중국어-ChatBot/중국어 챗봇
- 작성자가 다음으로 완전히 이전했습니다.
GNN 그래프 신경망 방향 C++ 개발은 더 이상 NLP를 따르지 않으며 프로젝트 코드는 더 이상 유지되지 않습니다. Yuanxiang 프로젝트가 완료되었을 때 온라인 리소스가 거의 없었습니다. 저자는 처음으로 변덕스럽게 NLP와 딥러닝을 접하게 되었고, 마침내 이 장난감 모델을 작성하게 되었습니다. 따라서 저자는 초보자에게는 쉽지 않다는 것을 알고 있으므로 프로젝트가 더 이상 유지 관리되지 않더라도 이슈나 이메일([email protected])에 적시에 응답하여 딥러닝을 처음 시작하는 사람들에게 도움이 되도록 하겠습니다. (내가 사용하는 Tensorflow 버전이 너무 오래되었습니다. 새 버전을 직접 실행하면 확실히 다양한 오류가 발생합니다. 문제가 발생하면 굳이 이전 버전의 환경을 설치하지 마세요. Pytorch를 사용하는 것이 좋습니다. 내 처리 논리에 따라 재구성합니다. 작성하기에는 너무 게으릅니다.
- GNN 측면:
- 일련의 벤치마크 비교 모델: GNNs-Baseline은 아이디어를 빠르게 검증할 수 있도록 조정 및 컴파일되었습니다.
- 내 논문 ACMMM 2023(CCF-A)의 오픈 소스 코드는 여기 LSTGM입니다.
- 내 논문 ICDM 2023(CCF-B)의 오픈 소스 코드는 아직 컴파일 중입니다. . . GRN
- 동료들은 추가하고, 소통하고, 배울 수 있습니다.
환경 구성
| 프로그램 | 버전 |
|---|
| 파이썬 | 3.68 |
| 텐서플로우 | 1.13.1 |
| 케라스 | 2.2.4 |
| 윈도우10 | |
| 주피터 | |
주요 참고 자료
- 논문 "정렬 및 번역 공동 학습에 의한 신경 기계 번역( 다운로드하려면 제목을 클릭하십시오 .)"
- 주의 구조 다이어그램
