Okapi
1.0.0
오카피
인간 피드백을 통한 강화 학습을 통해 여러 언어로 학습 조정된 대규모 언어 모델
이는 여러 언어로 된 인간 피드백(RLHF)의 강화 학습을 통해 대규모 언어 모델(LLM)에 대한 명령 조정을 위한 리소스와 모델을 소개하는 Okapi 프레임워크용 저장소입니다. 우리 프레임워크는 8개의 고자원 언어, 11개의 중간 자원 언어, 7개의 저자원 언어를 포함하여 26개 언어를 지원합니다.
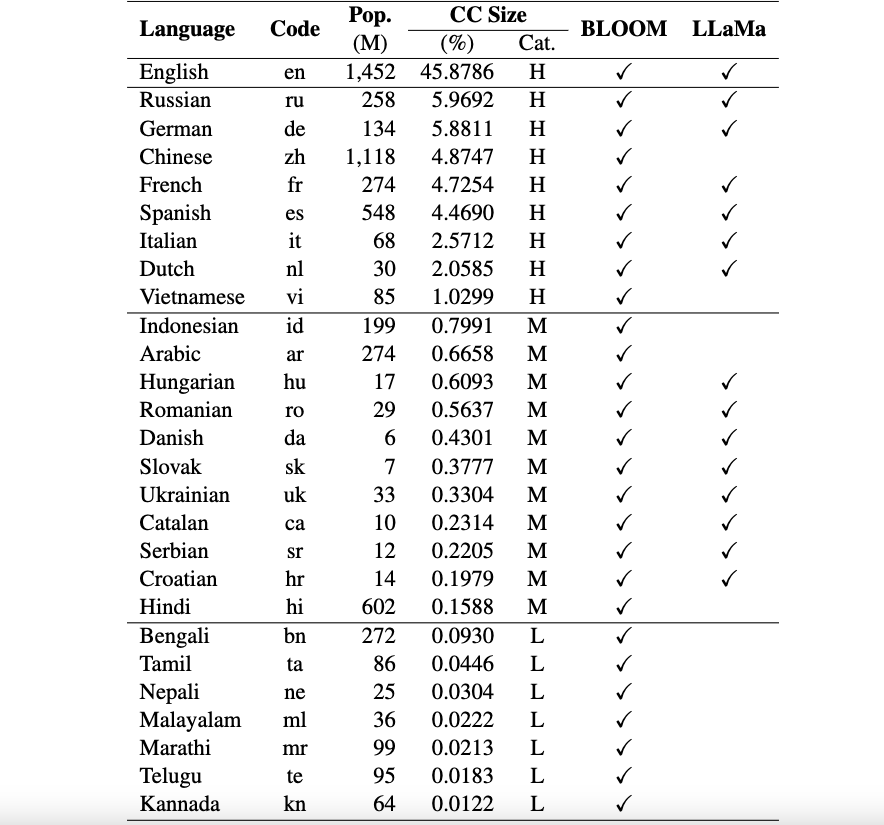
Okapi 리소스 : ChatGPT 프롬프트, 다국어 지침 데이터 세트 및 다국어 응답 순위 데이터를 포함하여 26개 언어에 대해 RLHF를 사용하여 지침 튜닝을 수행할 수 있는 리소스를 제공합니다.
Okapi 모델 : Okapi 데이터 세트에서 26개 언어에 대한 RLHF 기반 지침 조정 LLM을 제공합니다. 우리 모델에는 BLOOM 기반 버전과 LLaMa 기반 버전이 모두 포함됩니다. 또한 모델과 상호 작용하고 리소스를 사용하여 LLM을 미세 조정할 수 있는 스크립트도 제공합니다.
다국어 평가 벤치마크 데이터 세트 : 우리는 26개 언어에 대한 다국어 대형 언어 모델(LLM)을 평가하기 위한 세 가지 벤치마크 데이터 세트를 제공합니다. 여기에서 전체 데이터세트와 평가 스크립트에 액세스할 수 있습니다.
