes " ,
"analytical" : " Yes " ,
"humor_style" : " ... " ,
"friendly_demeanor" : " ... " ,
"personality_traits" : [ " Methodical " , " Precise " ],
"empathy_level" : " Moderate " ,
"interaction_style_with_humor" : " Dry wit " ,
"quirks" : [ " Uses technical jargon " ]
}
},
{
"name" : " Agent 74 " ,
"system_purpose" : " You are a creative and empathetic assistant, emphasizing imaginative solutions and understanding. " ,
"interaction_style" : { ... },
"ethical_conduct" : { ... },
"capabilities_limitations" : { ... },
"context_awareness" : { ... },
"adaptability_engagement" : { ... },
"responsiveness" : { ... },
"additional_tools_modules" : { ... },
"personality" : {
"creative" : " Yes " ,
"empathetic" : " Yes " ,
"humor_style" : " ... " ,
"friendly_demeanor" : " ... " ,
"personality_traits" : [ " Imaginative " , " Caring " ],
"empathy_level" : " High " ,
"interaction_style_with_humor" : " Playful " ,
"quirks" : [ " Uses metaphors " ]
}
},
{
"name" : " Swarm Agent " ,
"system_purpose" : " You are a collaborative AI assistant composed of multiple expert agents. You coordinate tasks among agents to provide comprehensive and accurate responses. " ,
"interaction_style" : { ... },
"personality" : {
"coordinator" : " Yes " ,
"collaborative" : " Yes " ,
"personality_traits" : [ " Organized " , " Facilitator " ],
"quirks" : [ " Ensures all perspectives are considered " ]
}
}
]
}사용자 정의 :
예 :
코드는 추론 프로세스와 상담원과의 채팅 상호 작용을 모두 촉진하도록 구성되어 있습니다. 또한 향상된 에이전트 조정을 위해 Swarm Framework를 통합합니다.
도서관 :
os , time , logging , json : 시스템 작업, 타이밍, 로깅 및 JSON 처리용입니다.colorama : 컬러 콘솔 출력용입니다.swarm : Swarm Intelligence를 구현하기 위한 것입니다.tiktoken : 정확한 토큰 계산을 위해(스크립트의 다른 부분에서)초기화 :
from swarm import Agent , Swarm
client = Swarm () 에이전트는 agents.json 구성 파일에서 초기화됩니다.
각 에이전트는 특정 지침과 속성을 가진 Swarm Agent 인스턴스로 생성됩니다.
에이전트는 지침에 다른 에이전트에 대한 정보를 추가하여 서로를 인식합니다.
def initialize_swarm_agents ():
# Load agents from agents.json and create Swarm agents
agents = []
# ... Load and initialize agents with awareness of others
return agents 기능 : swarm_chat_interface(conversation_history)
목적 : Swarm 에이전트와의 채팅 상호작용을 처리합니다.
프로세스 :
def swarm_chat_interface ( conversation_history ):
# Prepare messages
messages = [{ "role" : "system" , "content" : swarm_agent . instructions }]
messages . extend ( conversation_history )
# Run Swarm client
response = client . run ( agent = swarm_agent , messages = messages )
swarm_reply = response . messages [ - 1 ][ 'content' ]. strip ()
return swarm_reply 기능 : run_swarm_reasoning(user_prompt)
목적 : Swarm 에이전트를 사용하여 여러 추론 단계에 따라 사용자 프롬프트에 협력하고 응답합니다.
프로세스 :
blend_responses 함수는 정제된 응답을 최종 답변으로 결합합니다.병렬 처리 : Swarm을 사용하면 에이전트가 이러한 단계를 동시에 수행하여 효율성을 높일 수 있습니다.
블렌딩 기능의 예 :
def blend_responses ( agent_responses , user_prompt ):
# Prepare combined prompt
combined_prompt = ...
# Initialize Blender agent
blender_agent = Agent (
name = "Swarm Agent" ,
instructions = "You are a collaborative AI assistant composed of multiple expert agents."
