LLaMA_MPS
1.0.0
Apple Silicon GPU에서 LLaMA(및 Stanford-Alpaca) 추론을 실행하세요.
보시다시피, 다른 LLM과 달리 LLaMA는 어떤 식으로든 편견이 없습니다.
1. 이 저장소를 복제하세요
git clone https://github.com/jankais3r/LLaMA_MPS
2. Python 종속성 설치
cd LLaMA_MPS
pip3 install virtualenv
python3 -m venv env
source env/bin/activate
pip3 install -r requirements.txt
pip3 install -e . 3. 모델 가중치를 다운로드하여 models 이라는 폴더에 넣습니다 (예: LLaMA_MPS/models/7B ).
4. (선택 사항) 모델 가중치(13B/30B/65B)를 다시 분할합니다.
단일 GPU에서 추론을 실행하고 있으므로 더 큰 모델의 가중치를 단일 파일로 병합해야 합니다.
mv models/13B models/13B_orig
mkdir models/13B
python3 reshard.py 1 models/13B_orig models/13B5. 추론 실행
python3 chat.py --ckpt_dir models/13B --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
위 단계를 통해 '자동 완성' 모드에서 원시 LLaMA 모델에 대한 추론을 실행할 수 있습니다.
Stanford Alpaca의 미세 조정된 가중치를 사용하여 ChatGPT와 유사한 '명령-응답' 모드를 시도하려면 다음 단계에 따라 설정을 계속하세요.
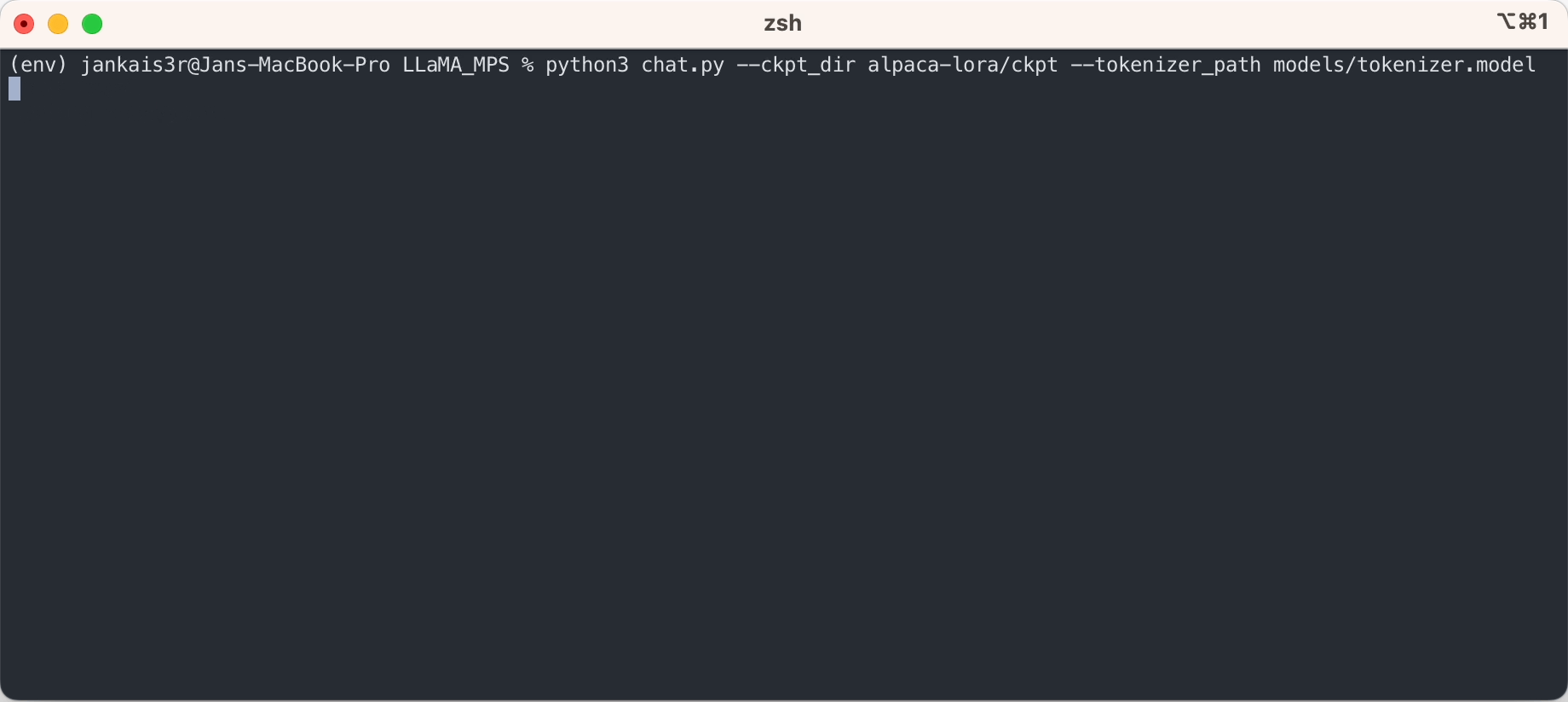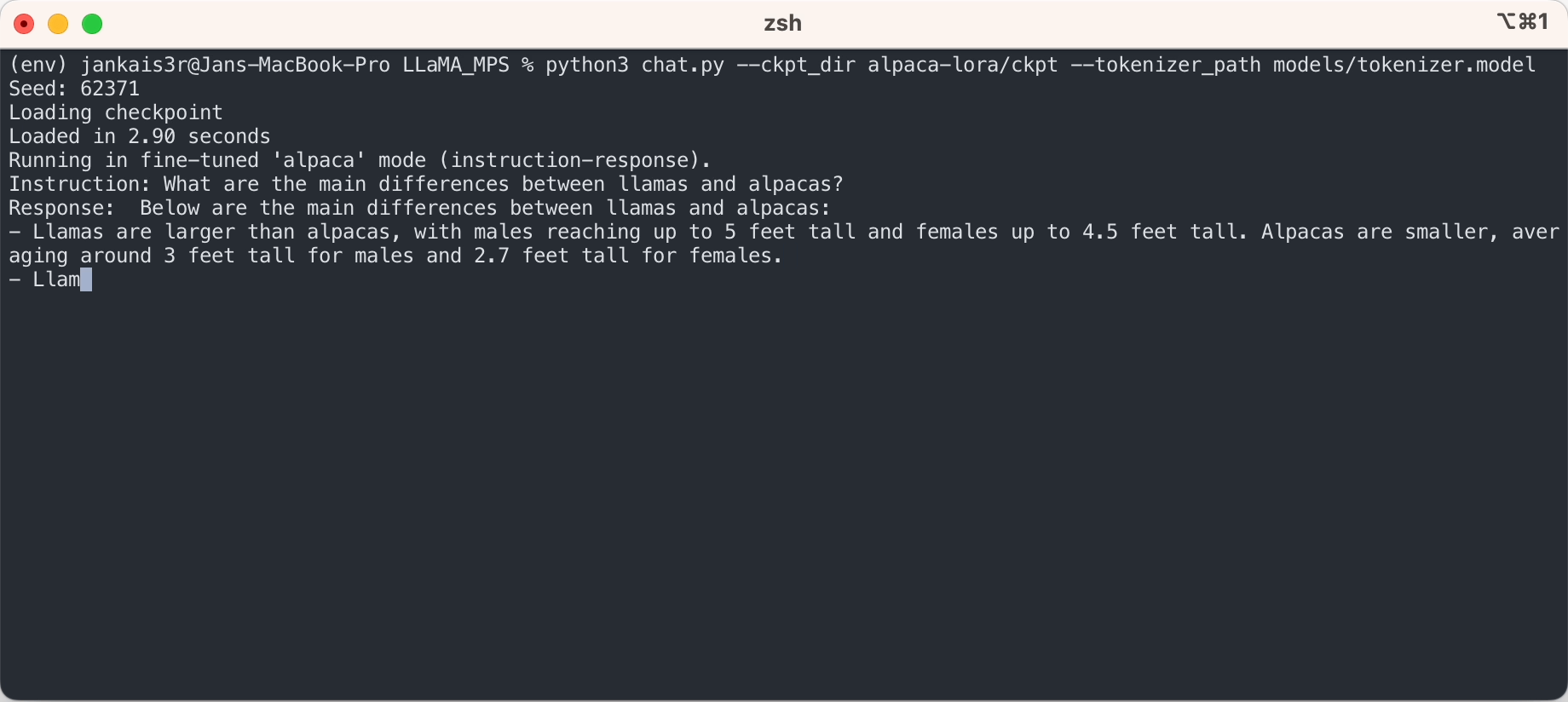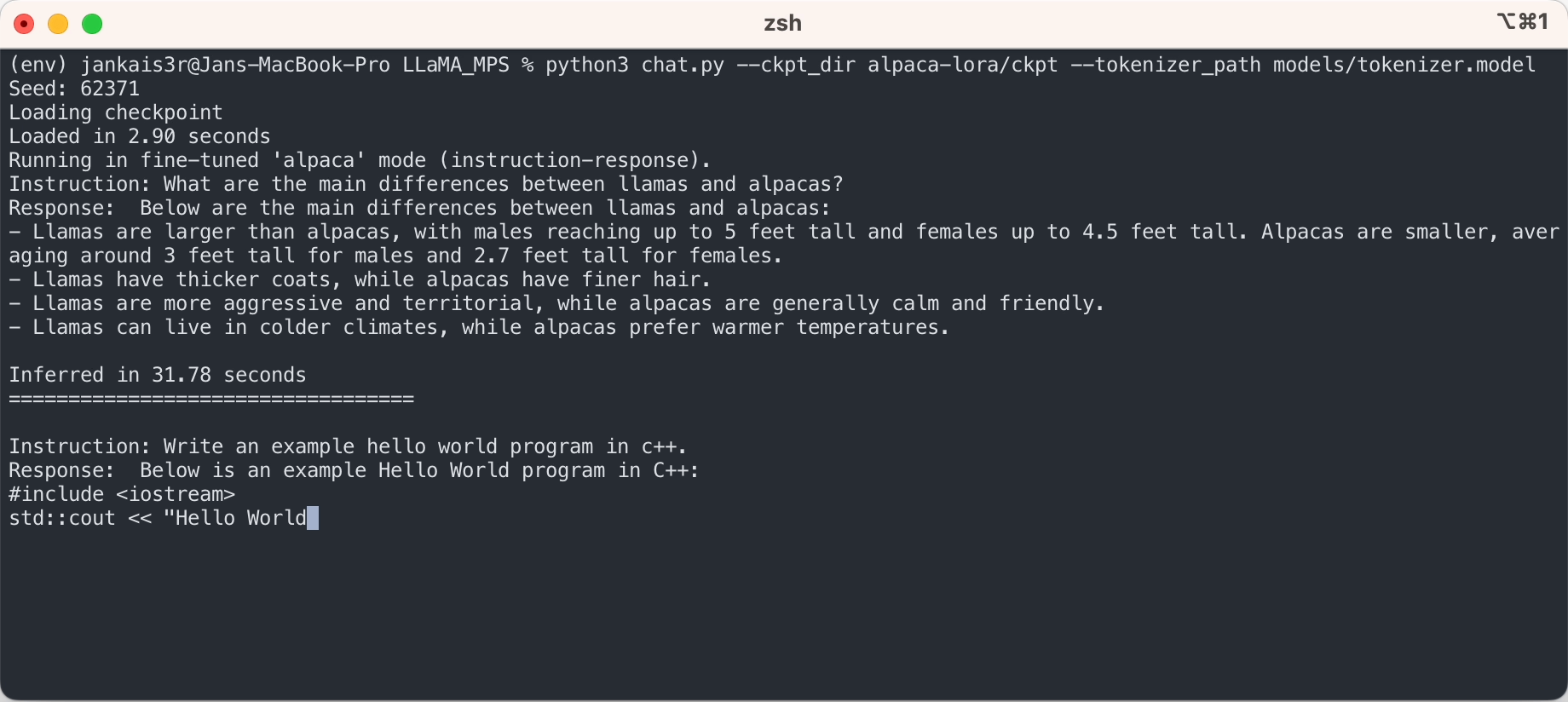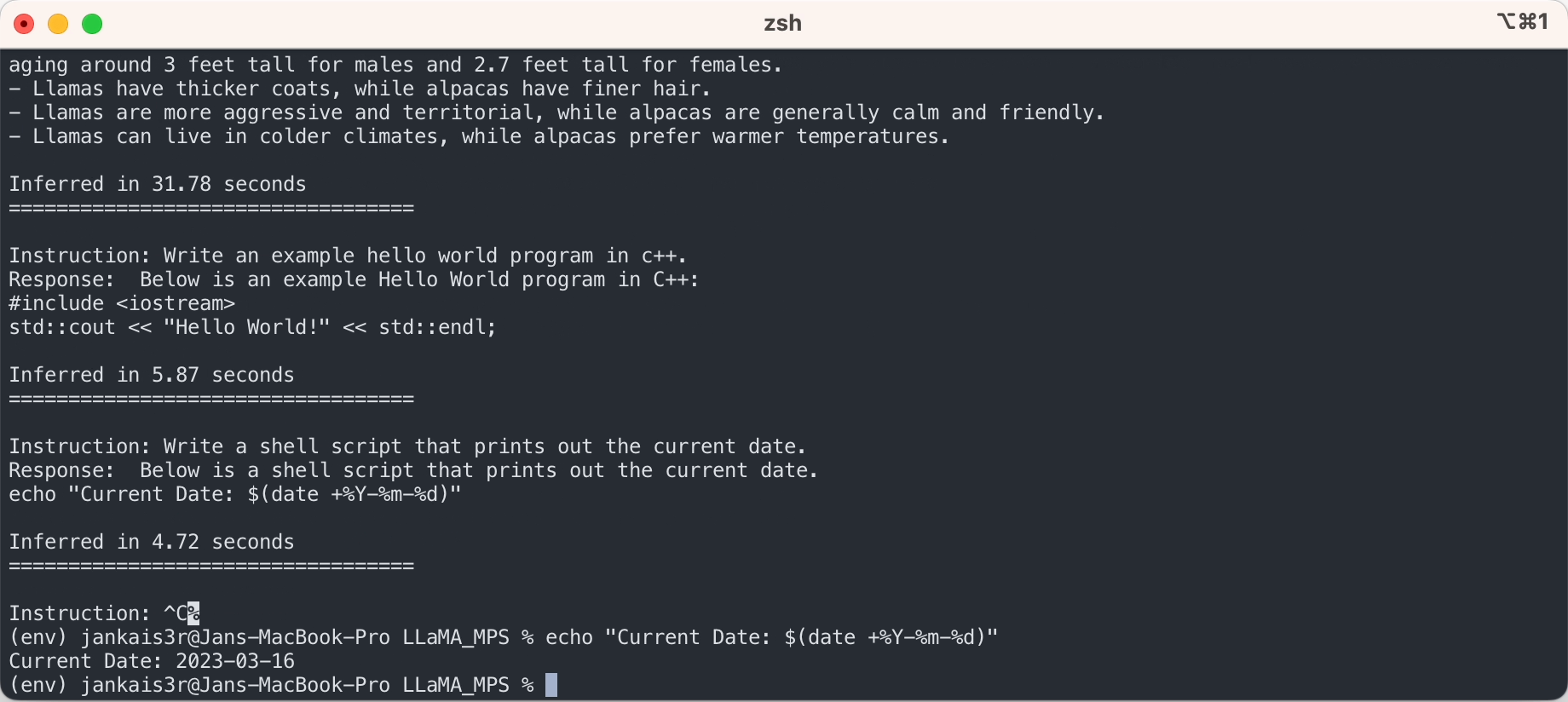
3. 미세 조정된 가중치 다운로드(7B/13B에서 사용 가능)
python3 export_state_dict_checkpoint.py 7B
python3 clean_hf_cache.py4. 추론 실행