사용 및 라이선스 고지 : Okapi는 연구 용도로만 사용이 허가되었습니다. 데이터 세트는 CC BY NC 4.0(비상업적 사용만 허용)이며 데이터 세트를 사용하여 훈련된 모델은 연구 목적 이외의 용도로 사용해서는 안 됩니다.
평가 결과가 포함된 기술 문서는 여기에서 확인할 수 있습니다.
우리는 다국어 프레임워크 Okapi에 필요한 데이터를 준비하기 위해 포괄적인 데이터 수집 프로세스를 네 가지 주요 단계로 수행합니다.
전체 데이터 세트를 다운로드하려면 다음 스크립트를 사용할 수 있습니다.
bash scripts/download.sh특정 언어에 대한 데이터만 필요한 경우 언어 코드를 스크립트에 대한 인수로 지정할 수 있습니다.
bash scripts/download.sh [LANG]
# For example, to download the dataset for Vietnamese: bash scripts/download.sh vi다운로드 후 공개된 데이터는 데이터 세트 디렉터리에서 찾을 수 있습니다. 여기에는 다음이 포함됩니다.
multilingual-alpaca-52k : Alpaca의 52K 영어 지침을 26개 언어로 번역한 데이터입니다.
multilingual-ranking-data-42k : 26개 언어에 대한 다국어 응답 순위 데이터입니다. 각 언어에 대해 42K 지침을 제공합니다. 각각 4개의 순위 응답이 있습니다. 이 데이터는 26개 언어에 대한 보상 모델을 훈련하는 데 사용될 수 있습니다.
multilingual-rl-tuning-64k : RLHF에 대한 다국어 명령 데이터입니다. 우리는 26개 언어 각각에 대해 62K 지침을 제공합니다.
Okapi 데이터 세트와 RLHF 기반 명령 조정 기술을 사용하여 LLaMA 및 BLOOM의 7B 버전을 기반으로 구축된 26개 언어에 대한 다국어 미세 조정 LLM을 소개합니다. 모델은 여기 HuggingFace에서 얻을 수 있습니다.
Okapi는 26개 언어로 된 다국어 교육 조정 LLM을 통해 대화형 채팅을 지원합니다. 채팅을 위해 다음 단계를 따르세요.
git clone https://github.com/nlp-uoregon/Okapi.git
cd Okapi
pip install -r requirements.txt
from chat import pipeline
model_path = 'uonlp/okapi-vi-bloom'
p = pipeline ( model_path , gpu = True )
instruction = 'Dịch câu sau sang Tiếng Việt' # Translate the following sentence into Vietnamese
prompt_input = 'The City of Eugene - a great city for the arts and outdoors. '
response = p . generate ( instruction = instruction , prompt_input = prompt_input )
print ( response )또한 RLHF를 사용하여 교육 데이터로 LLM을 미세 조정하기 위한 스크립트를 제공하며 감독 미세 조정, 보상 모델링 및 RLHF를 통한 미세 조정이라는 세 가지 주요 단계를 다룹니다. LLM을 미세 조정하려면 다음 단계를 따르세요.
conda create -n okapi python=3.9
conda activate okapi
pip install -r requirements.txtbash scripts/supervised_finetuning.sh [LANG]bash scripts/reward_modeling.sh [LANG]bash scripts/rl_training.sh [LANG]이 저장소의 데이터, 모델 또는 코드를 사용하는 경우 다음을 인용하십시오.
@article { dac2023okapi ,
title = { Okapi: Instruction-tuned Large Language Models in Multiple Languages with Reinforcement Learning from Human Feedback } ,
author = { Dac Lai, Viet and Van Nguyen, Chien and Ngo, Nghia Trung and Nguyen, Thuat and Dernoncourt, Franck and Rossi, Ryan A and Nguyen, Thien Huu } ,
journal = { arXiv e-prints } ,
pages = { arXiv--2307 } ,
year = { 2023 }
}

