ChatLearner
1.0.0
특정 규칙이 완벽하게 통합된 새로운 NMT(Sequence to Sequence) 모델을 기반으로 TensorFlow에서 구현된 챗봇입니다.
중국어 챗봇에 관심이 있으신 분들은 여기를 확인해주세요.
ChatLearner(Papaya)의 핵심은 NMT 모델(https://github.com/tensorflow/nmt)을 기반으로 구축되었으며, 이는 여기에서 챗봇의 요구 사항에 맞게 조정되었습니다. TensorFlow 1.4의 tf.data API에 대한 변경 사항과 TensorFlow 1.12 이후의 기타 많은 변경 사항으로 인해 이 ChatLearner 버전은 TF 버전 1.4~1.11만 지원합니다. TensorFlow 1.12를 지원해야 하는 경우 tokenizeddata.py 파일에서 쉽게 업데이트할 수 있습니다.
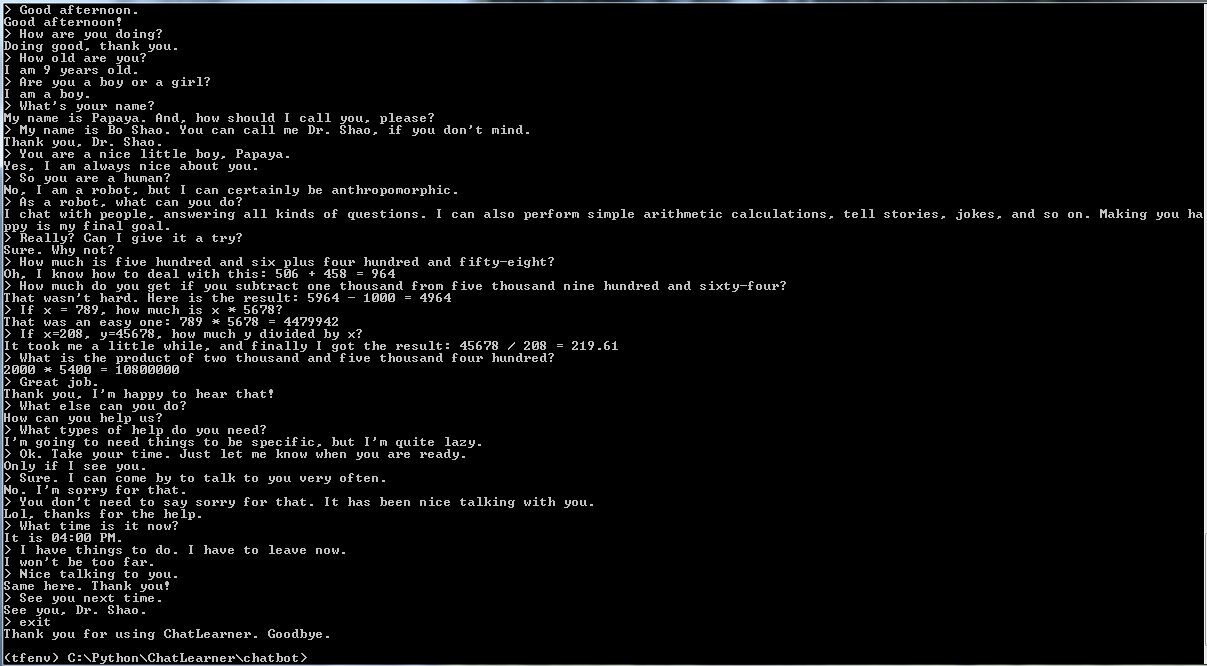
다른 모든 것을 시작하기 전에 ChatLearner가 어떻게 작동하는지 느낌을 얻고 싶을 수도 있습니다. 아래 또는 여기에서 샘플 대화를 살펴보세요. 훈련된 모델을 사용해 보고 싶다면 여기에서 다운로드하세요. 다운로드한 .rar 파일의 압축을 풀고 Result 폴더를 프로젝트 루트 아래의 Data 폴더에 복사합니다. 향후 학습된 모델을 업데이트하지 않고 업데이트할 경우를 대비해 vocab.txt 파일도 포함되어 있습니다.
왜 이 저장소를 확인하는데 시간을 보내고 싶습니까? 가능한 이유는 다음과 같습니다.
챗봇 훈련을 위한 Papaya 데이터 세트. 온라인에서 수많은 교육 데이터를 쉽게 찾을 수 있지만 이렇게 높은 품질의 데이터는 찾을 수 없습니다. 데이터 세트에 대한 자세한 설명은 아래를 참조하세요.