python3 chat.py --ckpt_dir models/7B-alpaca --tokenizer_path models/tokenizer.model --max_batch_size 8 --max_seq_len 256
| 모델 | 추론 중 메모리 시작 | 체크포인트 변환 중 최대 메모리 | 리샤딩 중 최대 메모리 |
|---|---|---|---|
| 7B | 16GB | 14GB | 해당 없음 |
| 13B | 32GB | 37GB | 45GB |
| 30B | 66GB | 76GB | 125GB |
| 65B | ?? GB | ?? GB | ?? GB |
모델당 최소 사양(교체로 인해 느림):
모델별 권장 사양:
- max_batch_size
여유 메모리가 있는 경우(예: 64GB Mac에서 13B 모델을 실행하는 경우) --max_batch_size=32 인수를 사용하여 배치 크기를 늘릴 수 있습니다. 기본값은 1 입니다.
- max_seq_len
생성된 텍스트의 최대 길이를 늘리거나 줄이려면 --max_seq_len=256 인수를 사용하세요. 기본값은 512 입니다.
- use_repetition_penalty
예제 스크립트는 반복적인 콘텐츠를 생성하는 모델에 불이익을 줍니다. 이렇게 하면 출력 품질이 높아지지만 추론 속도가 약간 느려집니다. 페널티 알고리즘을 비활성화하려면 --use_repetition_penalty=False 인수를 사용하여 스크립트를 실행하십시오.
Apple Silicon 사용자를 위한 LLaMA_MPS의 가장 좋은 대안은 llama.cpp입니다. 이는 SoC의 CPU 부분에서만 추론을 실행하는 C/C++ 재구현입니다. 컴파일된 C 코드는 Python보다 훨씬 빠르기 때문에 실제로 속도에서는 MPS 구현을 능가할 수 있지만 전력 및 열 효율성은 훨씬 떨어집니다.
사용 사례에 더 적합한 구현을 결정할 때 아래 비교를 참조하세요.
| 구현 | 총 실행 시간 - 256개 토큰 | 토큰/초 | 최대 메모리 사용 | 최고 SoC 온도 | 최고 SoC 전력 소비 | 1Wh당 토큰 |
|---|---|---|---|---|---|---|
| LLAMA_MPS(13B fp16) | 75초 | 3.41 | 30GB | 79°C | 10W | 1,228.80 |
| 라마.cpp (13B fp16) | 70초 | 3.66 | 25GB | 106°C | 35W | 376.16 |


