Linly
v1.1

이 프로젝트는 중국어 대화 모델 Linly-ChatFlow, 중국어 기본 모델 Chinese-LLaMA(1-2), Chinese-Falcon 및 해당 교육 데이터를 커뮤니티에 제공합니다.
그중 APUS와 공동으로 훈련한 Linly-70B 모델의 성능 지표는 다음과 같습니다.
| 호 | HellaSwag | MMLU | 진실한 QA | 위노그란데 | GSM8K | C-평가 |
|---|---|---|---|---|---|---|
| 54.69 | 76.94 | 60.4 | 53.54 | 73.4 | 12.34 | 80.6 |
중국어 기본 모델은 LLaMA 및 Falcon을 기반으로 하며, 증분 사전 학습을 위해 중국어 및 중국어-영어 병렬 말뭉치를 사용하여 영어 언어 능력을 중국어로 확장합니다. 동시에 이 프로젝트는 현재 공개된 다국어 명령 데이터를 요약하고 중국 모델 훈련에 따른 대규모 명령을 수행하며 Linly-ChatFlow 대화 모델을 구현했습니다.
또한, 이 프로젝트는 3B, 7B, 13B 스케일을 포함하여 처음부터 훈련된 Linly-OpenLLaMA 모델을 오픈 소스화했으며, 1TB 중국어 및 영어 코퍼스에 대해 사전 훈련되었으며, 단어 조합 토크나이저는 중국어에 최적화되어 있습니다. Apache 2.0 프로토콜에 따라 열려 있습니다.
프로젝트 내용
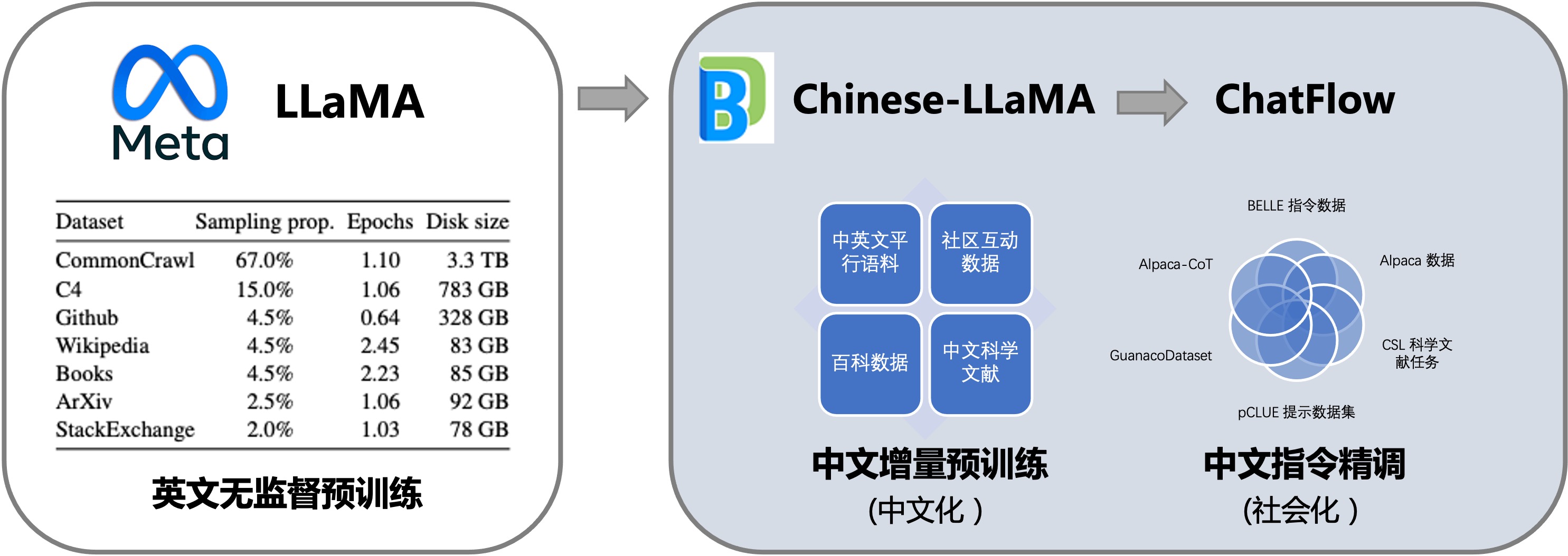
중국어 사전 훈련 코퍼스 | 중국어 교육 미세 조정 데이터 세트 모델 정량적 배포 |
[2024/2/4] APUS와 공동 학습한 Chinese-LLaMA-2(70B) 모델 출시, 다운로드 주소
[2023/7/22] 혼합 코퍼스 훈련, 기술 기사 - 온라인 경험을 기반으로 한 중국어-LLaMA-2(7B, 13B) 모델 출시
[2023/6/14] 중국 Falcon-7B 기본 모델 출시, Falcon 어휘 확장 및 대규모 중국 말뭉치, 기술 기사에 대한 점진적 훈련
[2023/5/31] Linly-ChatFlow-7B 대화 모델이 SuperCLUE-Langya List 순위에 참여했습니다.
[2023/5/28] v1.2 Chinese-LLaMA 업데이트, 시퀀스 길이가 2048로 증가, Linly-OpenLLaMA v0.1 오픈
[2023/5/14] v1.1 업데이트, 더 많은 훈련 데이터 사용, ChatFlow 시퀀스 길이를 1024로 늘리고, 웹 온라인 평가판 및 API 제공
[2023/4/27] Linly-ChatFlow-13B 대화 모델 및 Linly-China-LLaMA-33B 중국어 기본 모델 공식 출시
[2023/4/17] llama_inference는 8비트 정량적 추론 및 마이크로서비스 배포를 업데이트하여 추론 속도를 크게 향상시키고 메모리 소비를 줄입니다.
[2023/4/8] TencentPretrain, 이제 LoRA 교육 및 DeepSpeed Zero-3 Offload를 지원합니다
[2023/4/1] llama.cpp 고속 추론을 지원하도록 Linly-ChatFlow 모델 가중치의 4비트 양자화 버전 업데이트
[2023/3/28] 기술 블로그 LLaMA 기반 중국어 대화 모델 Linly-ChatFlow-7B 오픈
이 프로젝트는 다양한 모델을 제공하며 최신 Linly-China-LLaMA-2 모델을 사용하는 것이 좋습니다.
| 모델 다운로드 | 분류 | 훈련 데이터 | 훈련 시퀀스 길이 | 버전 | 업데이트 시간 |
|---|---|---|---|---|---|
| 중국어-LLaMA-2-7B(hf 형식) | 언어 모델/대화 모델 | 혼합 코퍼스 | 2048년 | v0.1 | 2023.7.22 |
| 중국어-LLaMA-2-13B(hf 형식) | 언어 모델/대화 모델 | 혼합 코퍼스 | 2048년 | v0.2 | 2023.8.12 |
| 중국어-LLaMA-2-70B(hf 형식) | 언어 모델 | 혼합 코퍼스 | 4096 | v0.1 | 2024.1.3 |
| 모델 다운로드 | 분류 | 훈련 데이터 | 훈련 시퀀스 길이 | 버전 | 업데이트 시간 |
|---|---|---|---|---|---|
| Chinese-Falcon-7B(hf 형식) | 기본 모델 | 50G 일반 코퍼스 | 2048년 | v0.2 | 2023.6.15 |
사용 지침
| 모델 다운로드 | 분류 | 훈련 데이터 | 훈련 시퀀스 길이 | 버전 | 업데이트 시간 |
|---|---|---|---|---|---|
| 중국어-LLaMA-7B | 기본 모델 | 100G 일반 코퍼스 | 2048년 | v1.2 | 2023.5.29 |
| ChatFlow-7B | 대화 모델 | 5M 명령 데이터 | 1024 | v1.1 | 2023.5.14 |
| 중국어-LLaMA-13B | 기본 모델 | 100G 일반 코퍼스 | 2048년 | v1.2 | 2023.5.29 |
| ChatFlow-13B | 대화 모델 | 5M 명령 데이터 | 1024 | v1.1 | 2023.5.14 |
| 중국어-LLaMA-33B(hf 형식) | 기본 모델 | 30G 일반 코퍼스 | 512 | v1.0 | 2023.4.27 |
HuggingFace 모델 ?
