featuretools
v1.31.0
"머신러닝의 성배 중 하나는 기능 엔지니어링 프로세스를 점점 더 자동화하는 것입니다." ― Pedro Domingos, 머신러닝에 대해 알아야 할 몇 가지 유용한 사항

Featuretools는 자동화된 기능 엔지니어링을 위한 Python 라이브러리입니다. 자세한 내용은 설명서를 참조하세요.
pip로 설치
python -m pip install featuretools
또는 conda의 Conda-forge 채널에서:
conda install -c conda-forge featuretools
다음을 실행하여 추가 기능을 개별적으로 또는 한꺼번에 설치할 수 있습니다.
python -m pip install "featuretools[complete]"
프리미엄 프리미티브 - 프리미엄 프리미티브 저장소의 프리미엄 프리미티브 사용
python -m pip install "featuretools[premium]"
NLP 프리미티브 - nlp-primitives 저장소의 자연어 프리미티브 사용
python -m pip install "featuretools[nlp]"
Dask 지원 - Dask를 사용하여 njobs > 1로 DFS 실행
python -m pip install "featuretools[dask]"
다음은 DFS(심층 피처 합성)를 사용하여 자동화된 피처 엔지니어링을 수행하는 예입니다. 이 예에서는 타임스탬프가 지정된 고객 트랜잭션으로 구성된 다중 테이블 데이터 세트에 DFS를 적용합니다.
>> import featuretools as ft
>> es = ft . demo . load_mock_customer ( return_entityset = True )
>> es . plot ()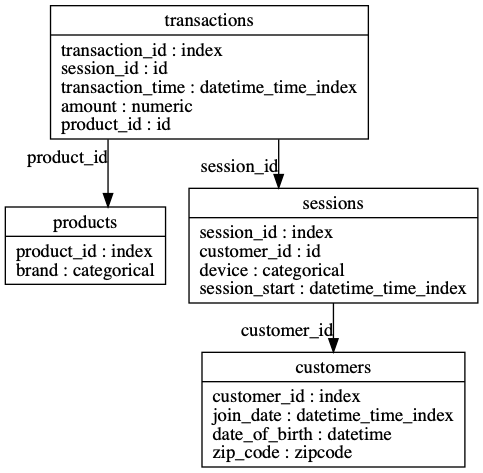
Featuretools는 모든 "대상 데이터 프레임"에 대한 단일 기능 테이블을 자동으로 생성할 수 있습니다.
>> feature_matrix , features_defs = ft . dfs ( entityset = es , target_dataframe_name = "customers" )
>> feature_matrix . head ( 5 ) zip_code COUNT(transactions) COUNT(sessions) SUM(transactions.amount) MODE(sessions.device) MIN(transactions.amount) MAX(transactions.amount) YEAR(join_date) SKEW(transactions.amount) DAY(join_date) ... SUM(sessions.MIN(transactions.amount)) MAX(sessions.SKEW(transactions.amount)) MAX(sessions.MIN(transactions.amount)) SUM(sessions.MEAN(transactions.amount)) STD(sessions.SUM(transactions.amount)) STD(sessions.MEAN(transactions.amount)) SKEW(sessions.MEAN(transactions.amount)) STD(sessions.MAX(transactions.amount)) NUM_UNIQUE(sessions.DAY(session_start)) MIN(sessions.SKEW(transactions.amount))
customer_id ...
1 60091 131 10 10236.77 desktop 5.60 149.95 2008 0.070041 1 ... 169.77 0.610052 41.95 791.976505 175.939423 9.299023 -0.377150 5.857976 1 -0.395358
2 02139 122 8 9118.81 mobile 5.81 149.15 2008 0.028647 20 ... 114.85 0.492531 42.96 596.243506 230.333502 10.925037 0.962350 7.420480 1 -0.470007
3 02139 78 5 5758.24 desktop 6.78 147.73 2008 0.070814 10 ... 64.98 0.645728 21.77 369.770121 471.048551 9.819148 -0.244976 12.537259 1 -0.630425
4 60091 111 8 8205.28 desktop 5.73 149.56 2008 0.087986 30 ... 83.53 0.516262 17.27 584.673126 322.883448 13.065436 -0.548969 12.738488 1 -0.497169
5 02139 58 4 4571.37 tablet 5.91 148.17 2008 0.085883 19 ... 73.09 0.830112 27.46 313.448942 198.522508 8.950528 0.098885 5.599228 1 -0.396571
[5 rows x 69 columns]
이제 우리는 기계 학습에 사용할 수 있는 각 고객에 대한 특징 벡터를 갖게 되었습니다. 더 많은 예를 보려면 심층 기능 합성 문서를 참조하세요.
Featuretools에는 형상 생성을 위한 다양한 유형의 내장 기본 요소가 포함되어 있습니다. 필요한 기본 요소가 포함되어 있지 않은 경우 Featuretools를 사용하면 사용자 정의 기본 요소를 정의할 수도 있습니다.
다음 구매 예측
저장소 | 공책
이 데모에서는 Instacart의 온라인 식료품 주문 300만 건에 대한 다중 테이블 데이터 세트를 사용하여 고객이 다음에 무엇을 구매할지 예측합니다. 자동화된 특성 엔지니어링을 통해 특성을 생성하고 여러 예측 문제에 재사용할 수 있는 Featuretools를 사용하여 정확한 기계 학습 파이프라인을 구축하는 방법을 보여줍니다. 고급 사용자를 위해 Dask를 사용하여 해당 파이프라인을 대규모 데이터 세트로 확장하는 방법을 보여줍니다.
Featuretools 사용 방법에 대한 더 많은 예를 보려면 데모 페이지를 확인하세요.
Featuretools 커뮤니티는 풀 요청을 환영합니다. 테스트 및 개발에 대한 지침은 여기에서 확인할 수 있습니다.
Featuretools 커뮤니티는 Featuretools 사용자에게 기꺼이 지원을 제공합니다. 프로젝트 지원은 질문 유형에 따라 네 곳에서 찾을 수 있습니다.
featuretools 태그와 함께 Stack Overflow를 사용하세요.Featuretools를 사용하는 경우 다음 논문을 인용해 보세요.
제임스 맥스 캔터, 칼리안 비라마차네니 심층 기능 합성: 데이터 과학 노력의 자동화를 향하여. IEEE DSAA 2015 .
BibTeX 항목:
@inproceedings { kanter2015deep ,
author = { James Max Kanter and Kalyan Veeramachaneni } ,
title = { Deep feature synthesis: Towards automating data science endeavors } ,
booktitle = { 2015 {IEEE} International Conference on Data Science and Advanced Analytics, DSAA 2015, Paris, France, October 19-21, 2015 } ,
pages = { 1--10 } ,
year = { 2015 } ,
organization = { IEEE }
}Featuretools는 Alteryx가 관리하는 오픈 소스 프로젝트입니다. 우리가 작업 중인 다른 오픈 소스 프로젝트를 보려면 Alteryx Open Source를 방문하세요. 영향력 있는 데이터 과학 파이프라인을 구축하는 것이 귀하 또는 귀하의 비즈니스에 중요하다면 연락해 주세요.


