duplicut
v2.2 release
요즘 비밀번호 단어 목록 생성은 일반적으로 여러 데이터 소스를 연결하는 것을 의미합니다.
이상적으로는 대부분의 가능한 비밀번호가 단어 목록의 시작 부분에 있어야 하므로 가장 일반적인 비밀번호는 즉시 해독됩니다.
기존 중복 제거 도구를 사용하면 순서를 유지할지 아니면 대규모 단어 목록을 처리할지 선택해야 합니다.
불행하게도 단어 목록을 생성하려면 다음 두 가지가 모두 필요합니다 .

그래서 저는 매우 구체적인 요구 사항을 해결하기 위해 고도로 최적화된 C로 duplicut을 작성했습니다.
git clone https://github.com/nil0x42/duplicut
cd duplicut/ && make
./duplicut wordlist.txt -o clean-wordlist.txt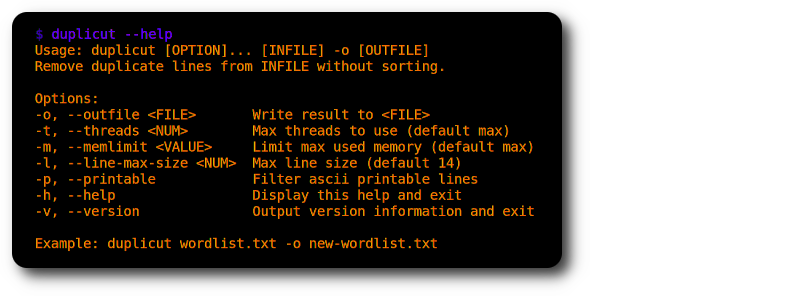
특징 :
-l 옵션)-p 옵션)구현 :
제한 사항 :
uint64 는 포인터의 추가 비트 내에 size 정보를 패킹하여 해시맵의 행을 색인화하는 데 충분합니다.
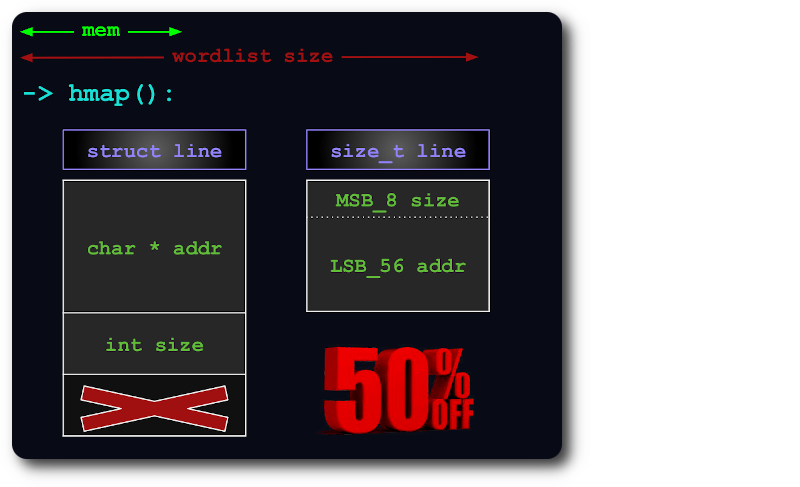
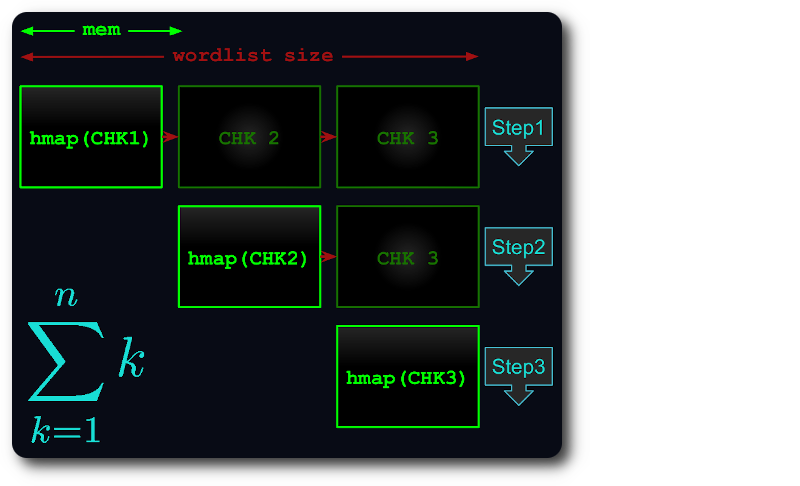
전체 파일이 메모리에 맞지 않으면 각 청크가 가능한 한 많은 RAM을 사용하는 방식으로 가상 청크로 분할됩니다.
그런 다음 각 청크는 해시맵에 로드되고 중복 제거되며 후속 청크에 대해 테스트됩니다.
이렇게 하면 실행 시간이 최대 세 번째 삼각형 수로 줄어듭니다.
버그를 발견하거나 예상대로 작동하지 않는 경우 디버그 모드에서 duplicut을 컴파일하고 첨부된 출력과 함께 문제를 게시하세요.
# debug level can be from 1 to 4
make debug level=1
./duplicut [OPTIONS] 2>&1 | tee /tmp/duplicut-debug.log