이 프로젝트는 TencentPretrain 형식과 Huggingface 형식 간의 변환을 지원하는 변환 스크립트를 제공합니다. 자세한 사용법은 ➡️ 허깅페이스 형식 변환 ⬅️을 참고해주세요.
| 모델 다운로드 | 분류 | 훈련 데이터 | 훈련 시퀀스 길이 | 버전 | 업데이트 시간 |
|---|---|---|---|---|---|
| 오픈LLaMA-13B | 기본 모델 | 100G 일반 코퍼스 | 2048년 | v0.1 | 2023.5.29 |
Linly-China-LLaMA-2 모델의 효과를 보여주는 예제 생성


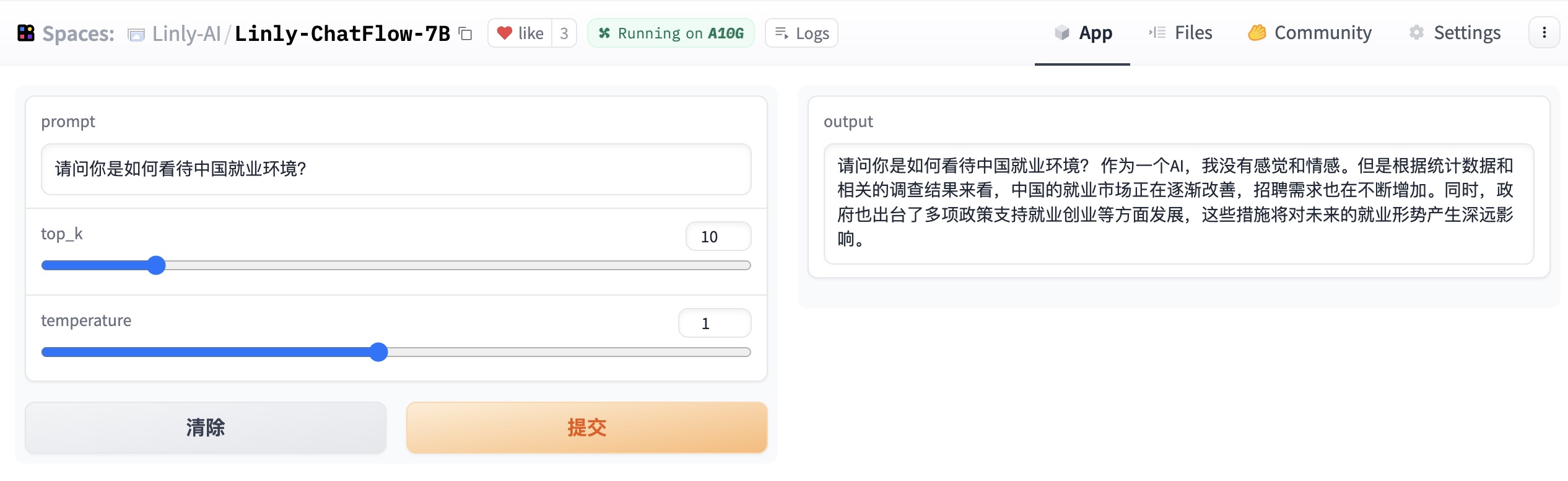
Linly-ChatFlow에서 온라인 데모를 체험할 수 있습니다.
온라인 API 서버 평가판:
curl -H ' Content-Type: application/json ' https://P01son-52nfefhaaova.serv-c1.openbayes.net -d ' {"question": "北京有什么好玩的地方?"} '온라인 경험 컴퓨팅 리소스를 제공한 HuggingFace 및 OpenBayes에 특별히 감사드립니다.


자신의 환경에서 대화형 데모를 구성하려면 llama_inference 프로젝트를 팔로우하고 별표 표시해 주세요.
이 장에서는 TencentPretrain 형식 모델 가중치를 사용하는 방법을 소개합니다. (최신 버전의 Linly-China-LLaMA-2 모델의 hf 형식 가중치는 적용되지 않습니다. 최신 버전의 모델 사용 방법은 Huggingface 페이지를 참조하세요.) .
사전 학습된 모델 가중치를 다운로드하고 종속성을 설치하며 환경을 테스트합니다. py3.8.12 cuda11.2.2 cudnn8.1.1.33-1 torch1.9.0 bitandbytes0.37.2
디코딩 매개변수 및 자세한 사용 지침은 llama_inference를 참조하세요.
git lfs install
git clone https://huggingface.co/Linly-AI/ChatFlow-7B
git clone https://github.com/ProjectD-AI/llama_inference
cd llama_inference
vi prompts.txt #编辑用户输入,例如"上海有什么好玩的地方?"
python3 llama_infer.py --test_path prompts.txt --prediction_path result.txt
--load_model_path ../ChatFlow-7B/chatflow_7b.bin
--config_path config/llama_7b_config.json
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512python3 llama_dialogue.py --seq_length 512 --top_k 10
--load_model_path ../ChatFlow-7B/chatflow_7b.bin
--config_path ./config/llama_7b_config.json
--spm_model_path ../ChatFlow-7B/tokenizer.modelpython3 llama_infer.py --test_path prompts.txt --prediction_path result.txt
--load_model_path ../ChatFlow-7B/chatflow_7b.bin
--config_path config/llama_7b_config.json
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512 --use_int8 설치 종속성: 플라스크
python3 llama_server.py --load_model_path ../ChatFlow-7B/chatflow_7b.bin
--config_path config/llama_7b_config.json
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512
curl -H ' Content-Type: application/json ' http://127.0.0.1:8888/chat -d ' {"question": "北京有什么好玩的地方?"} '종속성 설치:gradio
python llama_gradio.py --load_model_path ../ChatFlow-7B/chatflow_7b.bin
--config_path config/llama_7b_config.json
--spm_model_path ../ChatFlow-7B/tokenizer.model --seq_length 512
웹페이지에서 열기: http://127.0.0.1:7860/
ChatFlow 모델은 llama.cpp를 사용하여 로컬 CPU 추론에 Int4 양자화 모델 가중치를 배포하는 것을 지원합니다. 자세한 사용법은 ➡️ int4 추론 ⬅️을 참조하세요.
모델은 TencentPretrain 사전 훈련 및 지침 미세 조정을 기반으로 합니다. 자세한 내용은 ➡️ 증분 훈련 ⬅️을 참조하세요.
LLaMA1을 기반으로 ChatFlow에서 생성된 결과 표시
| 즉각적인 | Linly-ChatFlow-7B | Linly-ChatFlow-13B |
|---|---|---|
| 시간 관리 능력을 어떻게 향상시킬 수 있나요? | 시간 관리 기술을 향상하려면 먼저 과로나 방해를 받지 않도록 작업을 올바르게 구성하도록 자신을 훈련하십시오. 플래너에 중요한 업무를 기록하고, 합리적인 목표와 기한을 설정하여 불안감과 의욕상실을 예방할 수 있습니다. 둘째, 독서, 업무 외 활동 등 자유시간을 효과적으로 활용하여 개인 생활의 상태를 바꾸고 업무를 더 잘 완수하는 방법을 배워야 합니다. 마지막으로, 이전 과정을 정기적으로 검토하여 시간 관리 수준을 반성할 수도 있으며, 심리적 스트레스를 피하기 위해 자신에게 너무 엄격하지 마십시오. | 다음은 시간 관리 기술을 향상하는 데 유용할 수 있는 몇 가지 팁입니다. 1. 일정과 계획을 세우고 이를 지키십시오. 2. 방해받지 않고 작업에 집중하세요. 3. 시간을 더 잘 정리하고 관리하는 데 도움이 되는 도구와 소프트웨어를 활용하십시오. 4. 과도한 커밋을 피하기 위해 "아니오"라고 말하는 법을 배우십시오. 5. 우선순위를 정하고 가장 중요한 일부터 먼저 처리하십시오. 6. 집중을 유지하려면 뽀모도로 기법이나 기타 시간 관리 기법을 사용하세요. 7. 건강을 유지하기 위해 충분한 수면과 운동을 하십시오. 8. 생산성이 가장 높은 시간을 이해하여 작업 일정을 계획하고 더 많은 결과를 얻을 수 있습니다. 9. 새로운 기술과 지식을 학습하여 효율성을 향상시킵니다. 10. 진행 상황을 모니터링하고 진행 상황에 따라 계획을 반영하고 조정합니다. |
| 스트레스에 대처하는 가장 효과적인 방법은 무엇입니까? | 스트레스에 대처하는 효과적인 방법은 다음과 같습니다. 1) 모든 일이 하루 또는 일주일에 걸리지 않도록 시간을 합리적으로 조정하는 방법을 배우십시오. 2) 전반적인 상황을 파악하고 작은 문제에 흔들리지 마십시오. 귀하의 생활 상태를 변경할 수 있도록 4) 건강을 유지하기 위해 제때에 의사를 만나십시오. | 스트레스에 대처하는 가장 효과적인 방법은 긴장을 푸는 방법을 배우고 운동, 음악, 독서, 친구와의 소통 등 자신에게 맞는 스트레스 해소 방법을 찾는 것입니다. 동시에 일과 생활의 범위를 좁히고, 업무를 완수할 수 있는 충분한 공간을 확보하고, 더 나은 삶과 일의 균형을 확립할 수도 있습니다. |
| Python과 JavaScript 프로그래밍 언어의 주요 차이점은 무엇입니까? | Python은 웹 개발, 데이터 분석, 인공 지능 등에 사용할 수 있는 해석된 객체 지향 스크립팅 언어입니다. JavaScript는 프런트 엔드 웹 디자인, 게임 개발, 서버 측 프로그래밍 등에 널리 사용되는 동적 대화형 스크립팅 언어입니다. 둘 사이의 가장 큰 차이점은 다음과 같습니다. - 다른 구문: Python의 구문은 C/C++와 같이 상대적으로 간단하지만 JavaScript는 매우 복잡하고 기능을 재정의해야 하므로 사용하기가 더 까다롭습니다. - 다양한 기능: Python은 HTML/CSS 외에도 JQuery, React, Angular 및 기타 프레임워크를 포함하여 데이터 처리, 그래픽 작업 등과 같은 다양한 작업을 구현할 수 있는 다양한 모듈과 라이브러리를 지원합니다. 클라이언트 인터페이스 생성. | Python과 JavaScript의 주요 차이점은 목적입니다. Python은 웹 개발, 데이터 분석 등 다양한 유형의 프로그래밍 작업에 적용할 수 있는 비교적 다재다능한 컴퓨터 언어인 반면, JavaScript는 주로 웹 개발에 사용되며 그 기능은 상대적으로 제한적입니다. |