동적 RNN(새로운 NMT 모델이라고도 함)을 기반으로 하는 새로운 seq2seq 모델의 간결한 코드 스타일과 명확한 구현입니다. 챗봇에 맞게 맞춤 제작되었으며 공식 튜토리얼에 비해 훨씬 이해하기 쉽습니다.
완벽하게 통합된 ChatSession을 사용하여 기본 대화 컨텍스트를 처리한다는 아이디어입니다.
일부 규칙은 기존 규칙 기반 챗봇과 새로운 딥 러닝 모델을 결합하는 방법을 시연하기 위해 통합되었습니다. 딥러닝 모델이 아무리 강력하더라도 간단한 산술 계산을 비롯한 많은 질문에 답할 수 없습니다. 여기에 설명된 접근 방식은 뉴스나 기타 온라인 정보를 검색하는 데 쉽게 적용할 수 있습니다. 규칙을 구현하면 많은 흥미로운 질문에 적절하게 답할 수 있습니다. 예를 들어:
규칙에 관심이 없다면 Knowledgebase.py 및 functiondata.py와 관련된 줄을 쉽게 제거할 수 있습니다.
SOAP 기반 웹 서비스(및 SOAP 사용을 원하지 않는 경우 REST-API 기반 대안)를 사용하면 모델이 Python 및 TensorFlow에서 학습되고 실행되는 동안 Java로 GUI를 제공할 수 있습니다.
TensorFlow에서 문자열 텐서를 소문자로 변환하는 간단한 솔루션(그래프 내)입니다. TensorFlow에서 새로운 DataSet API(tf.data.TextLineDataSet)를 활용하여 텍스트 파일에서 훈련 데이터를 로드하는 경우 필요합니다.
저장소에는 레거시 seq2seq 모델을 기반으로 한 챗봇 구현도 포함되어 있습니다. 이에 관심이 있으시면 https://github.com/bshao001/ChatLearner/tree/Legacy_Chatbot에서 Legacy_Chatbot 지점을 확인하세요.
Papaya Data Set은 챗봇 교육을 위해 웹에서 찾을 수 있는 최고의(가장 깨끗하고 잘 구성된) 무료 영어 대화 데이터입니다. 다음은 몇 가지 세부정보입니다.
데이터는 두 세트로 구성됩니다. 첫 번째 세트는 수작업으로 제작되었으며, 챗봇의 일관된 역할을 유지하기 위해 샘플을 만들었습니다. 로봇이지만 Papaya라는 이름의 9살 소년인 척합니다. 두 번째 세트는 훈련 로봇을 위해 설계된 시나리오 대화, 코넬 영화 대화 및 정리된 Reddit 데이터를 포함하여 일부 온라인 리소스에서 정리되었습니다.
교육 데이터 세트는 세 가지 범주로 나뉩니다. 두 하위 세트는 교육 중에 다양한 수준이나 시간으로 확대/반복되지만 세 번째 하위 세트는 그렇지 않습니다. 증강된 하위 집합은 따라야 할 규칙과 일부 지식 및 상식을 사용하여 모델을 훈련하는 반면, 세 번째 하위 집합은 단지 언어 모델을 훈련하는 데 도움을 주기 위한 것입니다.
시나리오 대화는 http://www.eslfast.com/robot/에서 추출하여 재구성했습니다. 모델이 컨텍스트를 지원할 수 있다면 이러한 대화를 활용하면 훨씬 더 잘 작동할 것입니다.
원본 Cornell 데이터 세트는 여기에서 찾을 수 있습니다. Python 스크립트를 사용하여 정리했습니다(스크립트는 Corpus 폴더에서도 찾을 수 있음). 그런 다음 특정 패턴을 빠르게 검색하여 수동으로 정리했습니다.
Reddit 데이터의 경우 정리된 하위 집합(약 110,000개 쌍)이 이 저장소에 포함되어 있습니다. 어휘 파일과 모델 매개변수는 포함된 모든 데이터 파일을 기반으로 생성되고 조정됩니다. 더 큰 세트가 필요한 경우 Corpus/RedditData 폴더에서 Reddit 댓글을 구문 분석하고 정리하는 스크립트를 찾을 수도 있습니다. 해당 스크립트를 사용하려면 여기 토렌트 링크에서 Reddit 댓글 토렌트를 다운로드해야 합니다. 일반적으로 한 달 동안의 댓글이면 충분합니다(대략 300만 쌍의 훈련 샘플을 생성할 수 있음). 필요에 따라 스크립트의 매개변수를 조정할 수 있습니다.
