Dialog
1.0.0
Dialog는 일본의 챗봇 프로젝트입니다.
본 프로젝트에서 사용된 아키텍처는 BERT Encoder와 Transformer Decoder를 포함하는 EncoderDecoder 모델입니다.
일본어로 작성된 기사입니다.
환경을 구축하지 않고도 Google Colab에서 교육 및 평가 스크립트를 실행할 수 있습니다.
다음 링크를 클릭해 주세요.
교육용 노트북에서는 다운로드 명령이 노트 끝 부분에 설명되어 있지만 아직 테스트되지 않았습니다. 따라서 훈련 노트북을 실행했는데 훈련된 가중치 파일을 다운로드할 수 없는 경우 수동으로 다운로드하십시오.
일본어로 작성된 블로그
@ycat3은 문장 생성을 위해 이 프로젝트를 사용하고 음성 합성을 위해 Parallel Wavenet을 사용하여 텍스트 음성 변환 예제를 만들었습니다. 소스코드는 공유되지 않으나 Parallel Wavenet을 활용하시면 재현이 가능합니다. 해당 블로그에는 일부 오디오 샘플이 있으므로 들어보시기 바랍니다.
시간이 많으면 음성합성, 음성인식을 활용해 AI와 음성으로 대화할 수 있는 앱을 만들고 싶은데 지금은 시험 준비 때문에 못 하고 있어요...
2세대
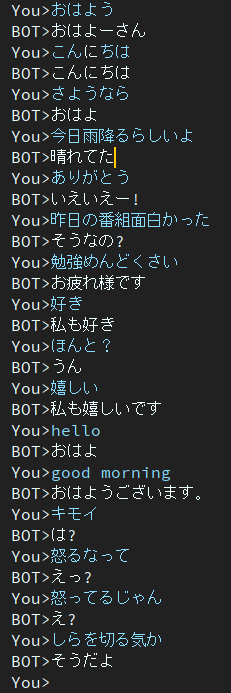
이 모델에는 여전히 반응이 둔하다는 문제가 남아 있습니다.
이 문제를 해결하기 위해 지금 연구 중입니다.
그러다가 이 문제를 다룬 논문을 발견했습니다.
신경 대화 생성을 위한 또 다른 다양성 촉진 목적 함수
저자는 Nara Institute of Science and Technology(NAIST) 소속입니다.
그들은 신경 대화 생성의 새로운 목적 기능을 제안합니다.
이 방법이 해당 문제를 해결하는 데 도움이 되기를 바랍니다.
구글 드라이브에.
필요한 패키지는
패키지로 인해 오류가 발생하는 경우 누락된 패키지를 설치하시기 바랍니다.
conda를 사용하는 경우의 예입니다.
# create new environment
$ conda create -n dialog python=3.7
# activate new environment
$ activate dialog
# install pytorch
$ conda install pytorch torchvision cudatoolkit={YOUR_VERSION} -c pytorch
# install rest of depending package except for MeCab
$ pip install transformers tqdm neologdn emoji
# #### Already installed MeCab #####
# ## Ubuntu ###
$ pip install mecab-python3
# ## Windows ###
# check that "path/to/MeCab/bin" are added to system envrionment variable
$ pip install mecab-python-windows
# #### Not Installed MeCab #####
# install Mecab in accordance with your OS.
# method described in below is one of the way,
# so you can use your way if you'll be able to use transformers.BertJapaneseTokenizer.
# ## Ubuntu ###
# if you've not installed MeCab, please execute following comannds.
$ apt install aptitude
$ aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -y
$ pip install mecab-python3
# ## Windows ###
# Install MeCab from https://github.com/ikegami-yukino/mecab/releases/tag/v0.996
# and add "path/to/Mecab/bin" to system environment variable.
# then run the following command.
$ pip install mecab-python-windows # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_training_data'훈련을 시작할 준비가 되었다면 기본 스크립트를 실행하세요.
$ python main.py # in config.py, line 24
# default value is './data'
data_dir = 'path/to/dir_contains_pretrained'$ python run_eval.py더 많은 대화 데이터를 얻으려면 get_tweet.py를 사용하세요.
이 스크립트를 사용하려면 Consumer_key와 access_token을 변경해야 합니다.
그런 다음 다음 명령을 실행하십시오.
# usage
$ python get_tweet.py " query " " Num of continuous utterances "
# Example
# This command works until occurs errors
# and makes a file named "tweet_data_私は_5.txt" in "./data"
$ python get_tweet.py 私は 5예제 명령을 실행하면 스크립트는 마지막 문장에 "私は"가 포함되어 있으면 연속 5개의 문장을 수집하기 시작합니다.
그러나 3개 이상의 숫자를 "연속 발화"로 설정하면 make_training_data.py가 자동으로 발화 쌍을 생성합니다.
그런 다음 다음 명령을 실행하십시오.
$ python make_training_data.py이름처럼 './data/tweet_data_*.txt'를 사용하여 학습 데이터를 만드는 스크립트입니다.
인코더: BERT
디코더: 바닐라 트랜스포머의 디코더
손실: 크로스엔트로피
최적화: AdamW
토크나이저: Bert일본어토크나이저
BERT 또는 Transformer의 아키텍처에 대한 자세한 내용을 알고 싶다면 다음 기사를 참조하세요.