| 재택근무 중에 어떻게 생산성을 높일 수 있나요? | 1. 집중력을 유지할 수 있도록 편안하고 정돈된 작업 공간을 만드세요. 2. 일일 또는 주간 작업 목록을 작성하고 가장 중요한 항목의 우선순위를 지정하세요. 3. 시작 및 종료 시간, 휴식 시간, 작업 완료 기한을 포함하여 명확한 작업 일정을 설정합니다. 4. 멀티태스킹을 피하고 한 가지 일이 완료될 때까지 집중한 후 다음 일로 넘어갑니다. 5. 시간 추적 앱을 사용하거나 소셜 미디어를 끄는 등 시간을 관리하는 기술을 사용하십시오. | 1. 더 집중할 수 있도록 전용 작업 공간을 설정하십시오. 2. 작업과 우선순위를 관리하기 위한 계획과 목록을 개발합니다. 3. 중요한 정보를 놓치거나 긴급 상황이 발생하는 것을 방지하기 위해 원활한 의사소통과 연락을 유지합니다. 4. 상태를 바꾸고 몸과 마음을 편안하게 해주는 몇 가지 정기적인 작은 활동을 만들어 보세요. 5. 합리적인 식습관, 운동, 수면 등 건강에 유의하세요. |
| 양자컴퓨팅의 기본을 설명해 주실 수 있나요? | 양자컴퓨팅(Quantum Computing)은 양자역학의 원리를 이용해 보다 효율적인 운영과 문제 해결을 달성하는 컴퓨터 기술이다. 주요 기반으로는 1) 양자 비트(qubit), 2) 양자 상태 연산, 3) 양자 측정 기술, 4) 초전도성 등이 있습니다. 큐비트는 기존 컴퓨터에서 위치를 결정하기 위해 지속적으로 측정할 필요 없이 동시에 0과 1 상태 사이에 존재할 수 있습니다. 양자 상태 작업을 통해 계산 결과를 변경하는 데 도움이 되는 작업 방법이 시스템 동작을 분석하는 데 도움이 됩니다. 초전도성은 정보를 증폭시키고 더 많은 메모리 공간을 제공하는 데 도움이 됩니다. | 양자컴퓨팅(Quantum Computing)은 양자물리학의 원리를 이용해 정보를 처리하는 새로운 형태의 컴퓨팅 기술이다. 기존 컴퓨터에서는 각 비트에 0과 1의 두 가지 상태만 있습니다. 양자 컴퓨터에서는 각 큐비트가 동시에 여러 상태에 있을 수 있습니다. 따라서 이러한 상태를 중첩이라고 합니다. 따라서 양자 컴퓨터는 대량의 복잡한 데이터를 보다 효율적으로 처리할 수 있습니다. 또한 양자컴퓨팅은 비트의 상호작용을 이용해 작업 속도를 가속화해 컴퓨팅 효율성을 크게 향상시킬 수도 있다. |
| 식물성 단백질과 동물성 단백질의 주요 차이점은 무엇입니까? | 식물과 동물 단백질의 주요 차이점은 구조입니다. 식물 단백질은 수많은 α-나선형 사슬로 구성되는 반면, 동물성 단백질은 더 복잡한 β-시트 사슬을 포함합니다. 또한 식물성 단백질에는 글루타민, 트립토판, 글리신 등과 같은 중요한 아미노산이 부족한 경우가 많아 기능에 영향을 줄 수 있습니다. | 식물성 단백질과 동물성 단백질 사이에는 서로 다른 주요 차이점이 있으며, 그 중 가장 분명한 것은 영양 성분입니다. 동물성 단백질에는 다양한 필수 아미노산이 포함되어 있는 반면, 식물성 단백질은 일반적으로 일부만 제공합니다. 또한 식물성 단백질에는 인간 건강에 매우 중요한 베타인, 시스테인 등과 같은 일부 비필수 아미노산이 포함되어 있을 수도 있습니다. 영양소 외에도 식물성 단백질에는 상대적으로 풍부하지만 동물성 단백질에는 적은 칼슘, 마그네슘, 인, 철 및 기타 금속 원소뿐만 아니라 일부 식이섬유도 있습니다. |
| 비판적 사고 능력을 어떻게 개발할 수 있나요? | 비판적 사고 능력을 개발하려면 자신의 인지에 대해 더 많은 지원을 얻을 수 있도록 학제간 지식과 폭넓은 독서가 필요합니다. 또한 이전 경험을 활용하고 핵심 사항과 작동 방식에 초점을 맞추는 등 좋은 검색 모델을 설정하고 합리적인 솔루션을 결정하는 것도 중요합니다. | 비판적 사고 능력을 키우는 방법에는 여러 가지가 있는데, 그 중 가장 중요한 것은 지속적인 연습을 통해 사물과 상황에 대한 이해를 높이는 것입니다. 우선 기본적인 논리, 수학적 지식, 과학적 연구 방법을 이해해야 하며, 그런 다음 매일 책을 통해 엄밀하게 사고하고 사회적 경험을 바탕으로 문제를 분석하거나 해결할 수 있어야 합니다. 사회 역동적인 활동은 현실 세계의 복잡한 문제를 심층적으로 분석하는 데 도움이 되므로 이러한 현상의 영향을 보다 명확하게 이해할 수 있으며, 마지막으로 관련 토론 그룹에 참여하여 더 많은 피드백과 의견을 얻을 수도 있습니다. |
| 오늘날 교육 부문이 직면한 주요 과제는 무엇입니까? | 교육계가 많은 어려움을 겪고 있다고 생각합니다. 첫째, 자금 부족으로 인해 일부 학교는 더 나은 학생 경험을 지원하는 데 필요한 시설과 장비에 투자할 수 없어 교육 효과에 영향을 미칩니다. 둘째, 새로운 기술의 사용으로 인해 교사는 기술을 사용하여 학습 능력을 향상시키는 방법을 배워야 합니다. 전문성; 마지막으로, 사회 변화, 대규모 인구 및 세계화로 인해 교사는 글로벌 상황을 더 잘 이해하고 보다 공평하고 포용적인 교육 시스템을 만들기 위해 더 넓은 지식을 가질 필요가 있습니다. | 교육 부문의 가장 큰 과제 중 하나는 점점 더 경쟁이 심화되는 시장에서 공간을 확보하는 것입니다. 이는 또한 시장 수요를 더 잘 충족하기 위해 학교 과정과 서비스의 질을 개선해야 함을 의미합니다. 또한 현재의 인력 수준을 유지하고 다양한 집단에 공정한 기회를 제공하는 것은 교육 부문이 해결해야 할 주요 과제입니다. |
| 소비자 행동에 영향을 미치는 주요 요인은 무엇입니까? | 소비자 행동에 영향을 미치는 주요 요인에는 경제 환경, 문화 및 사회적 조건, 목표 시장 고객 요구의 변화, 서비스 품질, 광고 정보 전달 방법 및 사용자 요구의 지속적인 개선 등이 포함됩니다. | 소비자 행동에 영향을 미치는 주요 요인은 첫째, 소득수준, 직업, 삶의 질 등 경제적 지위, 둘째, 성별, 연령, 소득원, 가족구조 등 개인적 특성이다. , 여가 및 오락 문화, 비즈니스 및 서비스 시스템 등과 같은 사회 환경 넷째는 세금 정책, 의료 보험 시스템, 교육 정책 등과 같은 정부 정책입니다. |
| 직장에서 가장 효과적인 갈등 해결 전략은 무엇입니까? | 직장에서 가장 효과적인 갈등 해결 전략은 양측의 입장을 주의 깊게 듣고 이해하며 타협적인 태도로 협상하여 상호 해결책을 찾는 것입니다. 또한 공정성의 원칙을 준수하고, 서로 구체적인 요구 사항을 제시하며, 결과에 대한 높은 수준의 관심을 유지하는 방법을 채택할 수도 있습니다. | 직장 내 갈등을 효과적으로 해결하기 위해 다양한 기술과 방법을 사용할 수 있습니다. 첫째, 양측이 아무리 반대하더라도 원활한 의사소통을 유지하고 이해와 신뢰의 관계를 구축하는 데 주력해야 하며, 둘째, 타인에게 감정을 표출하기보다는 객관적이고 공정한 의견을 제시해야 하며, 셋째, 적시에 문제를 발견해야 합니다. 본질적으로 의사소통을 다시 시작하기 위해 상황을 변경하는 데 다양한 수단이 사용됩니다. 최종적으로 신중한 분석을 거쳐 양측은 분쟁으로부터 이익을 얻을 수 있습니다. |
| Linly-ChatFlow-7B | Linly-ChatFlow-13B | |
|---|---|---|