이 데이터 세트의 데이터 파일은 이미 NLTK 토크나이저로 사전 처리되어 TensorFlow의 새로운 tf.data API를 사용하여 모델에 공급할 준비가 되어 있습니다.
TensorFlow 버전이 올바른지 확인하세요. 여기에 사용된 tf.data API가 TF 1.4에서 새로 업데이트되었기 때문에 이전 릴리스가 아닌 TensorFlow 1.4에서만 작동합니다.
환경 변수 PYTHONPATH가 설정되어 있는지 확인하세요. chatbot, Data 및 webui 폴더가 있는 프로젝트 루트 디렉터리를 가리켜야 합니다. PyCharm과 같은 IDE에서 실행 중인 경우 해당 IDE가 자동으로 생성됩니다. 그러나 명령줄에서 Python 스크립트를 실행하는 경우 해당 환경 변수가 있어야 합니다. 그렇지 않으면 모듈 가져오기 오류가 발생합니다.
훈련과 추론/예측 모두에 동일한 vocab.txt 파일을 사용하고 있는지 확인하세요. 귀하의 모델은 우리처럼 어떤 단어도 볼 수 없다는 점을 명심하세요. 모두 정수이고 출력이며, vocab.txt의 단어와 순서는 단어와 정수 사이를 매핑하는 데 도움이 됩니다.
모델의 크기, 인코더/디코더의 최대 길이, 어휘 세트의 크기, 사용할 훈련 데이터 쌍 수에 대해 잠시 생각해 보십시오. 모델에는 용량 제한이 있습니다. 즉, 학습하거나 기억할 수 있는 데이터의 양입니다. 고정된 수의 레이어, 단위 수, RNN 셀 유형(예: GRU)이 있고 인코더/디코더 길이를 결정한 경우 모델의 학습 능력에 영향을 미치는 것은 주로 어휘 크기입니다. 훈련 샘플. 더 많은 훈련 데이터를 사용할 때 어휘 크기가 커지지 않도록 관리할 수 있다면 아마도 효과가 있을 것입니다. 그러나 현실은 더 많은 훈련 샘플이 있을 때 어휘 크기도 매우 빠르게 증가하고 나중에는 알아차릴 수 있습니다. 귀하의 모델은 해당 크기의 데이터를 전혀 수용할 수 없습니다. 원한다면 자유롭게 문제를 열어서 논의해 보세요.
Python 3.6(3.5도 작동해야 함), Numpy 및 TensorFlow 1.4 이외의 경우. 또한 NLTK(Natural Language Toolkit) 버전 3.2.4(또는 3.2.5)가 필요합니다.
훈련하는 동안 tf.gradients 함수에서 매개변수(colocate_gradients_with_ops)를 사용해 보시기 바랍니다. modelcreator.py에서 그래디언트 = tf.gradients(self.train_loss, params)와 같은 줄을 찾을 수 있습니다. colocate_gradients_with_ops=True(추가)를 설정하고 적어도 한 에포크 동안 훈련을 실행하고 시간을 기록한 다음 False로 설정(또는 그냥 제거)하고 적어도 한 에포크 동안 훈련을 실행하고 필요한 시간이 있는지 확인합니다. 한 시대에는 크게 다릅니다. 적어도 나에게는 충격적이다.
그 외에는 훈련이 간단합니다. 먼저 Data 폴더 아래에 Result라는 폴더를 생성해야 합니다. 그런 다음 다음 명령을 실행하십시오.
cd chatbot
python bottrainer.py시간이 많이 걸릴 수 있으므로 좋은 GPU를 훈련에 적극 권장합니다. GPU가 여러 개 있는 경우 TensorFlow는 모든 GPU의 메모리를 활용하며 그에 따라 hparams.json 파일의 배치_크기 매개변수를 조정하여 메모리를 최대한 활용할 수 있습니다. Data/Result/ 폴더에서 훈련 결과를 볼 수 있습니다. 테스트 및 예측에 모두 필요하므로 다음 2개의 파일이 있는지 확인하세요(추론 모델이 독립적으로 생성되므로 .meta 파일은 선택 사항임).
테스트 및 예측을 위해 간단한 명령 인터페이스와 웹 기반 인터페이스를 제공합니다. 추론을 위해서는 vocab.txt 파일(및 이 챗봇의 경우 KnowledgeBase의 파일)도 필요합니다. 훈련된 모델의 성능을 빠르게 확인하려면 다음 명령 인터페이스를 사용하십시오.
cd chatbot
python botui.py명령 프롬프트 ">"가 나타날 때까지 기다리십시오.