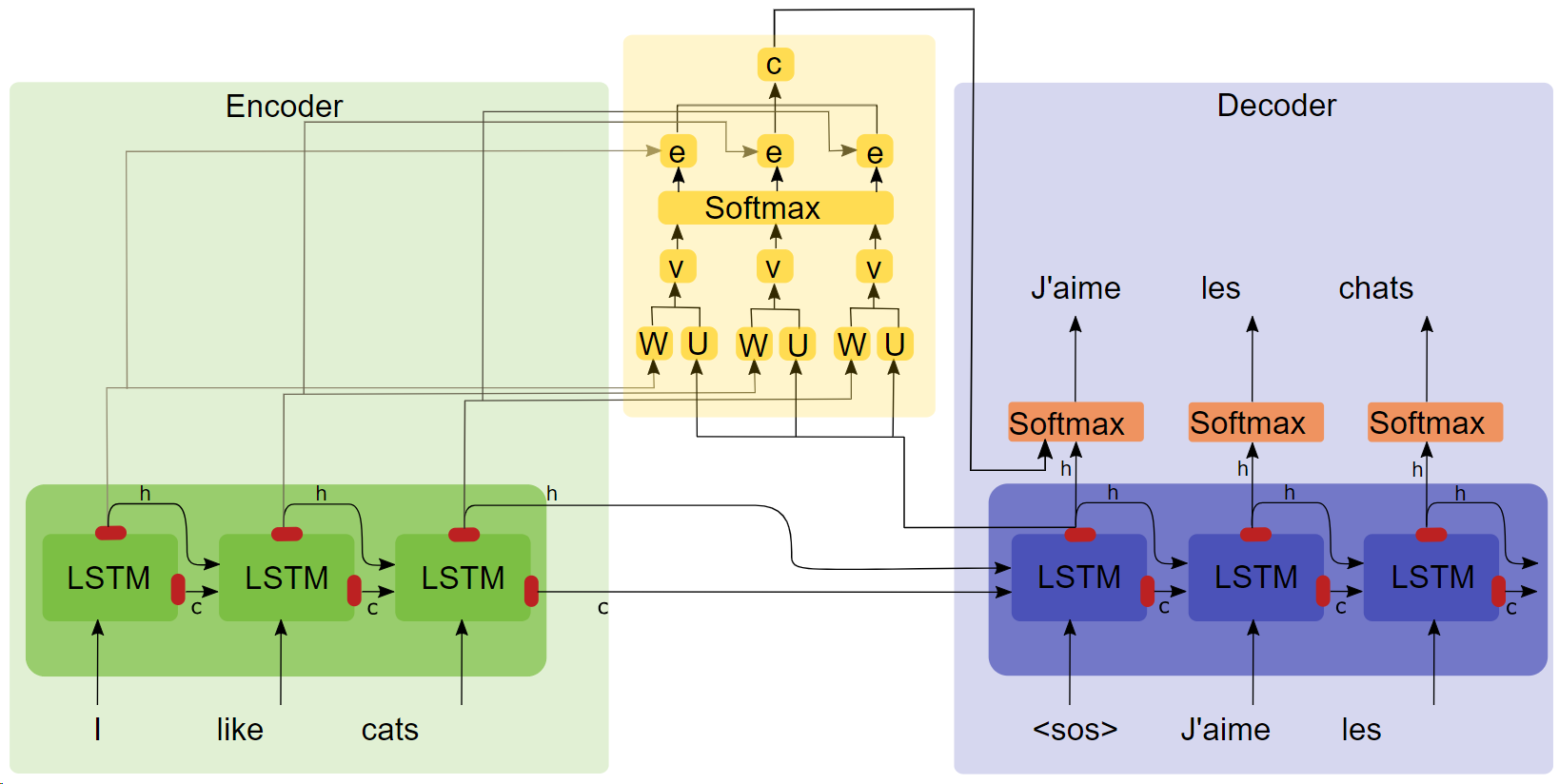
요점
- LSTM
- seq2seq
- 어텐션 실험에서는 어텐션 메커니즘을 추가한 후 훈련 속도가 더 빠르고, 수렴도 더 빠르고, 효과도 더 좋은 것으로 나타났습니다.
코퍼스 및 훈련 환경
Google Colaboratory에서 훈련된 Qingyun 말뭉치의 100,000개 대화 그룹.
달리다
방법 1: 프로세스 완료
- 데이터 전처리
get_data
- 모델 훈련
chatbot_train (Google Colab에 탑재된 버전이므로 로컬 실행 경로를 약간 수정해야 합니다)
- 모델 예측
chatbot_inference_Attention
방법 2: 기존 모델 로드
-
chatbot_inference_Attention 실행
- 로드
models/W--184-0.5949-.h5
인터페이스(Tkinter)
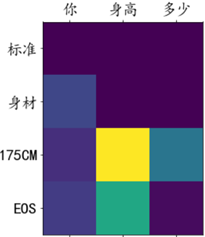
주의 가중치 시각화
다른
- 훈련 파일 chat_bot에서 마지막 3개의 코드 블록 중 처음 2개는 Google Cloud Disk를 마운트하는 데 사용되며, 마지막 블록은 그리기를 용이하게 하기 위해 이러한 손실을 얻는 데 사용됩니다. 콜백 함수에 텐소코드가 왜 있는지 모르겠습니다. 작동하지 않아서 이 전략을 생각해냈습니다.
- 예측 파일의 두 번째 코드 블록에는 텍스트 입력만 있고 인터페이스는 없습니다. 두 블록 중 하나는 필요에 따라 즉시 실행될 수 있습니다.
- 코드에는 중간 출력이 많이 있습니다. 코드를 이해하는 데 도움이 되기를 바랍니다.
- 제가 모델에 학습시킨 모델이 있는데, 평소에는 문제가 없을 것입니다. 직접 학습시킬 수도 있습니다.
- 저자는 능력이 제한되어 있고 대화 효과를 정량화할 수 있는 지표를 찾지 못했기 때문에 손실은 훈련 진행 상황을 대략적으로만 반영할 수 있습니다.