| 인간은 일생 동안 평균 몇 번 눈을 깜박일까요? 답변을 설명해 보십시오. 귀하의 설명은 독자가 추론을 통해 단계적으로 이끌어야 합니다. | 과학 연구에 따르면 건강한 성인은 하루에 약 150~200번 눈을 깜박인다고 합니다. 인간의 수명은 보통 70~80년이므로 일생 동안 깜박이는 횟수는 다음과 같이 추정할 수 있습니다. 하루에 150~200회 깜박임 × 60년 = 90,000~114,000회 이 결과는 근사치일 뿐이며 100% 정확하지는 않습니다. 실제로 눈을 깜박이는 횟수는 사람마다 다릅니다. 왜냐하면 인체의 특성, 환경, 활동 패턴이 모두 눈을 깜박이는 횟수에 영향을 미치기 때문입니다. | 평균적으로 인간은 하루에 15,000번에서 20,000번 정도 눈을 깜박입니다. 이는 일생 동안 약 187만 번 눈을 깜박인다는 것을 의미합니다. 그러나 이는 사람이 팔십세까지 사는 데 걸리는 80년을 기준으로 계산한 것이며, 실제로 우리는 그 진정한 가치를 단정할 수 없습니다. |
| 매일 지구에는 몇 번이나 번개가 치는가? 답변을 설명해 보십시오. 귀하의 설명은 독자가 추론을 통해 단계적으로 이끌어야 합니다. | 번개는 자연 현상이기 때문에 각 시간대에서 매일 얼마나 많은 번개가 치는지 정확히 알 수 없습니다. 하지만 통계에 따르면 전 세계적으로 1분당 평균 20조 번의 번개가 치고 있는데, 이는 1초에 4,600번의 번개에 해당하며, 이는 10초마다 번개가 치는 셈이다. | 번개는 구름과 대기 중의 물 분자 사이의 화학 반응으로, 밝은 빛과 격렬한 소리를 만들어냅니다. 이 현상은 지구 표면에서 매우 흔하며 쉽게 관찰할 수 있습니다. 다양한 연구 데이터와 통계에 따르면 전 세계적으로 매년 평균 많은 낙뢰가 발생하고 있음을 알 수 있습니다. 예를 들어, 미국 '내셔널지오그래픽' 웹사이트는 미국 국립과학원(NSF)과 기타 관련 기관의 연구 결과를 인용해 북미 지역에서 매년 평균 30만 건의 번개 사건이 발생한다고 밝혔습니다. 남아메리카에서는 약 250,000번의 번개 사건이 발생합니다. 또한 일본, 서아프리카 등지에서도 유사한 통계가 있습니다. 또한 지역마다 번개 활동량에 일정한 차이가 있으며 지형, 고도, 기후 조건 등의 요인도 번개 활동의 빈도와 기간에 영향을 미친다는 점에 유의해야 합니다. |
| 탁구공이 약 30cm 길이의 깊고 단단한 튜브에 떨어졌습니다. 튜브는 지상에서 1cm밖에 떨어지지 않은 시멘트 바닥에 묻혀 있어서 움직일 수 없었습니다. 튜브는 탁구공보다 약간 넓기 때문에 손을 넣을 수 없습니다. 어떻게 온전하게 꺼내나요? | A. 탁구공이 굴러 떨어질 때까지 망치로 땅을 친다. B. 긴 나무 막대기를 사용하여 반대쪽 끝에서 잡아당깁니다. C. 특별한 도구나 기계를 사용하여 파냅니다. | 이 문제를 해결하려면 물리학 지식과 창의력이 필요합니다. 먼저 탁구공이 이 파이프에 도달한 후 어떤 일이 일어날지 상상해 봅시다. 탁구공은 매우 작기 때문에 파이프 내부의 공기 흐름이나 물 흐름에 쉽게 부딪혀 위로 떠오를 수 있습니다. 영원히 그 안에 갇혀 있을 것입니다. 파이프 표면에서 나올 때까지 천천히 위쪽으로 움직일 수 있는 방법을 찾아야 합니다. 다음으로, 우리는 이 목표를 달성하는 방법에 대해 생각해야 합니다. 첫째, 기포의 원리를 이용하여 이 문제를 해결할 수 있습니다. 노즐에서 공기가 빠르게 분출되면 주변 공기와 함께 커다란 거품 같은 구조를 형성하게 됩니다. 이 방법을 시나리오에 적용하면 거품과 같은 효과를 만들어 탁구공이 떠서 위쪽으로 움직일 수 있습니다. |
| 일부 원시 유기체가 분해되어 1분마다 원본과 동일한 크기의 두 부분으로 나뉘는 것을 살펴보겠습니다. 12시가 되면 용기가 반쯤 차는 시간은 언제인가요? | 이 문제는 실험 설계보다는 수학적 모델을 사용하여 설명할 수 있습니다. 그래서 제가 답을 드리겠습니다. 54분에 | - 먼저 유기체가 분열하는 속도, 즉 유기체의 양이 매 분마다 얼마나 나누어지는지 계산해야 합니다. 분당 분할 속도를 S라고 가정하면 S*(t/60)=X(t)이며, 여기서 X(t)는 분자 수, t는 시간(단위: min)을 나타냅니다. - 둘째, 질문의 의미에 따르면 12시 방향에서 용기에 담긴 물질의 부피는 Y=10^X 3.75/4 입니다. - 마지막으로 컨테이너의 부피가 절반인 경우, 즉 Y=(10^X-0.5)/2.5이면 Y=10^X 3.75/4를 대체하여 다음을 얻습니다. (10^X-0.5)/2.5 = 3.75/4 * 10^X - 0.75 10^(X+1) 단순화하면, 우리는 얻는다 |
| 모든 전쟁과 혼란은 협상이 없고 말할 이유가 없을 때 발생합니다. 그러나 언어가 있는 곳에 추론이 자동으로 존재하는 것은 아닙니다. A. 모든 전쟁과 혼란은 자유가 없기 때문에 발생한다. B. 협상과 추론이 불가능하다고 해서 모든 전쟁과 혼란이 일어나는 것은 아니다. C. 자유가 없으면 추론은 이루어질 수 없다. 전쟁과 혼란이 일어날 수 있다 D. 언어와 자유가 있는 곳에 전쟁은 절대 일어나지 않는다 | 나. 협상과 추론이 불가능하다고 해서 모든 전쟁과 혼란이 일어나는 것은 아니다. | 내 사고방식은 다음과 같다. 서로 생각을 공유해야 하는 사람들이 있는 한, 언어를 통해 소통한다는 목표를 달성해야 한다. 그리고 그룹의 구성원이 서로에게 모욕을 주거나 전혀 이야기하고 싶지 않은 경우 이러한 상황은 협력의 발전을 방해할 것입니다. 즉, 언어와 자유는 사회 조직을 구축하고 유지하며 사람들이 공통 자원을 보다 효율적으로 사용하도록 돕는 핵심입니다. 그래서 저는 B를 선택합니다. 모든 전쟁과 혼란이 협상과 이해의 부족으로 인한 것은 아닙니다. |
| 수학 시험 결과가 나온 후 샤오밍은 "내가 합격했다면 샤오팡도 합격했다"고 말했다. 샤오팡은 "이 시험이 너무 쉬워서 합격했나요?"라고 말했다. | 질문에 따르면 두 가지 조건을 얻을 수 있습니다. 1. Xiao Ming이 시험에 합격했습니다. 2. Xiao Fang이 시험에 합격했습니다. 이제 Xiao Ming의 합격 여부를 추리해야 합니다. 먼저 "모두 합격 여부"에 대한 결과를 판단해야 합니다. Xiao Ming과 Xiao Fang 모두 시험이 쉽다고 말했기 때문에 시험은 어렵지 않다고 결론을 내릴 수 있습니다. "내가 합격했다면 Xiaofang도 합격한 것입니다."라는 Xiao Ming의 말에 따르면, Xiao Ming과 Xiaofang이 동시에 합격하기 위한 전제 조건은 두 사람 모두 특정 점수를 가지고 있어야 한다는 결론을 내릴 수 있습니다. 마지막으로 Xiaofang은 "나는 모든 것을 통과했다"고 말하고 Xiao Ming과 관련된 정보를 포함하지 않았기 때문에 Xiao Ming의 합격 여부를 판단하는 것은 불가능합니다. | 질문에 따르면 두 가지 조건이 도출될 수 있습니다. 1. Xiao Ming이 패스하면 Xiao Fang도 패스합니다. 2. Xiaofang은 시험이 매우 쉽다고 말했습니다. 두 번째 조건을 통해 Xiaofang이 시험에 합격했어야 했음을 추론할 수 있습니다. 따라서 Xiaofang은 결과를 결정했으며 더 이상 Xiao Ming의 상황을 추측할 수 없습니다. 따라서 Xiao Ming의 합격 여부를 판단하는 것은 불가능합니다. |
| 도시가 정원이나 연못을 건설하려면 네 가지 가정이 필요합니다. 연못을 건설하려면 다리를 건설해야 하고, 정원을 건설하려면 정원을 건설해야 합니다. 나무를 심으려면 다리를 건설해야 합니다. 이로부터 추론할 수 없는 것은 A. 끝에는 연못이 있다 B. 끝에는 다리가 있어야 한다 C. 끝에는 정원이 있을 수 있다 D. 연못과 정원은 존재할 수 없다. 동시. | 먼저 정답은 D이다. 연못과 정원은 동시에 존재할 수 없기 때문이다. 그런 다음 각 옵션을 차례로 분석합니다. 1. 답: 결국 연못이 있을 것이라는 언급은 없고, "연못을 만든 후에 다리를 놓아야 한다"는 것만 알고 있기 때문에 결국 연못이 있을 것이라고 말할 수는 없습니다. 2. B: "다리를 건설하면 정원을 건설할 수 없다"고 되어 있어서, 결국 정원이 있으면 다리도 건설해야 하는데, 이는 옵션 B와 반대이다. 3. C: '결국 정원이 있어야 한다'는 언급은 없지만 '정원을 만들려면 나무를 심어야 한다'고 해서 결국 정원이 있어야 한다고 말할 수는 없다. 4. D: '결국 연못이 있다'는 언급은 없지만 '연못과 정원은 동시에 존재할 수 없다'고 해서 결국 연못이 없다고 단정할 수는 없다. | 이 질문의 핵심 단어는 '가설'이다. 왜냐하면 네 가지 조건을 바탕으로 판단을 내려야 하기 때문이다. 우선, 우리는 연못을 건설하려면 다리를 건설해야 하고, 다리를 건설한 후에는 정원을 건설할 수 없으며, 정원을 건설하려면 나무를 심어야 한다는 메시지를 잘 이해해야 합니다. 나무를 심으려면 다리를 건설해야 합니다. 그런 다음 이들 사이에서 몇 가지 공통점을 찾아볼 수 있습니다. 예를 들어 각 항목은 결과(연못, 다리 등이 있음)를 생성하지만 해당 확률과 순서는 동일하지 않습니다. 이러한 가정과 조건을 바탕으로 다음과 같은 결론을 내릴 수 있습니다. A. 결국 연못이 있습니다. 각 항목마다 결과가 나오기 때문에 연못을 만든 후에 정원을 만드는 것이 가능합니다. B. 다리가 있어야 합니다. 결국 - 다리가 건설되는 한, 정원을 건설하는 것은 분명히 다리의 존재로 이어질 것입니다. C. 결국 정원이 있을 수 있습니다 - 두 번째 가설에 따르면, 그 후에는 분명히 다리가 있을 것입니다. 정원을 짓는 것은 정원을 만드는 것이 더 가능성이 높습니다. D. 연못과 정원은 동시에 존재할 수 없습니다. 연못을 건설한 후에는 정원을 건설할 수 없으며, 정원을 건설하면 다리가 나타나므로 둘은 상호 배타적입니다. |
