local LLM with RAG
1.0.0

이 프로젝트는 샘플 PDF를 기반으로 질문에 답하기 위해 RAG(검색 증강 생성)를 수행하기 위해 Ollama와 함께 로컬 LLM(대형 언어 모델)을 실행하는 것과 관련된 아이디어를 테스트하기 위한 실험적 샌드박스입니다. 이 프로젝트에서는 Ollama를 사용하여 Chroma와 함께 사용할 nomic-embed-text로 임베딩을 생성합니다. 애플리케이션이 실행될 때마다 임베딩이 다시 로드되므로 이는 효율적이지 않으며 여기서는 테스트 목적으로만 수행됩니다.
Ollama와 상호 작용하는 다른 방법을 제공하기 위해 Streamlit을 사용하여 만든 웹 UI도 있습니다.
python3 -m venv .venv 실행하여 Python 가상 환경을 생성합니다.source .venv/bin/activate 실행하고 Windows에서는 ..venvScriptsactivate 실행하여 가상 환경을 활성화합니다.pip install -r requirements.txt 실행하여 필수 Python 패키지를 설치합니다. 참고: 프로젝트를 처음 실행하면 LLM 및 임베딩에 필요한 모델이 Ollama에서 다운로드됩니다. 이는 일회성 설정 프로세스이며 인터넷 연결에 따라 다소 시간이 걸릴 수 있습니다.
python app.py -m <model_name> -p <path_to_documents> 를 사용하여 기본 스크립트를 실행하여 모델과 문서 경로를 지정합니다. 모델을 지정하지 않으면 기본값은 mistral입니다. 경로를 지정하지 않으면 기본적으로 예시 목적으로 저장소에 있는 Research 가 사용됩니다.-e <embedding_model_name> 과 함께 사용할 임베딩 모델을 지정할 수 있습니다. 지정하지 않으면 기본값은 nomic-embed-text입니다. 그러면 PDF 및 Markdown 파일이 로드되고, 임베딩이 생성되고, 컬렉션이 쿼리되고, app.py 에 정의된 질문에 답변됩니다.
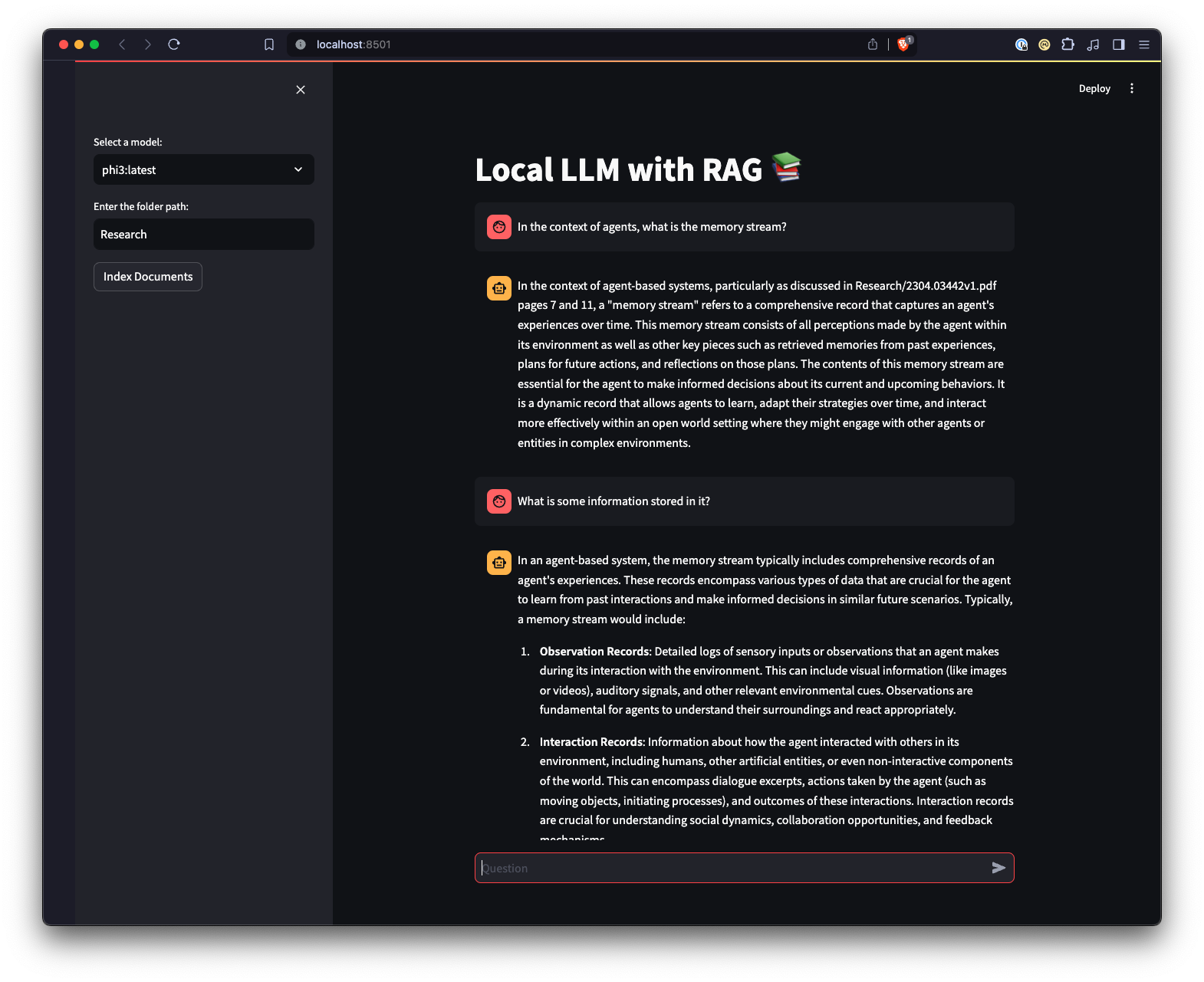
ui.py 스크립트가 포함된 디렉터리로 이동합니다.streamlit run ui.py 실행하여 Streamlit 애플리케이션을 실행합니다.그러면 로컬 웹 서버가 시작되고 애플리케이션과 상호 작용할 수 있는 기본 웹 브라우저에 새 탭이 열립니다. Streamlit UI를 사용하면 모델을 선택하고 폴더를 선택할 수 있어 명령줄 인터페이스에 비해 RAG 챗봇 시스템과 상호 작용하는 더 쉽고 직관적인 방법을 제공합니다. 애플리케이션은 문서 로드, 임베딩 생성, 컬렉션 쿼리 및 결과를 대화형으로 표시하는 작업을 처리합니다.