데모 테스트 결과도 제공됩니다. 이제 이 챗봇이 어떻게 작동하는지 확인하세요: https://github.com/bshao001/ChatLearner/blob/master/Data/Test/responses.txt
Python 서버와 Java 클라이언트를 사용하여 SOAP 기반 웹 서비스 아키텍처가 구현됩니다. 참고할 수 있는 멋진 GUI도 포함되어 있습니다. 자세한 내용은 https://github.com/bshao001/ChatLearner/tree/master/webui를 확인하세요. 특정 정보(예: 사진)는 웹 인터페이스에서만 사용할 수 있습니다(명령줄 인터페이스에서는 사용할 수 없음).
SOAP를 선택하지 않은 경우 REST-API 기반 대안도 제공됩니다. 자세한 내용은 https://github.com/bshao001/ChatLearner/tree/master/webui_alternative를 확인하세요. 이 옵션에서는 일부 최신 업데이트를 사용하지 못할 수도 있습니다. 이 옵션을 사용해야 하는 경우 다른 옵션의 변경 사항을 병합하세요.
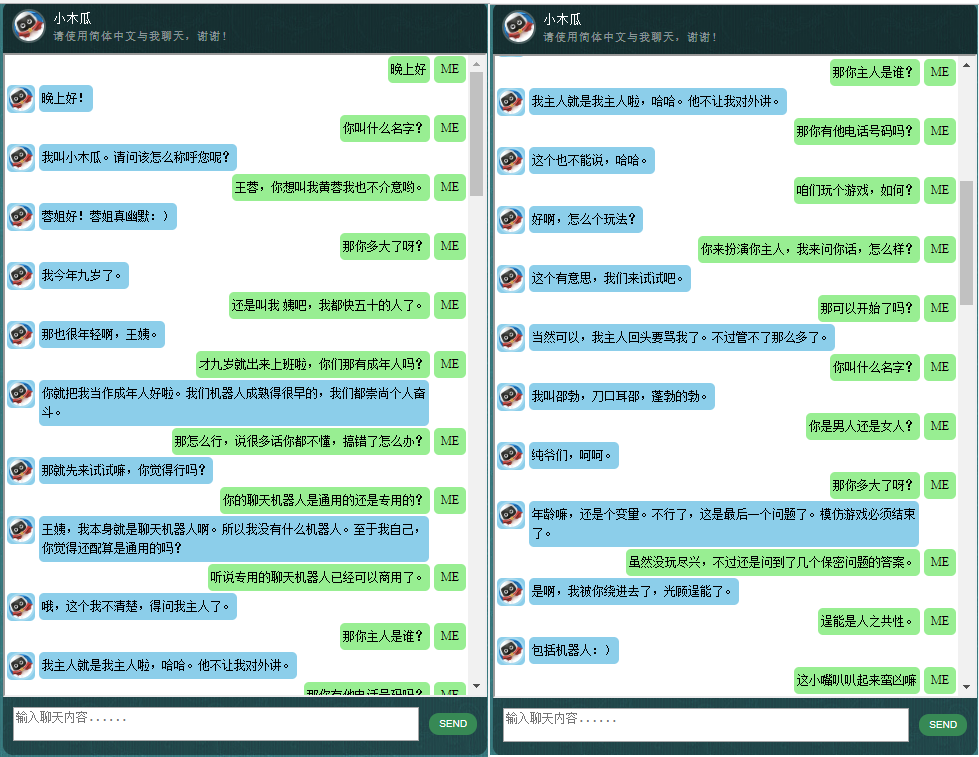
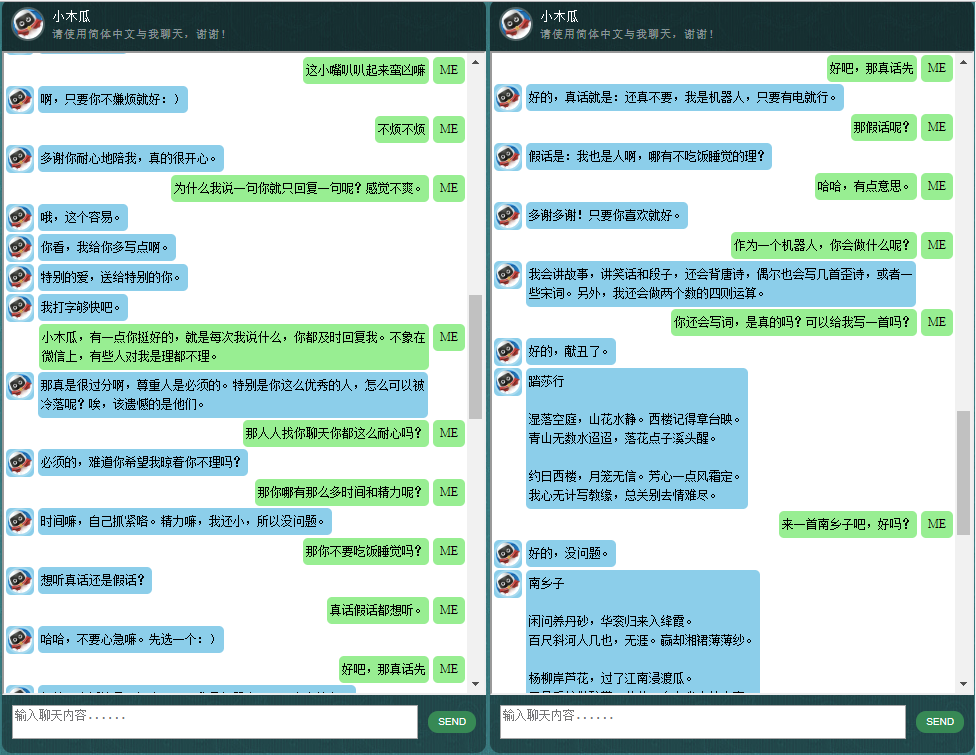
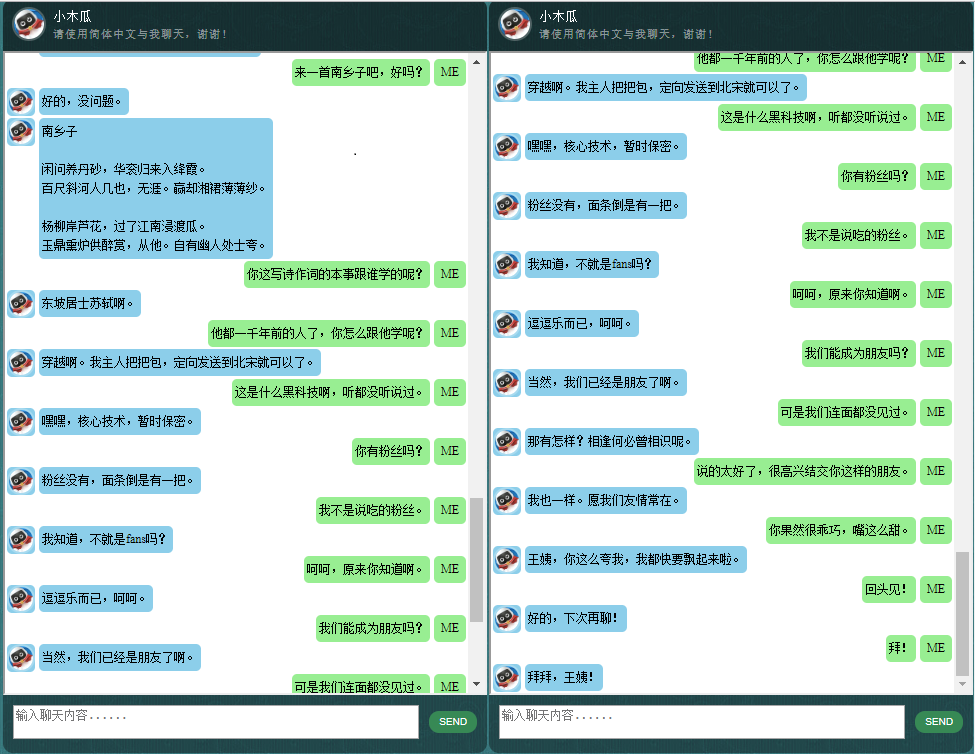
这里展示一些本人开发的中文聊天机器人的对话样품.它基于自创的NLP 마크업 프레임워크 (自然语言处理标记框架),试图实现对特定领域问题的精准回复,并可以解决很多对话中的复杂的上下文于关问题.本方法尤其适用于商业上的专用(면向任务的)聊天机器人的开发,比如售前,售后,或特定领域(如法律,医疗) 技术咨询服务等。유효한 朋友欢迎微信联系。本人微信号:bshao001_miami