| 문제는 이 세상에는 참(True), 거짓(False), 무작위(Random)라는 세 가지 신이 있다는 것입니다. 그 중 T신은 진실만을 말하고, F신은 거짓말만을 하고, R신은 질문을 들을 때마다 진실을 말할지, 거짓말을 할지 결정하기 위해 동전을 던집니다. , 그러나 당신은 어떤 신이 누구인지 모릅니다. 테스트할 수 있는 기회는 세 번 있습니다. 각 기회마다 진술을 말하고 신 중 한 명을 찾아 판단(참/거짓)을 내릴 수 있습니다. 하나님은 항상 당신의 언어를 이해하시고 그분의 계획에 따라 응답하시지만, 그분은 자신의 언어로 응답하실 것이며 X 또는 Y로 대답하실 것입니다. 그 중 하나는 참을 나타내고 다른 하나는 거짓을 나타낸다는 것을 알지만 어느 것이 어느 것을 나타내는지는 알 수 없습니다. 질문은 다음과 같습니다. 세 번의 기회를 사용한 후 세 신의 정체를 확인할 수 있습니까? | 1. 먼저 세 신이 말하는 언어와 각 상황에서의 의미를 이해합니다. 2. 가능하다면 최소한의 정보를 사용하여 상황을 명확하게 정리하도록 노력하십시오. 3. 두 번째 요점을 바탕으로 알려진 정보를 바탕으로 결론을 도출하는 공식을 구성하십시오. 4. 마지막 결과를 이전 두 번과 비교하고 확인합니다. | 첫 번째 문장을 먼저 물어보십시오. 참 신이 "참"이라고 대답하는 데 동의한다면 그 신은 참 신이어야 합니다. 그렇지 않으면 거짓 신임에 틀림없습니다. 마찬가지로, 거짓 신이 '참'이라고 말하기로 동의하면 그 사람이 참 신이고, 그렇지 않으면 거짓 신입니다. 첫 번째 문장에 대한 대답이 "X"이면 그것은 참 신이고, 그렇지 않으면 거짓 신임에 틀림없습니다. 따라서 다음 공식을 사용하여 세 신의 정체를 확인할 수 있습니다. T = (T ∧ X) v (T ∧ Y) v X True = F False = R |
| 현재 서로의 언어를 이해하지 못하는 A, B, C 3개국 대표가 국제회의를 소집하는데, 이를 위해서는 A, B 국가의 언어를 이해하는 번역가 1명과 해당 언어를 이해하는 1명이 필요하다. A국가와 C국가, B국가와 C국가입니다. 대표국가가 A국가에서 E국가로 늘어나면, 같은 언어를 전혀 사용하지 않는 5명의 대표가 회의에 참석하게 됩니다. 그렇다면 번역가의 수를 최대한 줄여서 회의를 계속할 수 있다는 조건에서 각 번역가는 최소한 몇 명의 번역가만 이해해야 할까요? | 첫째, 모든 대표자가 회의 내용을 이해할 수 있도록 최소한 몇 명의 번역자가 필요한지 알아야 합니다. 해외 미팅이기 때문에 통역사는 영어에 능통하고 중국어를 이해해야 합니다. 따라서 A, B, C, D 4개국이 참여하는 회의에는 최소 2명의 통역사가 필요합니다. 즉, 중국어를 이해하는 번역가 1명과 영어와 중국어를 이해하는 번역가 1명이 필요합니다. 그러다가 A국가에서 E국가로 대표단이 늘어나면서 행사장의 언어가 바뀌게 되었고, 이로 인해 또 다른 통역사를 배치해야 했고, 영어와 중국어를 아는 통역사 한 명과 중국어를 아는 통역사 한 명도 필요했다. 따라서 최소 3명의 번역가가 필요합니다. | 먼저 작은 결론부터 살펴보겠습니다. 대표자가 늘어나면 필요한 최대 번역자 수는 8/3에 이를 수 있습니다. N개의 국가가 있고 그 중 N > 4가 있으며 국가 A와 B가 동일하고 국가 C도 국가 B와 동일하며 동일한 언어를 공유한다고 가정합니다. A, B, C 세 국가는 서로의 언어를 전혀 이해하지 못하기 때문에 A와 B 국가 간의 대화, B 국가와 C 국가 간의 대화, B 국가와 C 국가 간 대화, 즉 세 번에 걸쳐 회의를 진행해야 합니다. 국가 A와 C. 첫 번째 회의 : 1 번의 번역가, 국가 A와 B의 언어에 능숙하며 국가 C의 언어에 능숙합니다. 다른 번역가는 필요하지 않습니다. 두 번째 회의 : 1 번의 번역가, 국가 A와 B의 언어에 능숙하며 국가 C의 언어에 능숙합니다. 다른 번역가는 필요하지 않습니다. 세 번째 회의 : 2 명의 번역가, 1 명은 언어 A와 C에 능숙하고 다른 하나는 언어 B와 C에 능숙합니다. 따라서 총 번역기의 총 수 : 1 + 1 + 2 = 4. |
| 언어는 일종의 취향입니다. 사람들은 자신의 감정을 표현하기 위해 의존합니다. 이것은 사회 의식이 변화하고 사회 의식이 사회적 존재를 결정한다는 것을 보여준다. | 마지막 옵션 D는 사회적 의식이 사회적 의식을 결정하는 것이 합리적인지 여부를 결정하는 것이 사회적 존재의 형태이기 때문에 사회적 존재를 결정하는 것이 옳지 않다는 것을 보여줍니다. 그리고 사회 의식 자체는 그것이 의미하는 것을 해석합니다. 전자가 변하지 않으면 후자는 변할 수 없습니다. | D 언어는 현재의 사회적 현상과 사람들의 심리학을 포착 할 수 있고, 언어는 사회적 의식을 반영하며 사회 의식은 언어에도 영향을 미칩니다. 사회 의식은 사회적 존재를 결정하고 언어가 사회적 의식을 반영하기 때문에 옵션 D는이 관점과 일치합니다. 따라서 언어는 사회 의식을 반영하고 사회적 의식은 언어에도 영향을 미칩니다. |
| linly-Chatflow-7b | linly-Chatflow-13b | |
|---|---|---|
| 왜 어떤 사람들은 GPS 장치 나 스마트 폰 앱에 의존하는 대신 종이지도를 사용하거나 지시를 찾는 이유는 무엇입니까? | 이 기술은 더 직관적이고 안전하며 실용적이기 때문에 사람들은 종이지도와 방향을 사용할 수 있습니다. GPS 기술과 비교할 때지도는 위치 정보가 아닌 더 많은 정보를 제공하여 경로를 개선 할 수 있습니다. 또한 GPS 시스템이 종종 손상되기 때문에 많은 수의 건물 주변에서 GPS 기술이 완벽하지 않은 경우가 있으며 종이지도와 방향이 더 안정적입니다. | 어떤 사람들은 경로 및 내비게이션 정보를 위해 종이지도 또는 기타 안내 도구를 사용하는 것을 선호 할 수 있습니다. 이 행동의 이유는 다음과 같습니다. 1. 자연의인지 경험 : 일부 사람들의 경우, 자연지도와 같은 지침 도구를 사용하는 것은 전자 장치를 사용하는 것보다 더 자연스럽고 진실하며 편안합니다. 그들은 전자 장치를 사용하여 몸과 주변 환경 사이의 연결을 방해하고 방해합니다. 2. 기술적 신뢰성 : 종이지도 또는 기타 안내 도구를 사용하는 악천후, 통신 네트워크 문제 또는 전력 장애 등과 같은 특정 상황에서는 내비게이션 프로세스의 안전성과 원활함을 더 잘 보장 할 수 있습니다. 3. 개인 취향 : 모든 사람마다 라이프 스타일과 습관이 다르며 일부는 전통적인 방법을 사용하여 고급 기술을 사용하기보다는 문제를 해결하는 것을 선호 할 수 있습니다. 4. 경제적 이익 : 종이지도는 전자 장치보다 상대적으로 저렴하며 종종 외출 해야하는 사람들에게는 한 번만 지불하면됩니다. |