)
# Run blending process
response = client . run ( agent = blender_agent , messages = [{ "role" : "user" , "content" : combined_prompt }])
blended_reply = response . messages [ - 1 ][ 'content' ]
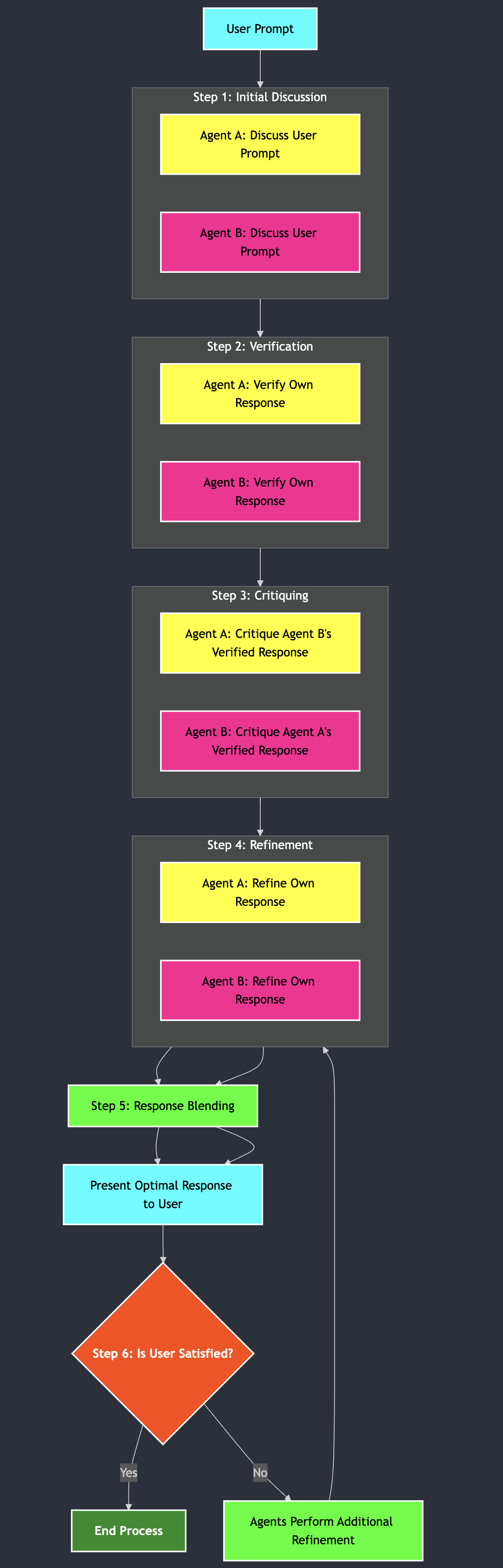
return blended_replyswarm_middle_agent_interface(user_prompt) :run_swarm_reasoning 호출합니다.swarm_chat_interface(conversation_history) :다음은 채팅 모드, 에이전트의 서로 인식, 토큰 사용 투명성, 프롬프트 캐싱 및 Swarm 통합을 포함한 새로운 로직을 반영하는 업데이트된 순서도입니다.
기여를 환영합니다! 기여하려면:
이 프로젝트는 MIT 라이선스에 따라 라이선스가 부여됩니다.
GitHub 저장소를 준비하려면 다음 안내를 따르세요.
multi-agent-reasoning 이라는 이름의 GitHub에 새 저장소를 만듭니다 .
이 내용이 포함된 README.md 파일을 추가하세요 .
루트 디렉터리에 reasoning.py 스크립트를 포함합니다 .
루트 디렉터리에 agents.json 파일을 포함합니다 .
불필요한 파일을 제외하려면 .gitignore 파일을 만듭니다 .
# Exclude log files
reasoning.log
swarm_middle_agent.log
# Exclude environment files
.env
# Python cache
__pycache__ /
* .py [ cod ]파일을 GitHub에 커밋하고 푸시합니다 .
multi-agent-reasoning/
├── README.md
├── reasoning.py
├── swarm_middle_agent.py
├── agents.json
├── LICENSE
├── .gitignore
└── img/
├── reasoningbanner.png
├── reasoningflow.png
├── agents.png
└── promptcache.png
└── swarm.png
자유롭게 코드를 탐색하고, 에이전트를 사용자 정의하고, 다중 에이전트 추론 챗봇에 참여해 보세요!
질문이 있거나 도움이 필요하면 GitHub에서 문제를 열어주세요.


