SpaceFusion
1.0.0
NAACL'19 논문의 코드/데이터 신경 반응 생성의 다양성과 관련성을 공동으로 최적화
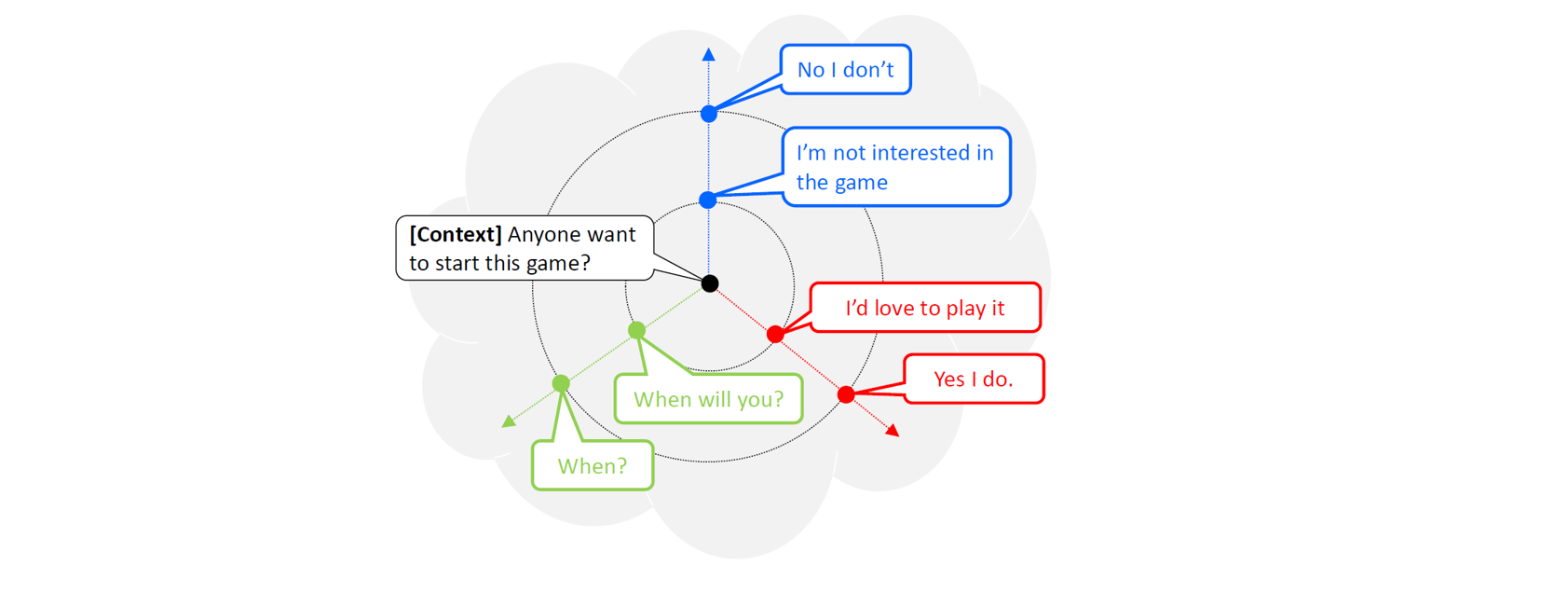
SpaceFusion은 다양한 데이터 세트에 대해 훈련된 다양한 모델에서 학습한 구조화되지 않은 잠재 공간을 정렬하고 구조화하기 위해 제안된 정규화된 다중 작업 학습 패러다임입니다. 특히 흥미로운 점은 생성된 응답의 관련성과 다양성을 공동으로 최적화하기 위해 SpaceFusion을 사용하는 신경 대화 모델링에 대한 적용입니다.
추가 문서:
NAACL'19의 우리 논문(장문, 구두).
NAACL'19에서 발표된 슬라이드.
직관과 시사점을 논의하기 위해 MSR 블로그를 게시했습니다.
후속작인 StyleFusion at EMNLP'19
EMNLP'20의 최신 대화 평가/순위 모델인 DialogRPT
코드는 Python 3.6 및 Keras 2.2.4를 사용하여 테스트되었습니다.
우리는 디버깅을 위해 Reddit을 생성하고 스위치보드 데이터 세트와 이 저장소의 장난감 데이터 세트를 처리하는 스크립트를 제공했습니다.
자세한 내용은 여기를 확인하시기 바랍니다.
SpaceFusion 모델을 훈련하려면: python src/main.py mtask train --data_name=toy
학습된 잠재 공간을 시각화하려면: python src/vis.py --data_name=toy
훈련된 모델과 상호작용하려면: python src/main.py mtask interact --data_name=toy --method=? , 여기서 방법은 greedy , rand , sampling 또는 beam 일 수 있습니다. 우리는 신문에서 rand 사용했습니다
훈련된 모델로 테스트하기 위한 가설을 생성하려면: python src/main.py mtask test --data_name=toy
생성된 가설을 평가하려면 python src/eval.py --path_hyp=? --path_ref=? --wt_len=? , 이는 논문에 정의된 정밀도, 재현율 및 F1을 출력합니다. 먼저 이 명령을 -len_only 와 함께 실행하여 가설과 참조의 평균 길이(토큰 수) 간의 차이를 최소화하는 적절한 wt_len 찾을 수 있습니다.
main.py 가 메인 파일입니다
model.py SpaceFusion 모델( class MTask 참조)과 일부 기준선을 정의합니다.
vis.py 잠재 공간을 시각화하고 분석하는 데 사용한 함수를 정의합니다.
dataset.py 데이터 피더를 정의합니다.
shared.py 기본 하이퍼파라미터를 정의합니다.
이 저장소가 귀하의 작업에 영감을 주었다면 NAACL 논문을 인용해 주세요 :)
@article{gao2019spacefusion,
title={Jointly Optimizing Diversity and Relevance in Neural Response Generation},
author={Gao, Xiang and Lee, Sungjin and Zhang, Yizhe and Brockett, Chris and Galley, Michel and Gao, Jianfeng and Dolan, Bill},
journal={NAACL-HLT 2019},
year={2019}
}