| 정부는 어떻게 재정 및 통화 정책을 사용하여 경제 침체에 대응합니까? | 경제 경기 침체에 직면 할 때 정부는 재정 및 통화 정책과 같은 다양한 수단을 통해 국가 금융 시장을 규제하고 균형을 잡을 수 있습니다. 첫째, 중앙 은행에 유동성을 제공하고 영향을받는 회사에 대출 지원을 제공 할 수 있습니다. 또한, 정부는 또한 낮은이자 대출을 제공하고 대출 범위를 확대하여 가장 큰 영향을 미치는 소기업이 장기 개발 기회를 얻을 수 있도록합니다. | 경제 침체에 따라 정부는 다양한 재정 및 금전적 정책을 사용할 수 있습니다. 재정 정책에는 직접 보조금 제공, 인프라 프로젝트 수행 등이 포함됩니다. 또한, 보호 무역 정책도 구현 될 수 있으며 국내 소비를 자극하고 다른 국가 나 지역과의 협력을 높이기 위해 금융 기관과 같은 새로운 시설을 설립 할 수 있습니다. |
| 백신은 개인과 지역 사회를 전염병으로부터 어떻게 보호하고 무리 면제는 무엇입니까? | 백신은 개인의 면역계를 활성화시키고 해당 병원체에 대한 항원을 제공함으로써 특정 병원체에 대한 방어를 구축합니다. 무리 면역은 많은 수의 예방 접종이 어느 정도 "슈퍼 보호"를 달성 할 수 있음을 의미하며, 일부 사람들은 병원체에 감염 될 수없고 예방 접종을받을 필요가 없으므로 완전한 보호를 얻을 수 있습니다. 이것의 장점은 감수성이 충분하지 않을 때 병원체가 전염병을 유발하지 못하게 할 수 있으며, 예방 접종을 원하지 않거나 원하지 않는 사람들 (예 : 물리적 이유로 인해)을 보호 할 수 있다는 것입니다. 그들은 무리 면역과 유사한 보호를 얻을 수 있습니다. | 무리 면역은 전체 인구의 면역을 증가시키기위한 공유 예방 조치에 기초한 접근법입니다. 이 접근법은 예방 접종, 정기 검사 등과 같은 예방 조치가 질병에 노출 될 수있는 사회의 모든 사람들을 위해 필요합니다. 또한 모든 사람들이 적시에 효과적인 치료 서비스를 이용할 수 있도록 일련의 정책을 개발하고 구현해야합니다. 이러한 정책에는 공중 보건 교육 프로그램, 검사 및보고 메커니즘 강화, 더 많은 병원 및 기타 치료 시설을 설립하여 치료를받는 모든 환자가 최상의 치료를받을 수 있습니다. |
| 문화적, 사회적, 경제적 요인은 사람들의식이 선택에 어떤 영향을 미치며,이 지식은 어떻게 더 건강한식이 요법을 촉진하는 데 사용될 수 있습니까? | 사회, 문화 및 경제적 요인은 사람들의식이 선택에 중요한 영향을 미칩니다. 전통 문화에서 부모는 종종 자녀의 식단에 대한 가장 큰 의사 결정자이지만 현대 사회에서는 부모도 다른 요인들에 의해 방해됩니다. 예를 들어, 일부 연구에 따르면 고소도 사회에서 부모는 어린이가 재정적 요구를 충족시키기 위해 너무 많은 고속 식품을 먹도록 유도 할 가능성이 높습니다. 신선하고 유기농 과일과 채소에 접근 할 수 없다면, 그들은 가공 식품이나 저렴한 음식에만 의존하여 기아를 만족시켜 신체 건강 문제로 이어질 수 있습니다. | 오늘날의 사회에서는 다양한 문화적, 사회적, 경제적 요인의 영향으로 인해 사람들의식이 선택도 바뀌 었습니다. 예를 들어, 일부 지역은 설탕의 과도한 소비로 특징 지어 질 수 있습니다. 그러나식이 선택에 대한 다양한 문화적, 사회적, 경제적 요인의 영향을 연구 함으로써이 정보를 사용하여 대중의 식습관을 개선하고 더 건강한 식습관 목표를 달성하기위한 캠페인을 개발할 수 있습니다. |
| 소셜 미디어 플랫폼은 사람들이 뉴스에 접근하고 공유하는 방식에 어떤 영향을 미치며, 잘못된 정보의 확산에 어떤 영향을 미칩니 까? | 소셜 미디어 플랫폼은 사람들이 여러 가지 방법으로 뉴스에 액세스하고 공유하는 방법에 영향을 줄 수 있습니다. 첫째,이 플랫폼은 정보를 공유하고 공유하고 보급하기위한 큰 플랫폼을 제공하여 사용자가시기 적절한 뉴스 정보를보다 쉽게받을 수있게 해주 며, 소셜 미디어는 최신 뉴스를 즉시 볼 수 있으므로 행동에 영향을 줄 수 있습니다. 또한 소셜 미디어는 중상, 제작 및 말도 안되는 많은 문제를 일으켜 허위 정보가 보급되어 공개 이미지에 영향을 미칩니다. | 소셜 미디어 플랫폼은 사람들이 뉴스를 얻고 공유하는 방식을 바꿀 수 있습니다. 소셜 미디어는 사용자가 다른 사람들과 뉴스를 공유하고 액세스 할 수있을뿐만 아니라 콘텐츠를 게시하여 참여할 수있는 개방형 환경이므로, 이는 선전자에게 불만을 전 할 수있는 더 큰 기회를 제공합니다. 또한 소셜 미디어의 개방적 인 특성으로 인해 허위 뉴스는 매우 빠른 속도로 널리 퍼져서 사회적 혼란과 갈등을 악화시킬 것입니다. |
| linly-Chatflow-7b | linly-Chatflow-13b | |
|---|---|---|
| 최근 Apple은 Qualcomm을 고소하여 관련 계약에 따라 협력하지 못했다고 비난했습니다. 이 문장에서 누가 "그것"을 언급합니까? | 애플 주식회사 | 나는 "그것의"가 Qualcomm을 언급한다고 생각합니다. |
| 이때, 침대의 베개 옆에있는 휴대 전화가 울려 퍼졌습니다. 이 문장에서 "그것"은 무엇을 참조합니까? | 이 문장의 "It"는 침대의 베개 옆에있는 휴대 전화를 말합니다. | 위의 질문에 따라이 질문에 대답하면 "It"가 다른 품목이나 사람이 아닌 휴대 전화를 말하는 문장에서 볼 수 있습니다. |
| 문장 1 : "서부 지역의 개발 및 개방을위한 새로운 정책과 조치를 공식화하며, 서부 지역의 우선적 인 법인 소득세 정책은 계속해서 이행 될 것입니다." 서부 지역의 정책은 기업이 서구에서 발전하도록 장려합니다. "이 두 문장 사이의 관계는 무엇입니까? 옵션 : 시사, 모순, 관련이 없습니다 | 이 두 문장 사이의 관계는 수반됩니다. | 이 두 문장의 의미는 다음과 같습니다. 첫 번째 문장은 "서부 지역의 개발 및 개방을위한 새로운 정책과 조치를 공식화하고 만료 된 후 서부 지역의 기업 소득세 인센티브와 같은 정책을 계속 이행합니다." 두 번째 문장은 "서부 지역의 우선적 인 기업 소득세 정책은 기업이 서구에서 발전하도록 장려한다"고 언급했는데, 이는 첫 번째 문장에 공식화 된 정책이 서부 지역의 경제 발전을 촉진하는 데 중요한 역할을했음을 보여줍니다. 따라서 두 문장 사이에 의미가 있다고 말할 수 있습니다. |
| 문장 1 : "Jiang Lili가 다시 말했다 : 당신은 저녁에 여기에 있지 않으며, 당신은 오후에 여기에 있지 않습니다." 이 두 문장 사이의 관계? | 이 두 문장 사이의 논리적 관계는 원인과 결과입니다. 이전 문장은 후자의 문장으로 이어지기 때문입니다. | 위의 두 텍스트의 의미가 비슷한 지 확인 |
| 그러나 모든 사람들이 __ 였고 길을 걷지 않았던 기간이있었습니다. __ 위치에 어떤 관용구를 채워야합니까? A 격리에 살아 | 격리에 살고 있습니다 | 내 사고 과정은 다음과 같습니다. 옵션 D "Keep to Selfe"가 더 적절합니다. 이는 현 상태를 유지하거나 변경하지 않음을 의미합니다. 그것은 자신의 의무에 만족하고 행복하게 하루를 보내는 것으로 이해 될 수 있습니다. 이 관용구는 원래 "후기 한 앙 Qiong의 책"의 구절에서 나왔습니다. |
| linly-Chatflow-7b | linly-Chatflow-13b | |
|---|---|---|
| 3 학년 학생들은 4 학년과 5 학년 학생들이 14 개의 나무를 심었습니다. | X 나무가 3 학년에 심어 졌다고 가정하고, 4 학년에는 2 배의 나무가 심었고, 5 학년에 3 배의 나무가 심었다 고 가정 해 봅시다. 3 학년에는 총 80 그루의 나무가 심었으므로 x = 80. 이것을 우리가 얻는 방정식으로 대체하는 것 : 4 학년은 2 × 80 = 160 그루를 심었고, 5 학년은 3 × 80 = 240 그루를 심었고, 3 개의 등급은 총 160 + 240 + 240 = 540 그루를 심었습니다. | 3 학년에 심은 나무가 X라고 가정합니다. 4 학년과 5 학년에 심은 나무는 2x+14입니다. 3 학년과 4 학년 및 5 학년 학생들은 총 3 배+(2x+14) = 5x+14 그루를 심었습니다. 따라서 3 학년 동안 심은 나무의 수는 5x + 14입니다. 각 등급에 심은 나무의 수는 질문에 나와 있지 않기 때문에 X의 값을 결정할 수 없습니다. 그러나 확실한 것은 28 일 때입니다. 그런 다음 3 학년이 심은 나무의 수는 6 + 28 = 34 그루입니다. |
| 수업에는 총 50 명의 학생이 있으며, 30 명의 학생들이 탁구를 할 수 있으며, 10 명의 학생들은이 세 종류의 공을 연주 할 수 있습니다. | 각 스포츠가 수용 할 수있는 학생의 수를 추가하여 답을 얻을 수 있습니다. 30 + 40 + 10 = 80 따라서이 세 가지 유형의 공을 플레이 할 수있는 최대 학생 수는 80입니다. | 우리는이 문제를 해결하기 위해 사실적인 추론을 사용할 수 있습니다. 먼저 각 카테고리의 사람들 수와 3 개의 볼 스포츠 각각에서 다루는 총 학생 수를 나열하겠습니다. -탁구를하는 학생들의 수는 30 세입니다. -배드민턴을하는 학생의 수는 40 세입니다. -테니스를하는 학생의 수는 10입니다. 따라서 이러한 다양한 활동 중에서 두 가지를 선택하면 두 가지 관련 정보 세트가 있습니다. - 탁구와 배드민턴 만 연주되면 총 70 명의 학생들 이이 두 스포츠에 참여할 것입니다. - 탁구와 테니스 만 재생되면 총 60 명의 학생들 이이 두 스포츠에 참여할 것입니다. - 배드민턴과 테니스 만 연주되면 총 90 명의 학생들 이이 두 스포츠에 참여할 것입니다. 이제 세 가지 스포츠가 모두 결합 될 때 총 학생 수를 계산해야합니다. 이러한 방식으로 다음 공식을 계산할 수 있습니다. 학생 수 = 탁구를하는 학생 수 + 배드민턴을하는 학생 수 - 테니스를하는 학생 수 = 30 + 40-10 = 80 따라서 우리는이 세 가지 유형의 공을 연주 할 수있는 최대 80 명의 학생들이 있다고 결론을 내립니다. |
| 사과 나무보다 78 개의 배 나무가 있으며, 사과 나무와 사과 나무보다 4 배가 많습니까? | 사과 나무의 수가 X라고 가정하고 배 나무의 수는 78*4 = 312라고 가정합니다. 따라서 X + 312 배와 사과 나무가 결합되어 있습니다. 질문의 의미에 따라 방정식을 얻을 수 있습니다. x + 312 =? 방정식의 왼쪽으로 312를 이동하면 다음과 같습니다. x =? -312 질문에 X가 주어지지 않기 때문에 답을 찾을 수 없습니다. | 사과 나무의 수가 X라고 가정하고 배 나무의 수는 4x+78입니다. 질문의 의미에 따르면, 우리는 다음을 얻을 수 있습니다 : x+(4x+78) = 216. 얻기 위해 단순화 : 5x = 138. 따라서 x = 27.6 (둥근). 따라서 사과 나무의 수는 27이고 배 나무의 수는 109입니다. |
| 수업에는 30 명의 학생이 있으며 그 중 2/3은 소년이 몇 명입니까? | 1. 소년 수 계산 : -16.7 ≈ 17을 얻기 위해 "30"(즉, 소년의 비율)를 곱하십시오. 2. 수업에는 정수 수가 많기 때문에 소녀 수를 18로 얻으려면 결과를 반올림해야합니다. | 먼저이 수업에서 소년의 수를 찾으십시오. 다음 공식을 사용하여 계산할 수 있습니다. 소년 수 = 총 사람 수 × 비율이 질문에 주어진 값을 공식으로 대체하는 비율 : 소년 수 = 30 × 2/3 얻기 위해 단순화 : 소년의 수 = 20 그런 다음 소년 수를 빼서 소녀의 수를 얻을 수 있습니다. 여자의 수 = 소년의 총 수 - 소년 수 : 소녀의 수 = 30-20 따라서 수업에는 10 명의 소녀가 있습니다. |
| 학생들은 라디오 연습에서 경쟁했으며 전체 계급은 6 줄로 줄을 섰습니다. Xiaohong은 처음부터 5 위를 차지하고 있습니다. | 전체 수업이 Xiaohong을 중심으로한다는 질문에서 볼 수 있으므로 답을 얻기 위해 Xiaohong의 입장 만 계산하면됩니다. 수업에 X 사람들이 있다고 가정하면 Xiaohong의 입장은 다음과 같습니다. $$ x div 2 + 1 = x -1 $$ Xiaohong은 5 위를 차지합니다. 즉, 처음 4 명이 그녀 앞에 결승선에 도달 했으므로 세 번째 줄과 네 번째 행 사이에 배포되어야합니다. 세 번째 위치에서. 네 번째 위치에 있으므로 다음 방정식을 나열 할 수 있습니다. $$ x -4 = 6 $$ 위의 방정식을 해결하면 총 수를 얻을 수 있습니다. | 1. 먼저 질문의 의미를 명확하게 설명하십시오. Xiaohong은 두 번째 줄에, 처음부터 5 위, 끝에서 세 번째는입니다. 따라서 두 번째 행의 사람들의 수는 2x (8-5-3) = 3이라고 결론 지을 수 있습니다. 2. 다음으로 수업 시간에 사람들의 수를 세십시오. 클래스는 6 개의 동일한 행으로 나뉩니다. 각 행의 사람들의 수는 동일해야합니다. 각 행의 사람들의 수가 X라고 가정하고, 수업의 총 사람 수는 6 배입니다. 3. 두 번째 줄에서 Xiaohong의 위치를 공식으로 대체하면 두 번째 행의 사람들의 수가 3이면 방정식을 나열 할 수 있습니다. 6x = 3 + (앞에있는 사람 수) × x 4. 방정식을 해결하고 x = 24/7≈3.43을 얻지 만 실제로 정수가 필요하므로 반올림해야하며 최종 결과는 4입니다. 5. x = 4를 원래 공식으로 대체하면 클래스의 총 직원 수를 6 × 4 = 24로 얻을 수 있습니다. 따라서 수업에는 총 24 명이 있습니다. |
| linly-Chatflow-7b | linly-Chatflow-13b | |
|---|---|---|
| 오케스트라의 공연과 관객의 전반적인 경험을 논의하는 심포니 콘서트 리뷰를 작성하십시오. | 이번 주말에 나는 잘 알려진 심포니 오케스트라가 공연하는 콘서트에 참석하게되어 기뻤습니다. 그룹의 새 앨범의 테마 트랙 중 하나 인 그들은 관객에게 잊을 수없는 공연을주었습니다. 우선, 오케스트라의 지휘자는 찬사를받을 자격이 있습니다. 그의 운전 능력은 인상적입니다. 그는 일련의 뛰어난 컨트롤을 통해 각 음악가의 기술과 감정을 성공적으로 결합하여 설명 할 수없는 마법을 보여주었습니다. 콘서트가 시작될 때, 오케스트라의 첫 번째 작품은 가볍고 활기차고 관객의 마음을 크게 감동 시켰습니다. 다음 곡도 매우 전염성이 있으며 오케스트라의 시너지로 인해 모든 노래가 생생하고 신선 해집니다. 특히 언급할만한 가치는 부국장이 노래 사이의 전환을 자연스럽고 매끄럽게 만드는 데주의를 기울여 전체 공연을보다 완벽하게 만듭니다. 또한이 쇼는 창의적인 요소 인 시각 효과도 소개했습니다. 전체 콘서트 장소의 분위기를 더욱 강렬하게 만들기 위해 무대에 여러 LED 화면이 설정되었습니다. 음악 조각이 완성되면 해당 그림 또는 텍스트 내용이 화면에 표시되어 관객이 더 깊은 수준에서 공연 뒤에 전달 된 아이디어를 이해할 수 있습니다. 이러한 창의성은 청중에게 더 나은 경험을 제공 할뿐만 아니라 음악의 다양성과 포괄 성을 보여줍니다. 마지막으로 콘서트의 전반적인 세부 사항을 언급 할 가치가 있습니다. 음향은 절묘하고 모든 악기는 생생하게 연주됩니다. 콘서트 사이트의 레이아웃도 매우 합리적이며 볼륨은 중간 정도입니다. 나는 이것이 매우 성공적인 콘서트라고 생각합니다. | 콘서트 테마 : Bach와 Haydn은 작동합니다. 참가자에는 연령대가 다른 사람들, 교육 수준 및 음악적 문해력이 포함됩니다. 이 장소는 중앙에 무대가 있으며 양쪽에 좌석이 있으며 뒤쪽에는 작은 오케스트라가 설계되었습니다. 이 콘서트는 연령, 교육 수준 및 음악적 문해력이 다른 청중으로 구성되어 있습니다. 이러한 다양한 청중에서 오케스트라는 뛰어난 기술 기술과 뛰어난 음악 공연 기능을 시연했습니다. 우선, 오케스트라는 바흐와 헤이든의 작품을 완벽하게 결합하여 전체 콘서트를 매우 매끄럽고 일관성있게 만들었습니다. 그들의 따뜻하고 멜로디 한 공연은 모든 청중에게 깊은 충격과 끝없는 뒷맛을 가져 왔습니다. 첫 번째 작품에서 마지막 노래에 이르기까지 밴드는 음악에 대한 그들의 미덕과 깊은 이해에 깊은 인상을 받았습니다. 또한 오케스트라는 느린 섹션, 빠른 문자열 부품 등과 같은 일련의 놀라움을 제공하여 음악의 내용을 크게 풍부하게합니다. 특히, 리듬 변화와 정서적 변화에 대한 오케스트라의 강조는 이러한 고전적인 작품의 의미를 더 잘 해석하여 관객이 음악의 의미를 진정으로 느낄 수있게합니다. |
| 스트리밍 플랫폼이 음악 산업에 미치는 영향을 논의하는 팟 캐스트 스크립트 작성. | 스트리밍 플랫폼이 음악 산업에 미치는 영향과 가능한 장단점에 대한 컨텐츠를 제공 하여이 주제에 대한 팟 캐스트 스크립트를 작성할 수 있습니다. 예를 들어: - 온라인 스트리밍 플랫폼이 음악 환경을 바꾸고 있습니까? - 제작자가 자신의 작품을보다 광범위하게 마케팅하는 데 도움이됩니까? - 가능한 경쟁 및 저작권 문제 등 제목 : 스트리밍 플랫폼 및 음악 산업에 미치는 영향 장면 1 : 소개 호스트 : 오늘 우리는 스트리밍 플랫폼이 음악 산업에 미치는 영향을 논의 할 것입니다. 장면 2 : 디지털 분포의 과제 게스트 : 음악가로서 스트리밍의 상승은 아티스트가 새로운 청중에게 다가 갈 수있는 좋은 기회를 보았지만, 디지털 배포와 관련하여 도전을 만들어 냈습니다. 그들의 작업은 어디에서나 사용할 수 있습니까? 장면 3 : 스트리밍 대 물리 판매 게스트 : 물리적 판매 및 스트리밍에 대한 이점이 있지만, 두 가지 모델은 항상 보완적인 것은 아닙니다. 음악 산업? 장면 4 : 신흥 예술가를위한 기회 게스트 : 스트리밍 서비스는 신흥 아티스트에게 음악에 쉽게 접근 할 수 없었으며 물리적 배포가 필요하지 않으면서도 그 어느 때보 다 빠르게 노출 될 수 있습니다. 장면 5 : 잠재적 인 함정 게스트 : 음악 스트리밍 혁명의 모든 측면이 로열티 및 스트리밍 권한과 같은 문제와 함께 스트리밍 서비스가 예술가와 팬의 요구와 균형을 이루는 것은 아닙니다. 더 큰 음악 산업? 장면 6 : 결론 호스트 : 오늘 손님들에게 변화하는 스트리밍 환경과 음악 산업에 대한 그 영향에 대한 활발한 토론을 해왔습니다. | 주제 : Spotify, Apple Music 및 Tidal을 포함한 음악 스트리밍 플랫폼에 대해 어떻게 생각하십니까? 그리고 그들은 음악 산업 환경을 바꿨습니까? 대상 청중 : 음악에 관심이 있고이 분야의 미래 발전에 관심이있는 사람들. 제목 :“Spotify, Apple Music 및 Tidal : 음악 세계 변경 또는 전통적인 비즈니스 모델 파괴?” 소개 : 지난 20 년 동안 음악 산업의 개발, 특히 음악 소비자가 디지털 시대의 스트리밍 미디어 플랫폼으로 전환 한 변화를 도입했습니다. 제목 : 예를 들어, 지지자들은 이러한 플랫폼이 음악의 순환을 증가시키고 음악가들이 대중에게 더 접근 할 수있게한다고 생각합니다. 이를 바탕으로 이러한 플랫폼이 마케팅 채널 및 앨범 제작 비용과 같은 측면을 포함하여 음악 비즈니스 모델 및 시장에 어떤 영향을 미치는지 조사 할 것입니다. 또한 예술가와 음악가의 이익을 보호하기 위해 유사한 권리 관리 체계를 채택하거나 새로운 비즈니스 기회를 창출하기 위해 스트리밍 서비스에 유료 옵션을 추가하는 것과 같은 몇 가지 가능한 솔루션에 대해 논의 할 것입니다. |
| 최근에 발표 된 공상 과학 영화에 대한 매력적인 리뷰를 작성하여 음모, 캐릭터 및 특수 효과를 논의하십시오. | 영화 이름 : "Interstellar" "Interstellar"는 흥미롭고 잊을 수없는 공상 과학 영화로, 새 집을 찾기 위해 벌레 홀을 통해 외부로 여행하는 우주 비행사 그룹의 이야기를 들려줍니다. 이 알려지지 않은 신비한 모험에서 그들은 수많은 위험과 도전에 직면했습니다. 영화의 음모는 매우 복잡하며 주제에는 시간, 공간 및 상대성과 같은 심오한 물리적 문제가 포함됩니다. Christopher Nolan 감독은 이러한 개념을 활기차고 흥미로운 스토리 라인과 능숙하게 결합하여 전체 영화를 매우 매력적으로 만듭니다. 영화의 등장 인물도 매우 좋습니다. Matthew McConaughey가 연기 한 Cooper는 자신의 가족의 도전에 직면 한 40 명의 우주 비행사입니다. Anne Hathaway가 연기 한 Murph는 작지만 귀중한 풀크가되어 Cooper가 믿음과 희망을 되 찾을 수있게했습니다. 영화의 영상도 칭찬 할 만하다. 눈부신 우주 항공편에서 놀라운 블랙홀 이미지에 이르기까지 모든 프레임은 뛰어난 디자인과 제작을 보여줍니다. 또한 음악은 또한이 영화에 매우 적합하여 줄거리 개발과 일치하고 매우 긴장된 분위기를 조성합니다. 요컨대, "Interstellar"는 관객의 관심을 끌뿐만 아니라 사고를 자극하는 매우 훌륭한 공상 과학 영화입니다. 공상 과학 영화를 좋아하거나 물리 세계의 경이로움을 탐구하고 싶다면이 영화는 잊을 수없는 경험을 제공 할 것입니다. | "Wandering Earth"는 태양이 불에 타면 생존이 위협받는 미래 세계의 주요 이야기를 기본 선으로 취하는 흥미로운 공상 과학 영화입니다. 이 영화는 시각 효과에서 뛰어난 업적을 보여주고 훌륭한 우주 세계를 만듭니다. 주인공은 또한 수많은 장애물을 극복하고 지구를 보호하기 위해 다른 사람들과 협력해야하기 때문에 훌륭합니다. 이 영화는 시각적 아름다움뿐만 아니라 이데올로기 적 내용에 대해서도 깊은 인상을 남겼습니다. |
| 최근 베이징 여행에 대한 흥미로운 여행 블로그 게시물을 작성하여 문화 경험과 꼭 방문해야 할 명소에 중점을 둡니다. | 최근에 나는 베이징에 가서 그레이트 벽, 금지 된 도시 및 기타 명소를 방문했습니다. 그곳에서 나는 또한 지역 음식을 맛보고 중국 전통 문화 활동을 경험했습니다. 이 입력을 기반으로 여행에 대한 흥미로운 블로그 게시물을 작성하십시오. 나는 최근에 중국의 수도 베이징에 갔다. 이 도시는 현대성과 고대의 조화로 방문객들에게 문화 경험과 관광 명소를위한 수많은 옵션을 제공합니다. 내 여행 일기와 제안은 다음과 같습니다. 첫 번째 정지 : 큰 벽 큰 벽은 베이징의 랜드 마크 중 하나이며 세계에서 가장 인기있는 관광지 중 하나입니다. 산을 걷고, 높이 올라가서 멀리를 바라 보면, 당신은 큰 벽으로 대표되는 웅장 함과 중요성을 느낄 수 있습니다. 두 번째 정류장 : 금지 된 도시 금지 된 도시는 방문 할 가치가있는 곳입니다. 그것은 명나라와 Qing 왕조의 황제의 궁전이었으며 현재 박물관으로 개조되었습니다. 여기에서 많은 역사적 유물과 장식을 볼 수 있습니다. 세 번째 정지 : 레스토랑 베이징의 음식 문화에는 로스트 오리와 Xiaolongbao를 포함한 심오한 유산이 있습니다. Wangfujing Snack Street 또는 Qianmen Street 근처의 레스토랑으로 향하는 것이 좋습니다.이 장소는 실제 지역 전문 분야를 제공합니다. 네 번째 정지 : 공원 베이징에는 여름 궁전과 천국 공원과 같은 아름다운 공원이 많이 있습니다. 이 장소에서 휴식을 취하고 자연의 아름다움을 즐길 수 있습니다. 중지 5 : 문화 경험 명소와 음식 외에도 나는 문화 활동에도 참여했습니다. 나는 태극권을 배우고 한피를 입고 민속 예술가 공연에 갔다. 이러한 경험을 통해 중국 문화를 더 잘 이해하고 감사 할 수있었습니다. 요컨대, 베이징은 역사와 문화가 풍부한 도시입니다. 여기에서 여러 문화 관습을 경험하고 맛있는 음식을 맛볼 수 있습니다. 새로운 것을 탐구하고 문화를 경험하는 것을 좋아한다면 베이징 여행을 강력히 추천합니다! | 우선, 중국인에게 베이징은 음식 낙원뿐만 아니라 역사, 문화 및 현대 생활을 완벽하게 결합한 도시입니다. " 문화체험 1. 큰 벽 2. 금지 된 도시 3. Tiananmen Square 4. 798 아트 디스트릭트 5. 다 의도 경험 6. 식당에서 전통적인 베이징 요리를 맛보십시오 명소를 방문해야합니다 1. 큰 벽 2. 금지 된 도시 3. Tiananmen Square 4. 여름 궁전 5. 천국 공원의 사원 또한, 우리는 국수 만들기, 도자기 만들기 등을 포함하여 중국 수도에서 전통 공예품을 경험할 수 있습니다. 밤에 휴식을 취하고 싶다면 Qianmen Street와 Sanlitun Bar Street는 매우 좋은 선택입니다. 대체로 베이징은 방문 할 가치가있는 도시입니다. 당신이 문화 애호가이든 쇼핑을 좋아하는 사람이든, 도시는 당신이 새로운 것을 발견하기에 충분한 장소를 가지고 있습니다. |
| 컴퓨터 과학 분야의 논문에 대한 초록을 작성하십시오. | 이 연구는 인공 지능 모델의 성능과 효과를 개선하는 것을 목표로합니다. 특히 대규모 데이터 세트에 대한 응용 프로그램에서. 우리는 딥 러닝 기술을 활용하여 모델을 훈련시키고 매개 변수를 최적화하여 더 나은 결과를 얻을 것입니다. 이 연구는 성능과 효과를 향상시켜 대규모 데이터 세트 응용 프로그램에서 인공 지능 모델의 성능과 효과를 향상시키는 것을 목표로합니다. 우리는 딥 러닝 기술을 사용합니다 |


